









论文题目:利用注意模块减少x射线CT的刚性和非刚性运动伪影
论文地址:ELSEVIER
CT 运动伪影去除
摘要:
运动伪影是影响计算机断层扫描(CT)图像诊断性能的主要因素。特别是,当成像系统需要较长的扫描时间时,例如牙科CT或锥束CT (CBCT)应用中,患者会产生刚性和非刚性运动,运动伪影变得相当严重。为了解决这个问题,
我们提出了一种新的实时运动伪影减少技术,该技术利用带有注意力模块的深度残差网络。我们的注意力模块是根据残差特征的重要性,通过放大或衰减残差特征来增加模型容量的。我们通过在步进射击扇束CT (FBCT)或CBCT下创建四个具有刚性运动或刚性和非刚性运动的基准数据集来训练和评估网络。每个数据集提供了一组运动损坏的CT图像及其基真CT图像对。
所提出的网络模型强大的建模能力使我们能够成功地实时处理两个CT系统在各种运动场景下的运动伪影。因此,所提出的模型显示出明显的性能优势。此外,我们还将我们的模型与Wasserstein生成对抗网络(WGAN)模型和基于深度残差网络(DRN)的模型进行了比较,这两种模型分别是CT去噪和自然RGB图像去模糊的最强大技术之一。基于使用四个基准数据集的广泛分析和比较,我们确认我们的模型优于上述竞争对手。我们的基准数据集和实现代码可在github上获得。
本文先看论文,之后会有代码复现或者讲解
还是尽量能概括的就一句话,方便大家阅读
1. Introduction
在x射线计算机断层扫描(CT)中,运动伪影包括由患者运动引起的所有类型的图像退化,影响诊断。
现有技术大致可分为三类:1)快速扫描;2)基于患者运动估计的运动补偿;3)基于图像的运动伪影补偿。
1)运动不可避免 ,2)存在硬件要求,运行慢,需要原始数据问题 ,3)局限于受限的运动场景(即只处理刚性头部运动和心脏运动)
在这项工作中,我们提出了一种基于图像的方法,该方法普遍适用于各种CT系统,包括刚性和非刚性运动。
为此,我们提出了一个强大的深度卷积神经网络框架来补偿CT运动伪影。特别是,我们开发了由自注意机制驱动的深度卷积残差网络。值得强调的是,我们首次在CT运动补偿任务中引入了注意机制。使用深度神经网络的基本原理如下。在患者运动的情况下,多个组织被混合并记录到单个检测器像素中,导致非平稳图像模糊。因此,运动伪影表现出高度非线性的特征。由于CNN已经成功地用于建模非线性和复杂的决策任务,我们决定采用CNN来完成我们的任务。
DRN (He et al., 2016)可以通过引入身份映射的概念成功地解决CNN梯度消失或爆炸问题,因此选用DRN,然后引入注意力
2. 基于注意的运动补偿
使用深度神经网络(DNN)模型来补偿CT图像中的运动伪影。
我们重点对CT运动伪影进行了校正。为此,我们开发了一个由残余构建块(ResBlock)和自关注模块(AttBlock)组成的网络架构,称为注意力块(AttBlock)。此外,有效的目标函数提高了在各种运动场景下运动伪影还原的质量。
2.1. Residual block
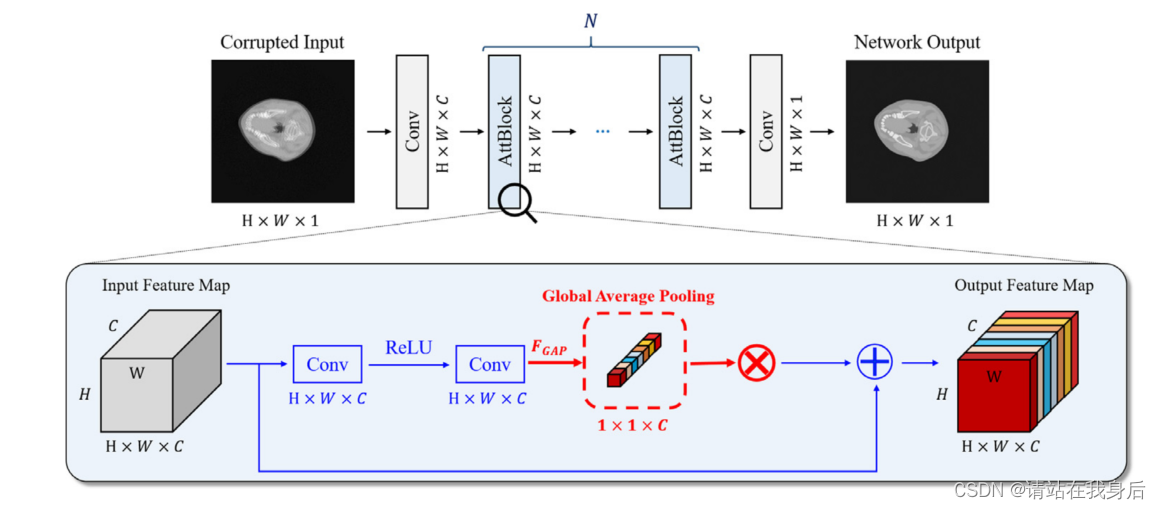
放大框中显示了AttBlock的结构,其中Res结构用蓝色标记,自关注模块用红色粗体标记。注意,AttBlock从残差部分计算注意力模块,并在身份映射之前将它们相乘。
2.2. Attention block
注意力模块通过给特征分配不同的权重来提高网络的建模能力。注意模块的工作原理如下:
这是一个注意力模块的输出特征映射,是一个元素矩阵乘法。
在本研究中,我们研究了五个注意模块:卷积块注意模块(CBAM)的全局平均池化(GAP)、挤压和激发(SE) (Hu等人,2018b)、通道(CA)和空间注意(SA)子模块(Woo等人,2018)和CBAM。请注意,AttBlock可以采用这五个模块中的一个或组合
2.2.1. Global average pooling (GAP)
GAP是最简单的channel-wise attention,第c通道的统计量如下:
U_c为输入特征图的C-th特征
2.2.2. Squeeze-and-excitation (SE)
SE通过两个完全连接(FC)层和两个激活函数学习通道之间的非线性和非互斥相互关系:
FC代表ReLU
2.2.3. Channel attention (CA)
CA作为CBAM的信道子模块。CA不是单独使用GAP,而是使用全局最大池化(GMP),它返回输入特征映射的通道最大值如下:
等式中的两个池输出。将(2)和(4)转发给一个共享的多层感知机(MLP),然后计算其最终关注值如下:
2.2.4. Spatial attention (SA)
SA是CBAM的空间子模块,它按照像素依赖关系对重要性进行编码。也就是说,它关注的是输入特征映射的空间关系。首先,通道信息通过两个空间池化操作进行聚合:
然后将它们连接起来,经过卷积层和s形激活,计算SA, FSA∈RH×W×1,如下所示:
2.2.5. Convolutional block attention module (CBAM)
CBAM在方程中聚合了通道和空间注意模块。(5)、(8),并返回输出特征图如下:
2.3. Network architectures
在所有实验中堆叠了10个attblock。A所有块具有相同的特征维数(C)为64。为了调整尺寸,在块的前面和后面各有一个卷积层。第一个卷积层将单通道模糊的二维输入图像(H × W × 1)转换成C通道尺寸的特征图(H × W × C),最后一个卷积层将最后一个块生成的特征图转换成运动补偿的二维输出图像。
2.4. Objective function
该模型的目标函数必须同时实现两个目标:补偿CT图像中的运动畸变和保留其原始结构。为了实现这些目标,我们通过结合两个流行的损失项:平均绝对误差(MAE)和感知损失来设计目标函数。
实验就不看了,网络结构太简单了,我先去复现看下效果
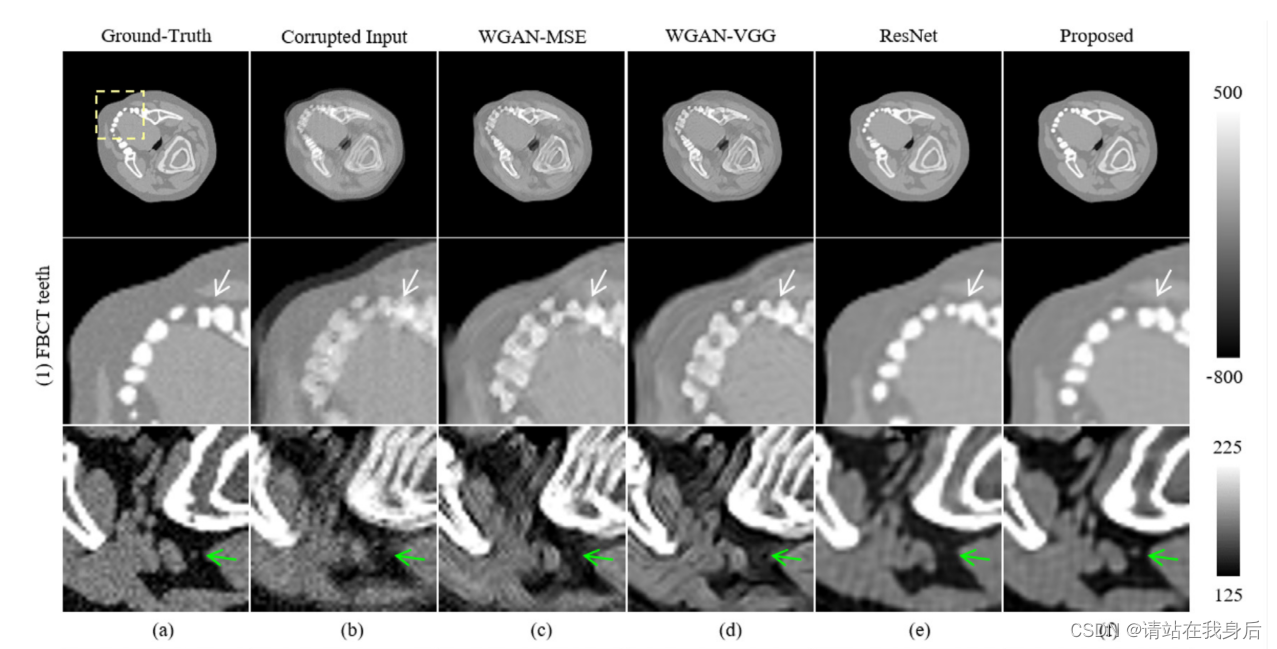
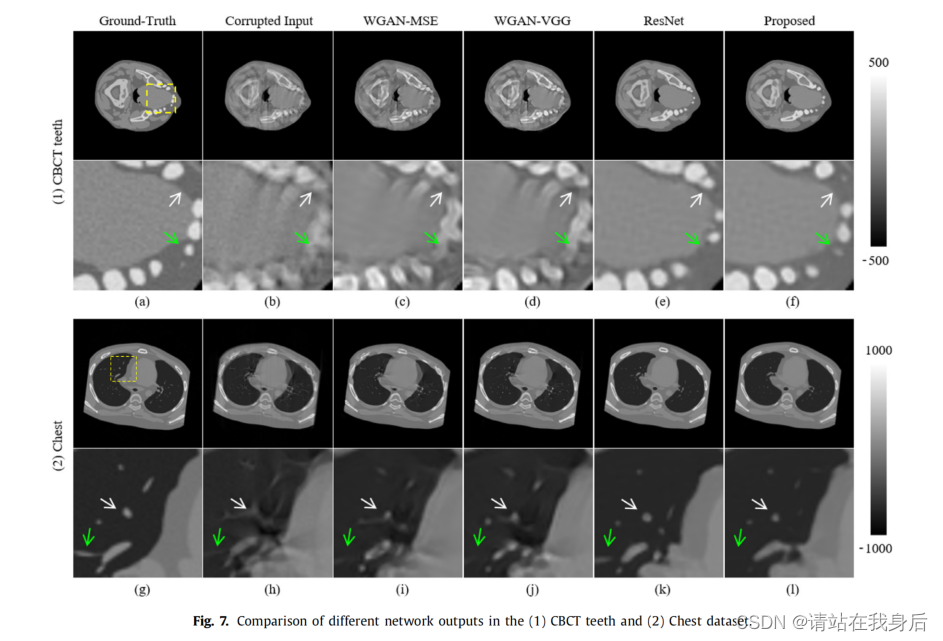

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











