






训练/开发/测试集划分
设立训练集,开发集和测试集的方式大大影响了或者团队在建立机器学习应用方面取得进展的速度。同样的团队,即使是大公司里的团队,在设立这些数据集的方式,真的会让团队的进展变慢而不是加快,看看应该如何设立这些数据集,让团队效率最大化。

在此,想集中讨论如何设立开发集和测试集,开发(dev)集也叫做开发集(development set),有时称为保留交叉验证集(hold out cross validation set)。然后,机器学习中的工作流程是,尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善开发集的性能,直到最后可以得到一个令满意的成本,然后再用测试集去评估。
现在,举个例子,要开发一个猫分类器,然后在这些区域里运营,美国、英国、其他欧洲国家,南美洲、印度、中国,其他亚洲国家和澳大利亚,那么应该如何设立开发集和测试集呢?
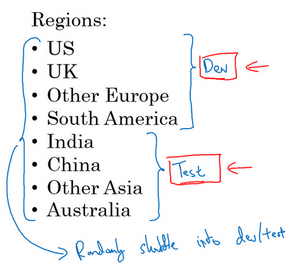
其中一种做法是,可以选择其中4个区域,打算使用这四个(前四个),但也可以是随机选的区域,然后说,来自这四个区域的数据构成开发集。然后其他四个区域,打算用这四个(后四个),也可以随机选择4个,这些数据构成测试集。
事实证明,这个想法非常糟糕,因为这个例子中,开发集和测试集来自不同的分布。建议们不要这样,而是让开发集和测试集来自同一分布。的意思是这样,们要记住,想就是设立开发集加上一个单实数评估指标,这就是像是定下目标,然后告诉团队,那就是要瞄准的靶心,因为一旦建立了这样的开发集和指标,团队就可以快速迭代,尝试不同的想法,跑实验,可以很快地使用开发集和指标去评估不同分类器,然后尝试选出最好的那个。所以,机器学习团队一般都很擅长使用不同方法去逼近目标,然后不断迭代,不断逼近靶心。所以,针对开发集上的指标优化。
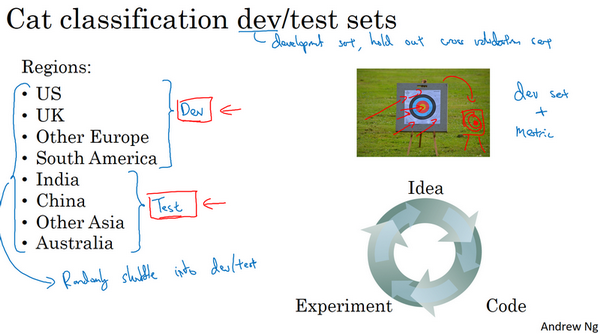
然后在左边的例子中,设立开发集和测试集时存在一个问题,团队可能会花上几个月时间在开发集上迭代优化,结果发现,当们最终在测试集上测试系统时,来自这四个国家或者说下面这四个地区的数据(即测试集数据)和开发集里的数据可能差异很大,所以可能会收获"意外惊喜",并发现,花了那么多个月的时间去针对开发集优化,在测试集上的表现却不佳。所以,如果开发集和测试集来自不同的分布,就像设了一个目标,让团队花几个月尝试逼近靶心,结果在几个月工作之后发现,说“等等”,测试的时候,“要把目标移到这里”,然后团队可能会说"好吧,为什么让花那么多个月的时间去逼近那个靶心,然后突然间可以把靶心移到不同的位置?"。
所以,为了避免这种情况,建议的是将所有数据随机洗牌,放入开发集和测试集,所以开发集和测试集都有来自八个地区的数据,并且开发集和测试集都来自同一分布,这分布就是所有数据混在一起。
这里有另一个例子,这是个真实的故事,但有一些细节变了。所以知道有一个机器学习团队,花了好几个月在开发集上优化,开发集里面有中等收入邮政编码的贷款审批数据。那么具体的机器学习问题是,输入\(x\)为贷款申请,是否可以预测输出\(y\),\(y\)是他们有没有还贷能力?所以这系统能帮助银行判断是否批准贷款。所以开发集来自贷款申请,这些贷款申请来自中等收入邮政编码,zip code就是美国的邮政编码。但是在这上面训练了几个月之后,团队突然决定要在,低收入邮政编码数据上测试一下。当然了,这个分布数据里面中等收入和低收入邮政编码数据是很不一样的,而且他们花了大量时间针对前面那组数据优化分类器,导致系统在后面那组数据中效果很差。所以这个特定团队实际上浪费了3个月的时间,不得不退回去重新做很多工作。

这里实际发生的事情是,这个团队花了三个月瞄准一个目标,三个月之后经理突然问"们试试瞄准那个目标如何?",这新目标位置完全不同,所以这件事对于这个团队来说非常崩溃。
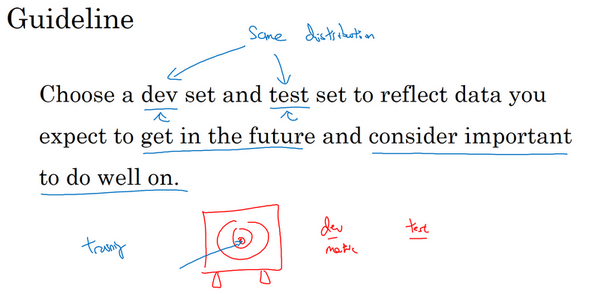
所以建议们在设立开发集和测试集时,要选择这样的开发集和测试集,能够反映未来会得到的数据,认为很重要的数据,必须得到好结果的数据,特别是,这里的开发集和测试集可能来自同一个分布。所以不管未来会得到什么样的数据,一旦算法效果不错,要尝试收集类似的数据,而且,不管那些数据是什么,都要随机分配到开发集和测试集上。因为这样,才能将瞄准想要的目标,让团队高效迭代来逼近同一个目标,希望最好是同一个目标。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 5378
5378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









