







近年来,attention机制在深度学习领域受到了越来越多的关注。从数学的形式上看,attention机制只是简单地对输入项根据重要程度分配不同的加权参数,但这一机制模拟了人脑的认知模式,即根据实际需求而将有限的注意力聚焦于事物的关键部分,从而大大加强了神经网络的理解能力。
由于VQA涉及对图像和文字的深度理解,attention机制在VQA领域自然成了一大利器。于是这周就将attention机制在VQA中的典型应用梳理了一番。(文章参考链接,加上了自己看的部分论文)
目录
1、Question-guided image attention
1、Question-guided image attention
最开始的注意力机制是考虑如何利用问题寻找图片中与问题相关的区域。
(1)Stacked Attention Networks for Image Question Answering
这篇文章是发表于2016年的CVPR,主要贡献为用得到的文本向量不断来attention图像中的区域,获得图片中更精准的区域,具体方法为分别利用单层网络将问题向量和视觉向量映射,然后进行元素级的相加,然后利用tanh进行非线性化,然后再次映射通过softmax得到图片的权重。将权重与视觉向量相乘得到加权后的向量。将视觉向量与文本向量相加后得到新的问题输入(注意这里是问题表示,用来再次attention图片)。

 (2)Where To Look: Focus Regions for Visual Question Answering
(2)Where To Look: Focus Regions for Visual Question Answering
这篇文章也是发布于CVPR2016的文章,这种attention方式也是比较简单,首先将图片和文字进行embedding之后,进行点乘然后通过softmax得到一个权重向量(这里的权重向量就是简单的将每个区域的特征向量与文本特征相乘),这个权重向量与上文相同与区域的数量一致,然后坐着将图片特征与文本特征concat之后,输入至一个单层网络中,将权重与得到的特征相乘,再输入至最后的分类层。

(3)Visual7W: Grounded Question Answering in Images
这篇文章将注意力机制与LSTM相结合,将attention放在问题上的LSTM,每输入一个word就产生一个注意力图,然后就生成了一个新的视觉特征。在特征融合方面选择使用的了点乘。但是本篇文章的核心还是利用问题来获得图片中的注意力。


(4)Differential Attention for Visual Question Answering
已有的注意力研究都是通过关注某一个图像区域来回答问题,而本文认为已有研究的注意力机制关注的区域与人类会关注的图像区域并不相关。因此,本文提出通过一或多个支持和反对范例来取得一个微分注意力区域(differential attention region)。
与基于图像的注意力方法比起来,本文计算出的微分注意力更接近人类注意力,因此可以提高回答问题的准确率。本文的前提是,语义最近的范例和远语义范例之间存在差异,这样的差异能够引导注意力关注于一个特定的图像区域。
原理流程:
1、根据输入图像和问题取得引用注意力嵌入(reference attention embedding);
2、根据该引用注意力嵌入,在数据库中找出样本,取近样本作为支持范例、远样本作为反对范例;
3、支持范例和反对范例用于计算微分注意力向量;
4、通过微分注意力网络(differential attention network, DAN)或微分上下文网络(differential context network)分别可以改进注意力或取得微分上下文特征,这两种方法可以提升注意力与人工注意力的相关性;
5、首先为微分注意力网络(differential attention network, DAN),重点为通过正反例注意力更新目标注意力,使之与人类的注意力更相似。


然后就是微分上下文注意力(DCN),其主要应用映射的概念,缩小正例与目标注意力之间的距离,删除反例上下文与目标注意力之间的特征,从而达到更新注意力的目的。


上述两种模型,是利用正反例来达到对目标注意力的更新,首先还是属于利用问题对视觉注意力进行引导,根据问题调整对图片的注意力,从而使模型关注关键的区域。得到注意力之后,再通过正反例的注意力进行修正。
2、Co-attention
这种注意力机制不光考虑利用得到视觉的注意力,还会考虑得到问题的注意(即问题中哪些单词更为重要。)
(1)Hierarchical Question-Image Co-Attention for Visual Question Answering
- Co-Attention 与之前的工作不同,作者的提出的模型是对称的,通过图片表示可以引导产生问题的注意力,问题表示可以引导产生图片的注意力。
- Question Hierarchy 构建了一个层次结构,它在三个级别上共同参与图像和问题:(a)单词级别,(b)短语级别和(c)问题级别。 在单词级别,通过嵌入矩阵将单词嵌入向量空间。 在短语级别,使用一维卷积神经网络捕获单字组,二元组和三字组中包含的信息。具体地说,将单词表示与各种支持的时间过滤器进行卷积,然后将各种n-gram响应组合成一个短语级表示。在问题层,我们使用递归神经网络对整个问题进行编码。对于该层次结构中问题表示的每一层,我们构造联合问题和图像共同注意映射,然后递归地组合这些映射,最终预测答案的分布。


这一工作考虑了image attention和question attention的协同作用,既有question-guided image attention,又有image-guided question attention,具有对称性,故称co-attention。另外,本文的另一特色是利用了层级架构(hierarchy)。
(2)Dual Attention Networks for Multimodal Reasoning and Matching Hyeonseob(CVPR 2017)
这篇文章也应用了极其类似的attention机制:


从模型示意图上可以看到,这里同样应用了image attention和question attention,两者通过共有的memory向量互相产生联系并通过迭代过程逐步细化。其中细节为将memory向量和视觉(问题)向量相乘。
(3)Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering

在他们的模型中,question attention参与image attention的计算,但不同上面两个工作,这里question attention是独立推断的,作者们认为这与人类的反应一致,人们不需要借助图片也能抓住问题的重点。其中MFB具体为:

主要是将两种模态的结合时利用Hadmard product或者element-wise。
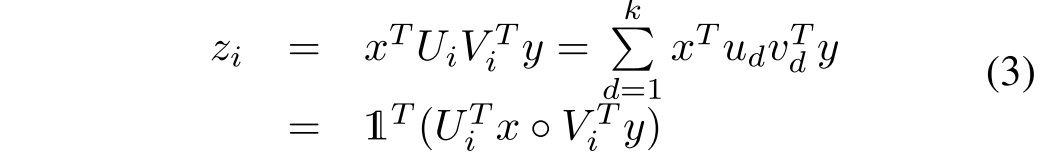
(4)Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention

该文给我带来的思考首先于注意力的使用,它采用的co-attention结构,注意力函数类似于attention is all you need 类似采用多层尺度乘法注意,第二它对齐图像和问句特征采用多层的co-attention网络,通过拉伸的特征矩阵表示句子或图像。
(5)Multi-level Attention Networks for Visual Question Answering

这篇文章与之前的不一样的是并没有单独对问题进行求注意力,将注意力分成了两部分:
- Semantic Attention:这部分主要是通过CNN提取图片中的主要概念(概念首先是一个列表,就是一个经常出现在图片中的一些高级概念,若图片中存在列表中没有的概念则这部分就没用了),筛选出的概念与问题结合,形成一个注意力,即选出与问题相关的概念,具体结合是将两者点乘(就是element-wise相乘),然后通过sigmoid的激活函数得到两者的相关性分数,然后将分数与概念相乘得到概念的语义注意力权重,最后权重与概念相乘再加和得到最终的高级语义向量。
- Context-aware Attention:这部分就是普通的question-guide,将问题特征与视觉特征分别映射后再相乘(矩阵相乘),得到注意力权重,然后注意力权重再与图像相乘再加和得到加权后的视觉向量。
(6)Deep Modular Co-Attention Networks for Visual Question Answering
共同注意模型学习了多模态实例的粗糙交互,而所学习的共同注意不能推断出每个图像区域和每个问题词之间的相关性。这导致了这些共注意模型的显著局限性。作者认为深度共同注意模型的瓶颈在于在每个模态中同时建模密集的自我注意(即问题的词对词关系和图像的区域对区域关系)的缺陷。

MCAN网络框架的设计灵感来自于Transformer模型,作者设置了两个注意力单元(general attention units):一个自注意力单元(self-attention (SA) unit)进行模态内部交互和一个导向注意力单元(guided-attention (GA) unit)进行模态之间交互。之后再用一个协同注意力模块层(Modular Co-Attention (MCA) layers)将两个单元串联起来,最后将多个模块层串联起来,组成MCAN网络(Modular Co-Attention Network (MCAN))。
3、Detection attention
其方法的新颖性在于提出了基于object detection的bottom-up attention。此前的image attention都是基于CNN特征的,这相当于把图片均等分割成若干区域然后对其进行筛选;而本文提出的bottom-up attention则利用object detection网络Faster R-CNN来实现,将图片分割成一个个具体的物体来进行筛选。
(1)Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
该篇文章主要的贡献在于提供了更好的特征,即题目中所说的Bottom up的图片特征,该方法基于Faster R-CNN框架内的ResNet CNN。通过使用Visual Genome数据集为给定图像中的特定元素标注。由此产生的特征可以解释为以图像中前K个对象为中心的ResNet特征。也就是说,不是用整张图片作为视觉特征,而是选择前K个图片中的proposal作为视觉特征。
而其中的Top-down即问题特征为Top与各个proposal的特征concat之后,通过非线性层和线性层得到一个attention,然后attention与视觉特征相乘得到更好的特征。

对两种模态进行融合,作者采用了简单的元素级相乘(element-wise)

(2)Co-attending Free-form Regions and Detections with Multi-modal Multiplicative Feature Embedding for Visual Question Answering
这篇文章也用到了detection attention,但不同的是,他们并没有放弃原来那种基于CNN特征的image attention(他们称为free-form attention),而是将两者结合,形成free-form attention与detection attention的co-attention。
detection attention的优势上面已经提到过了,然而,detection attention的作用受限于其检测类别的广度,如,对于“How is the weather today?”这样的问题,如果object detection网络不检测“天空”这个object,则模型无法对这一问题做出准确回答。而在这方面,free-form attention就显示出了优势,因此,本文认为这两种attention应是互补的。
4、Relational attention
(1)Object-Difference Attention: A Simple Relational Attention for Visual Question Answering
这篇论文提出了relational attention的概念,首先对图中object两两之间的关系进行建模,再用attention对这些关系进行筛选。

论文中对于比较两个物体之间的关系就是利用两个物体之间的特征进行差分操作,作者也比较了其他的比如相加,但是没有作差效果好。















 1900
1900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









