






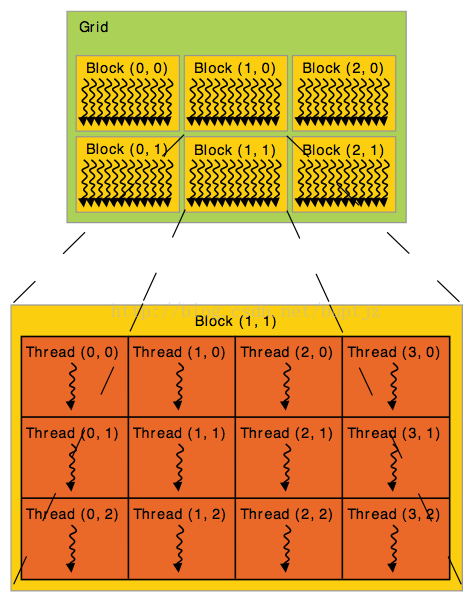
BLOCK和GRID
- 许多的线程组织在一个BLOCK里,threadIdx变量指示该线程是哪一个线程。而BLOCK有一个限制:一个BLOCK最多能含有1024个线程。怎么办呢,我们可以使用多个BLOCK,多个BLOCK怎么组织呢?使用GRID!
- GRID和BLOCK的关系就和BLOCK和THREAD的关系类似。
- BLOCK和GRID可以是int类型,也可以是dim3类型
- <<<...>>> 符号指定使用多少BLOCK和GRID
- BLOCK可以是1维、2维、3维
- kernel通过blockIdx变量来获取当前是那个BLOCK
- BLOCK的维数则可以通过blockDim这个变量获取
- 组织结构如图所示
Memory
1)Local memory:一个线程内部变量占据的内存
2)shared memory:一个BLOCK内部所有线程共享的内存
【
注:__shared__修饰符表示这个BLOCK共享内存】
3)global memory:全部线程共有的内存
速度 1)大于 2)远大于 3)
这里有一道练习题:下面的这段代码,1,2,3,4行中,每一行的运算最快,哪一行最慢,分别给每一行打分,分数1~4
__global__ void foo(float *x,float *y,float *z){
__shared__ float a,b,c;
float s,t,u;
s = *x;//1
t = s;//2
a = b;//3
*y = *z;//4
}
同步(Synchronise)
就像给代码设置一个障碍一样
现在我们要做这样一件事,有一个数组,我们想将这个数组每一项向前移动一位(忽略第一项),也就是array[x] = array[x+1]
一个简略的函数框架可能是这样的:
__global__ void shift(){
int idx = threadIdx.x;
__shared__ int array[128];
array[idx] = threadIdx.x;
if (idx < 127) {
array[idx] = array[idx + 1];
}
}array[20] = 20;可以执行
array[20] = array[20+1];如果线程21在线程20之后执行,显然这句话的赋值是错误的
那么正确的运行上述程序,需要给代码设置几个“障碍”,如下
__global__ void shift(){
int idx = threadIdx.x;
__shared__ int array[128];
array[idx] = threadIdx.x;
__syncthreads();//执行至此,数组中的每一个元素都被正确的赋值
if (idx < 127) {
int temp = array[idx + 1];
__syncthreads();//将一行代码拆分成两行来设置一个barrier,这种技巧非常实用,执行至此,每一个线程都正确的取值
array[idx] = temp;
__syncthreads();//确保后续使用array的正确性
}
}














 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









