







0 Summary:
Title: Multi-Behavior Sequential Recommendation with Temporal Graph Transformer
Publisher: IEEE Transactions on Knowledge and Data Engineering 2022 -5
工程技术 2 区
论文链接:https://arxiv.org/pdf/2206.02687.pdf
Abstract:
顺序推荐从历史的交互中学习用户的动态兴趣来推荐商品,但现有的推荐都只关注单一类型的用户-物品交互上。但现实中的交互总是多类型,且交叉影响的。
在这项工作中,我们处理动态用户-物品关系学习与多行为交互模式的感知能力,提出了一个 Temporal Graph Transformer (TGT)来联合捕获动态的短期和长期用户物品交互模式。
文章目录
1 简介
目前大多数框架都是为单一的行为类型设计的。在实践中,根据不同的上下文,用户-项目交互的意图可以随着时间的推移而改变。
考虑在知识推荐上的应用,用户会大量查看与兴趣相关的论文,如果用户喜欢,可以点开论文详情查看并添加为“喜欢”,如果到达要求,则会进行最终的收藏或者下载。
因此,用户与论文的交互往往具有时间依赖性和行为多样性。为了向用户推荐相关知识,不仅要了解他/她以前下载过什么,而且要了解这个用户以前看过什么论文,或者把它们标记为他/她喜欢的论文。
为实现目标,存在两个挑战:
1)跨类别行为项目依赖 不同类型的交互之间存在依赖关系,如果分散的将行为作为特征嵌入来进行学习,就很难捕捉到各种交互行为类型之间复杂的相互依赖关系
2)时间多行为模式融合 在实际应用中,由于用户在不同的时间戳上的特质,用户经常会以各种内在关联的行为与物品进行交互。因此,需要联合提取行为异质性和潜在的类型依赖模式。
对此,提出了本文的TGT,为了捕捉用户的短期多类型交互模式,提出一个基于行为感知的transformer网络,将行为异构信号注入到物品转换的序列建模中。
为了利用长期的多行为依赖关系,我们提出了一个时间图神经网络,从用户对任意持续时间项的多样化活动推断潜在用户表示。
在TGT中,我们在时间感知的用户-物品交互图上递归地细化全局级别的表示,以捕获不同用户之间的动态交叉序列相关性。
贡献
1)本研究从短期和长期两方面探讨了用户的多行为特征,从而解决了多行为顺序推荐问题。
2)在TGT中,我们沿着时间维度调整图神经网络以捕获多行为交互模式的动态。
2 相关工作
顺序推荐系统:目前大多模型只考虑单一类型的序列行为。考虑到用户交互的条目序列,如何有效利用动态多行为知识来提高推荐精度仍然是一个重大的挑战。
图神经网络推荐:TGT框架建立在动态图神经体系结构上,以捕获高阶连接,并探索进化的多行为偏好。
异构关系推荐:本研究着重挖掘多行为交互数据的动态特征,验证其在顺序推荐中的积极作用
多行为推荐系统:现有的解耦表示方法大多是在假定隐因素独立的前提下进行嵌入分离。与它们不同的是,这项工作以一种明确的方式利用了不同类型的行为交互模式之间的动态依赖性。
3 模型
3.1 任务描述
本文中U表示用户的集合,V表示项目的集合,B表示不同交互行为的类型
多行为交互序列 :表示时间t时第b种行为类型下的第k个交互项(按时间排序)
S
i
=
(
v
k
,
i
,
b
,
t
)
S_i = (v_{k,i},b,t)
Si=(vk,i,b,t)
在我们的多行为顺序推荐问题中,我们将目标预测的行为类型定义为目标行为(例如,在网上零售平台购买)。其他类型的用户行为(例如,页面视图,标签收藏)被认为是上下文行为,用于表征用户对目标行为的偏好。
项目旨在预测交互序列S后用户所感兴趣的项目
输入:每个用户过去多行为交互的物品序列S
输出:一个学习函数,可以准确预测t时间之后每个用户的交互项目。
3.2 架构总览
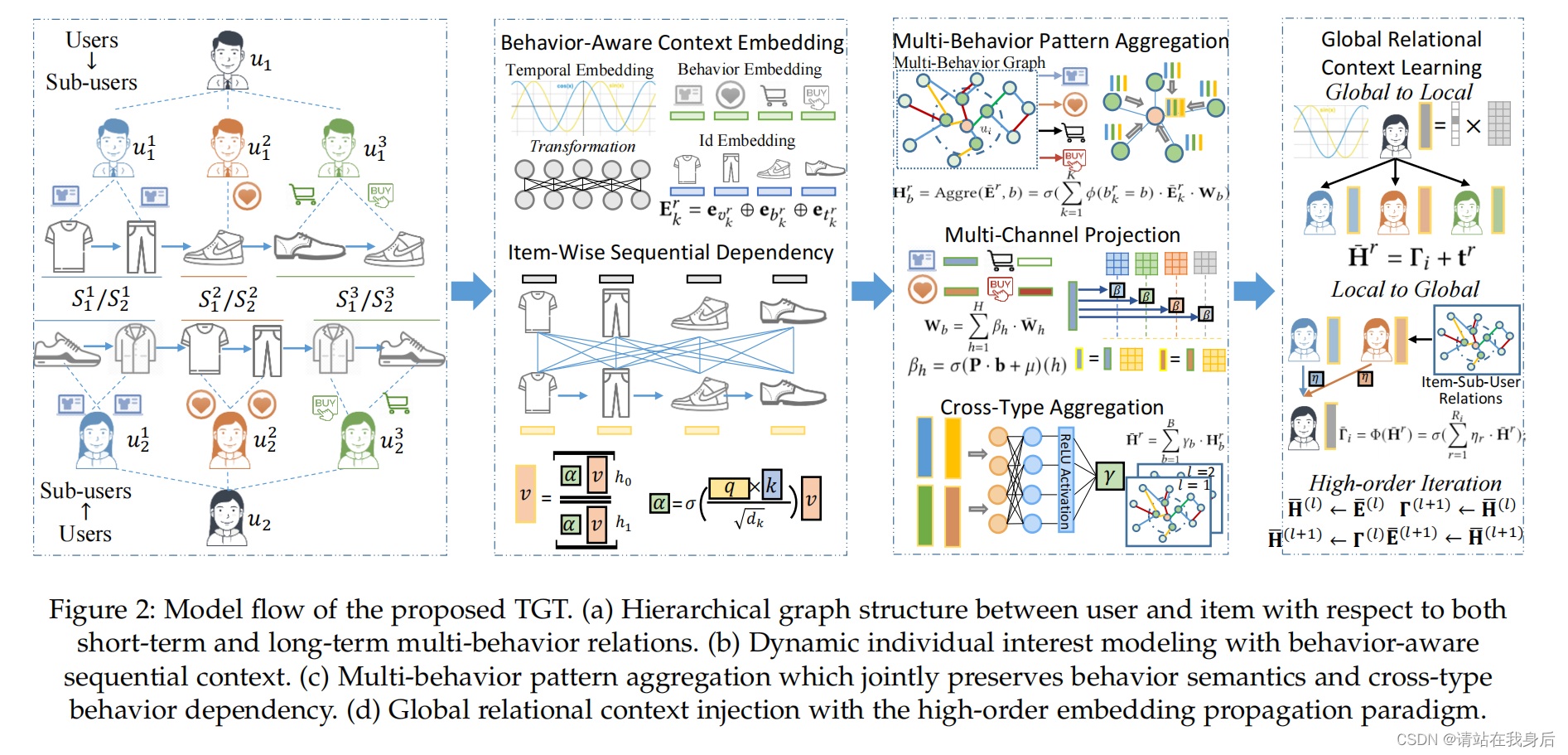
为了在用户-物品交互中捕获行为感知的顺序依赖,我们设计了一个整合的关系学习框架,该框架包含一个行为感知的上下文嵌入模块和一个逐项目的顺序依赖编码器。该组件能够在保留多行为上下文信号的情况下对用户的时间交互模式进行建模。
提出了多行为模式聚合组件,用于捕获短期用户偏好,而非行为感知子交互。在这个模块中,时间感知的用户-项目交互模式由dual-stage行为感知消息传递范式编码,用于嵌入传播和细化。
最后,引入全局语境学习组件,使我们的TGT具有将长期多行为模式的能力。通过递归嵌入传播,短期和长期特定于行为的交互模式都保留在用户/物品的学习表征中。
3.3 动态个性化建模
我们开发了一个 multi-behavior transformer network来提取短期行为动态。将序列S分解为R细粒度,来对用户短期偏好建模
3.3.1 Behavior-aware Context Embedding Layer
设计了一个嵌入层将多行为上下文信号和时间信号联合注入到项目表示,遵循主流推荐范例,首先用id对应的嵌入e_v描述单个项v。然后对用户行为进行区分,行为类型嵌入e_b,对应用户-物品交互的第b类。此外,为了获取行为的动态,我们通过引入时间编码策略来增强上下文嵌入层。
受Transformer[39]中位置嵌入方法的启发,我们采用时间戳信息上的正弦函数来产生基准时间嵌入
t
k
r
,
(
2
l
)
=
s
i
n
(
τ
(
t
k
r
)
1000
0
2
l
d
)
/
d
t
k
r
,
(
2
l
+
1
)
=
c
o
s
(
τ
(
t
k
r
)
1000
0
2
l
+
1
d
)
/
d
e
t
k
r
=
t
k
r
⋅
W
t
E
k
r
=
e
v
k
r
⊕
e
b
k
r
⊕
e
t
k
r
为习得的上下文感知项目嵌入
t_k^{r,(2l)} = sin (\frac{\tau (t^r_k)}{10000^{\frac {2l}d}} )/\sqrt d\\ t_k^{r,(2l+1)} = cos (\frac{\tau (t^r_k)}{10000^{\frac {2l+1}d}} )/\sqrt d\\ e_{t^r_k} = t^r_k \cdot W^t\\ E^r_k = e_{v^r_k} \oplus e_{b^r_k} \oplus e_{t^r_k} 为习得的上下文感知项目嵌入
tkr,(2l)=sin(10000d2lτ(tkr))/dtkr,(2l+1)=cos(10000d2l+1τ(tkr))/detkr=tkr⋅WtEkr=evkr⊕ebkr⊕etkr为习得的上下文感知项目嵌入
3.3.2 逐项目的顺序依赖编码器
为了捕捉不同项目之间短期过渡的动态,该模块建立在transformer上,基于多头表示空间下的自我注意机制,项目间的相互关系通过多头点乘注意力学习
E
‾
k
r
=
∣
∣
h
=
1
H
∑
k
′
=
1
K
α
k
,
k
′
V
h
E
k
′
r
α
k
,
k
′
=
σ
(
(
Q
h
E
k
r
)
T
(
K
h
E
k
′
r
)
d
/
H
)
α
为已学习的相关分数;
σ
为
s
o
f
t
m
a
x
函数;
E
‾
k
r
细化项表示
H
表语义空间;
∣
∣
表向量叠加
\overline E^r_k = || ^H _{h=1} \sum \limits ^K_{k^\prime = 1}\alpha _{k,k^\prime} V^h E^r_{k^\prime}\\ \alpha_{k,k^\prime} = \sigma(\frac {(Q^hE^r_k)^T(K^hE^r_{k^\prime})}{\sqrt{d/H}})\\ \alpha 为已学习的相关分数;\sigma为softmax 函数;\overline E^r_k 细化项表示\\ H 表语义空间;||表向量叠加
Ekr=∣∣h=1Hk′=1∑Kαk,k′VhEk′rαk,k′=σ(d/H(QhEkr)T(KhEk′r))α为已学习的相关分数;σ为softmax函数;Ekr细化项表示H表语义空间;∣∣表向量叠加
通过整合上下文嵌入层和逐项依赖编码器,我们的TGT不仅保留了跨项目的过渡关系,而且捕获了多行为动态。
3.4 多行为模式聚合
本节通过对时间感知的交互建模来执行多行为模式聚合,需要构建二部图
G
r
=
{
u
i
r
∪
S
i
,
r
,
E
r
}
E
为交互,
u
为中间顶点
G_r = \{ u_i^r \cup S_{i,r},E_r \} E为交互,u为中间顶点
Gr={uir∪Si,r,Er}E为交互,u为中间顶点
为了捕获短期行为异质性,我们设计了一个行为感知的消息传递方案,以区分和聚合不同行为类型的交互模式,范式由两阶段,包括从用户到项目的传递和细化嵌入,反之亦然。从项目传递到用户端的消息可以用如下形式表示:
H
b
r
=
A
g
g
r
e
(
E
‾
r
,
b
)
=
σ
(
∑
k
=
1
K
ϕ
(
b
k
r
=
b
)
⋅
E
‾
k
r
⋅
W
b
)
H
b
r
表示在第
b
个行为类型下生成的节点
u
i
r
嵌入
σ
为
R
E
L
U
激活函数
;
b
k
r
=
b
时
ϕ
=
1
H^r_b = Aggre(\overline E^r,b)=\sigma(\sum \limits ^K_{k=1} \phi(b_k^r = b)\cdot \overline E^r_k \cdot W_b)\\ H^r_b 表示在第b个行为类型下生成的节点u^r_i嵌入\\ \sigma 为RELU激活函数; b^r_k = b时 \phi = 1
Hbr=Aggre(Er,b)=σ(k=1∑Kϕ(bkr=b)⋅Ekr⋅Wb)Hbr表示在第b个行为类型下生成的节点uir嵌入σ为RELU激活函数;bkr=b时ϕ=1
3.4.1 多通道投影系统
为了在消息传递过程中有效地区分多种类型的交互,我们采用多通道参数学习策略来计算transformation W_b
W
b
=
∑
h
=
1
H
β
h
⋅
W
‾
h
;
β
h
=
σ
(
P
⋅
b
+
μ
)
(
h
)
W_b = \sum \limits ^H_{h=1}\beta_h \cdot \overline W_h; \\ \beta_h = \sigma(P \cdot b +\mu)(h)
Wb=h=1∑Hβh⋅Wh;βh=σ(P⋅b+μ)(h)
多通道投影旨在区分信息在时间传递过程中的多关系交互。在多个base transformations,上的行为嵌入投影之后,使用基于通道的聚合层对行为感知语义进行编码,这使我们的TGT方法能够保留不同类型用户的固有行为语义
3.4.2 跨类型关系的聚合
在编码特定于类型的行为语义之后,下一步是将行为感知嵌入到聚合层中,以揭示不同类型行为模式之间的隐式关系。将学习场景与动态用户偏好相结合,提出了一种自适应注意网络,以区分不同行为类型对预测目标行为的影响
H
‾
r
=
∑
b
=
1
B
τ
b
⋅
H
b
r
τ
b
=
σ
1
(
H
b
r
T
⋅
σ
2
(
∑
b
=
1
B
H
b
r
W
A
+
μ
A
)
)
W
为
t
r
a
n
s
f
o
r
m
a
t
i
o
n
,
μ
为聚合层偏差
\overline H^r = \sum \limits ^B_{b=1} \tau _b \cdot H_b^r\\ \tau_b = \sigma_1 (H_b^{rT}\cdot \sigma_2 ( \sum \limits ^B_{b=1} H_b^r W_A +\mu_A)) \\W为transformation,\mu为聚合层偏差
Hr=b=1∑Bτb⋅Hbrτb=σ1(HbrT⋅σ2(b=1∑BHbrWA+μA))W为transformation,μ为聚合层偏差
γ是第b类行为的学习注意权重,因此,我们显式地在用户表示H中保留了可感知时间的多行为上下文信息
为了对时间感知用户对不同物品的影响进行建模,我们执行了从用户到物品的消息传递
E
‾
j
b
=
σ
(
∑
v
k
r
=
j
ϕ
(
b
k
r
=
b
)
⋅
H
‾
r
⋅
W
b
)
E
‾
j
=
∑
b
=
1
V
τ
b
⋅
E
‾
j
,
b
\overline E_j^b = \sigma(\sum \limits _{v^r_k = j }\phi(b_k^r = b)\cdot\overline H^r\cdot W_b)\\ \overline E_j = \sum\limits ^V_{b=1}\tau_b \cdot \overline E_{j,b}
Ejb=σ(vkr=j∑ϕ(bkr=b)⋅Hr⋅Wb)Ej=b=1∑Vτb⋅Ej,b
3.5 全球关系语境学习
用户偏好是动态的,我们的TGT进一步提出将长期动态注入到全局级别的图关系编码器中,该编码器从长期和短期的角度捕捉动态的多行为模式:
定义了一个全局用户图u 和 其中的子列节点u_r G = {U,U_r,E}
在该组件中,全局用户嵌入Γ通过在短期用户偏好嵌入上进行图结构信息聚合产生的
3.5.1 全局级别的用户表示
为是实现全局表示,我们将时间背景融入到注意图神经结构的信息传递过程中并允许用不同时间戳编码的短期偏好以可微分的方式相互交互
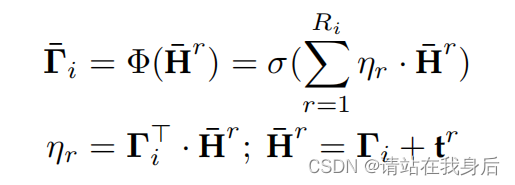
通过这样做,TGT保留了不同时期的用户偏好嵌入,作为全局用户表示的统一特征嵌入,并对时间依赖性以及用户交互模式的演变进行建模。
3.6 高阶关系聚合
如前所述,TGT对编码信息进行两阶段信息聚合
1)用户与项目之间的短期多行为互动
2)跨时间的用户兴趣的长期动态结构依赖性。
我们的TGT体系结构通常以Gr和G的关系结构作为计算图进行嵌入传播,在嵌入传播过程中,将来自邻域的局部关系特征进行聚合,获得语境表示
通过引入高阶连接,可以将这种消息传递范式推广如下(假设l表示基于图的信息传播体系结构中的第(l)层GNN):
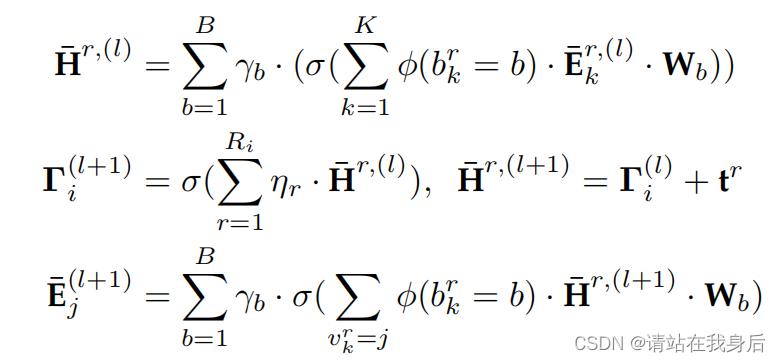
通过将我们开发的图关系编码器从一层扩展到多层(即L),我们赋予TGT跨不同用户/物品捕获高阶协作效果的能力,最终表示如下
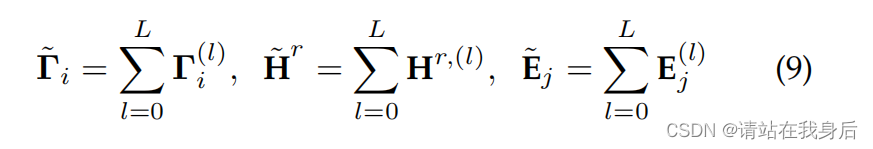
3.7 模型预测与优化
用户和项目未来交换的概率定于为
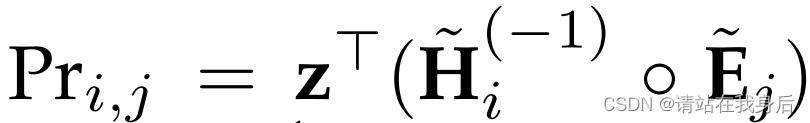
3.7.1 优化目标
采用 the marginal pairwise loss
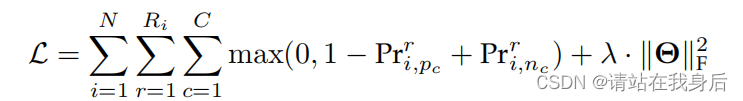
4 实验
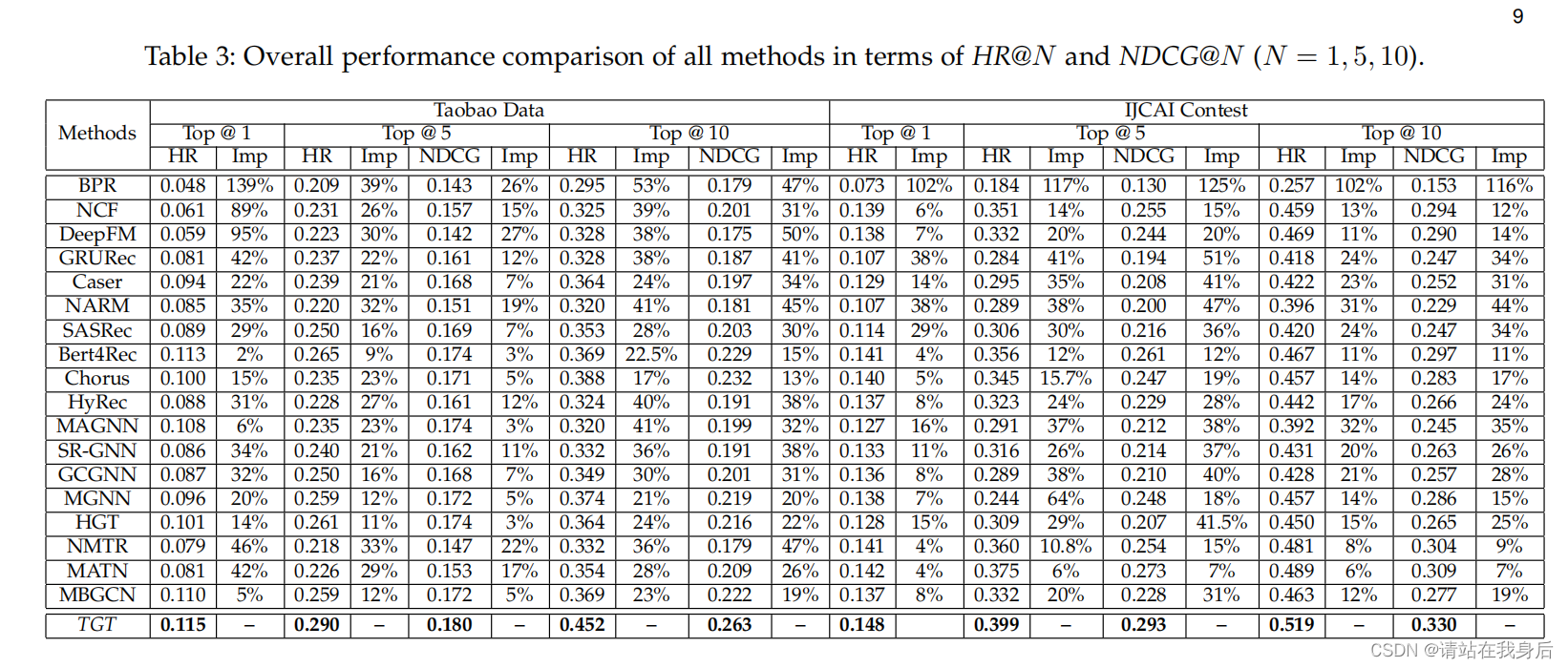
1.与基线比性能如何
2.各组件对TGT的作用如何
3.不同类型行为模式的整合如何影响目标行为的预测?
4.参数的配置如何影响推荐性能
**数据集:Taobao,**IJCAI
评估:NDCG@N and Recall@N
**基线:**常规矩阵分解模型:BPR;神经协同过滤法:NCF,DeepFM;
基于RNN的顺序推荐方法:GRURec;基于卷积的顺序推荐:Caser
基于注意/变压器的顺序推荐系统神经网络:NARM,SASRec:Bert4Rec
使用的顺序/基于会话的推荐模型以及基于神经网络的模型
异构图神经模型:*HGT,Multi-Behavior推荐框架:NMTR,MATN
4.1 性能比较
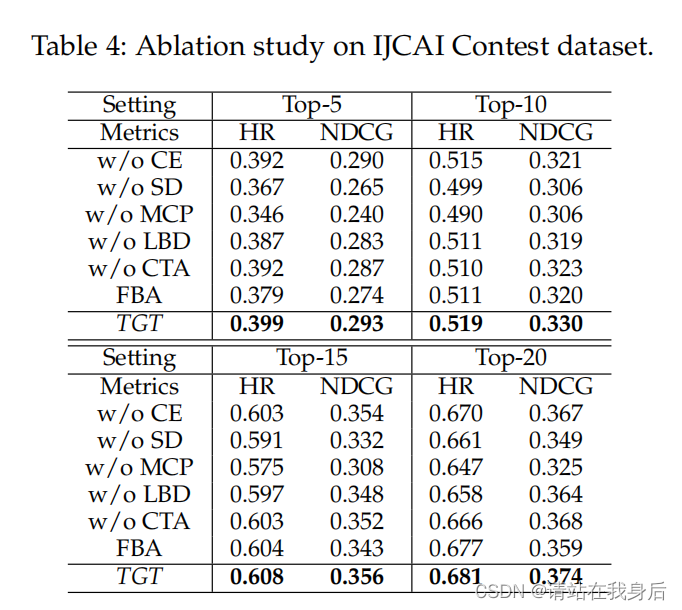
4.2 消融实验
变体:
CE:在顺序依赖项编码期间忽略时间和行为感知语境。
SD:没有使用多行为转换器来捕获短期偏好
MCP:没有多通道投影层
LBD:忽略了带有行为类型感知消息传递组件的全局关系学习
CTA:没有探索我们关注的聚合层的交叉类型行为关系
4.3 情境行为的影响
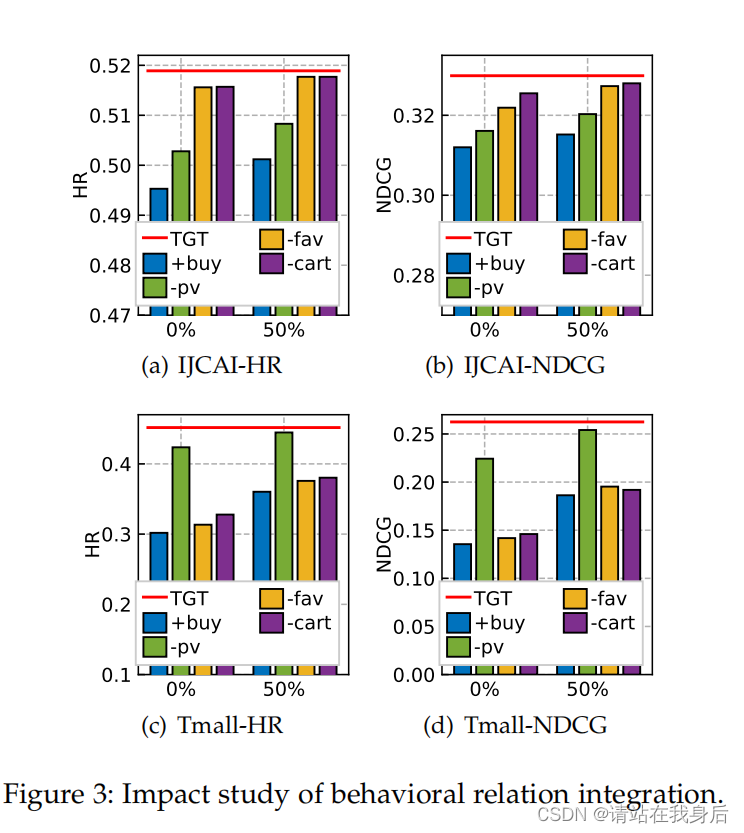
TGT在所有情况下都一致地实现了最佳性能,这验证了上下文行为多样性对序列交互模式建模的重要性。我们可以观察到,页面视图和浏览行为对购买预测的贡献更大,在两个不同的数据集上显示出一致的趋势
4.4 模型超参数研究
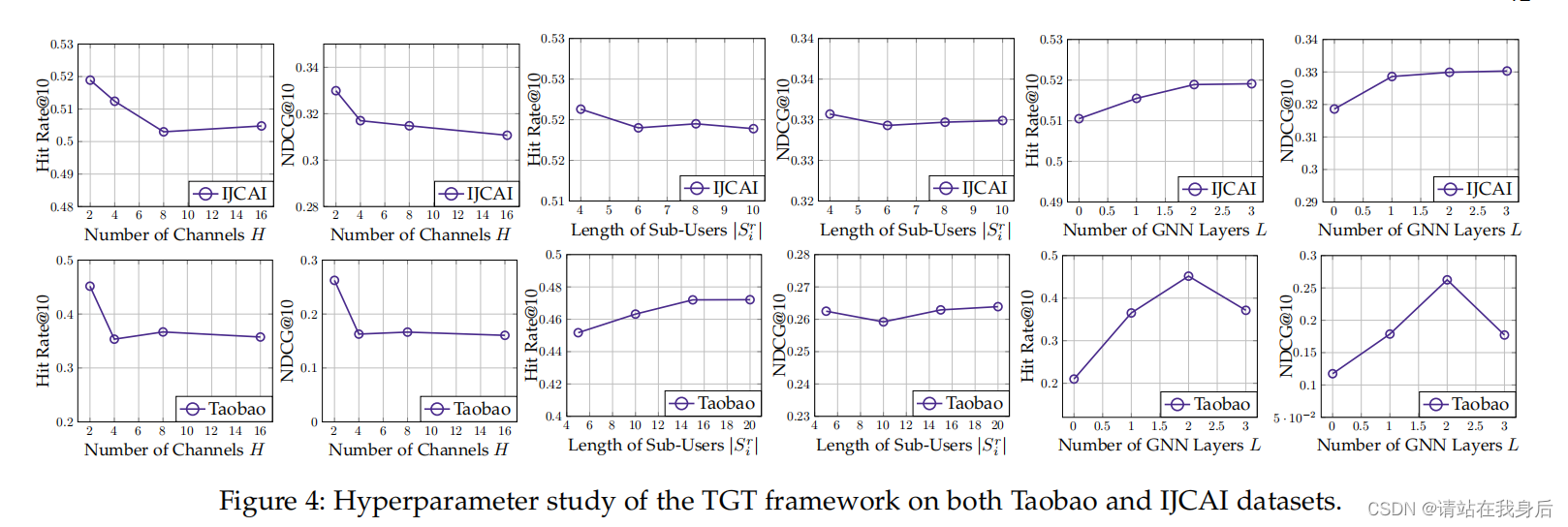
投影通道的影响:我们可以观察到配置两个投影通道可以获得最佳的推荐性能。
交互序列长度的影响:交互子序列Sir作为短期多行为模式建模的序列单元,我们可以观察到编码序列长度的影响可能因数据集而异。
特别是在IJCAI-Contest数据上的性能对序列长度不是很敏感。原因是短期的项目转换也可以通过高阶信息传播范式在构造的大规模图上被捕获。当子序列较短时,模型不能获得较好的性能
图模型层的影响
将嵌入传播层的数量增加到2 (TGT-2)可以大大提高与TGT-1相比的性能(通过单跳连接上的关系学习)。这种性能的提高可以归因于对高阶多行为模式以及潜在的交叉序列关系的探索。
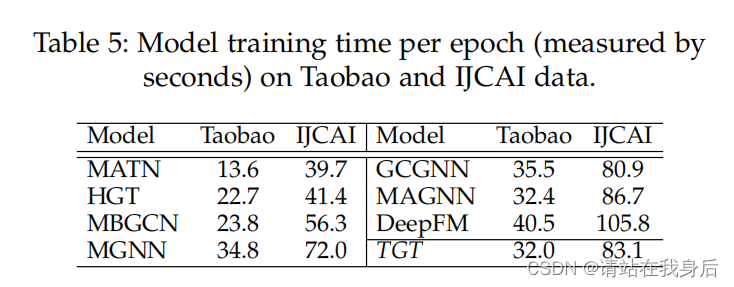
4.5 模型效率测试
5 总结和讨论:
本文通过分解具有行为异质性的交互,提出了一种新的序列推荐学习框架(TGT)。TGT的目标是聚合来自不同类型用户行为的动态关系上下文信号,并生成语境表示,用于对目标行为进行预测。


















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











