







仅作为自己学习过程中的一个记录,如有侵权,请联系删除。
如需参考请直接联系原作者。
本文目录
RKNN模型中有两种API提供使用,分别是通用API和零拷贝API。
通用API:通常指的是一种标准化的接口,用于执行一般操作或功能,具有通用性和普适性,适用于多种场景。通用API不关心数据在内存中的存储方式,可能会涉及数据的拷贝或转换操作,以确保接口的通用性和兼容性。通用API可能会更易于使用和理解,但在数据传输方面可能会引入额外的复制开销。
零拷贝API :是指在数据传输过程中,数据并不从原始内存中拷贝到目标内存,而是直接在原始内存和目标内存之间进行传输,以提高性能和降低内存开销。在 RKNN(Rockchip Neural Network)模型中,零拷贝 API 可能用于在输入和输出数据的传输过程中提高效率。
一、加载模型及其基本信息
- 模型加载(初始化模型)
load_model():加载模型数据并返回模型大小和数据指针。
rknn_init():初始化神经网络模型,将加载的模型数据传入,返回初始化状态。
rknn_context ctx; //RKNN模型上下文
//在RKNN推理过程中,该结构体用于保存和管理推理所需的各种资源和状态信息,包括模型数据、输入数据、输出数据、模型参数、推理配置等。
//它是RKNN引擎与应用程序之间的接口,通过对该结构体的操作,可以实现模型加载、推理执行、资源释放等功能。
char model_name = (char )argv[1]; //这里表示运行可执行文件时,传入的第一个参数。
/* Create the neural network /
printf(“Loading mode…\n”);
int model_data_size = 0;
unsigned char model_data = load_model(model_name, &model_data_size);
ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
if (ret < 0)
{
printf(“rknn_init error ret=%d\n”, ret);
return -1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
加载模型函数如下:
static unsigned char *load_data(FILE *fp, size_t ofst, size_t sz)
{
unsigned char *data;
int ret;
data = NULL;
if (NULL == fp)
{
return NULL;
}
ret = fseek(fp, ofst, SEEK_SET);
if (ret != 0)
{
printf("blob seek failure.\n");
return NULL;
}
data = (unsigned char *)malloc(sz);
if (data == NULL)
{
printf("buffer malloc failure.\n");
return NULL;
}
ret = fread(data, 1, sz, fp);
return data;
}
static unsigned char load_model(const char filename, int model_size)
{
FILE fp;
unsigned char data;
fp = fopen(filename, “rb”);
if (NULL == fp)
{
printf(“Open file %s failed.\n”, filename);
return NULL;
}
fseek(fp, 0, SEEK_END);
int size = ftell(fp);
data = load_data(fp, 0, size);
fclose(fp);
model_size = size;
return data;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 查询RKNN的sdk(软件开发包)版本号
这段代码查询了RKNN SDK的版本信息并打印出来。首先,它创建了一个rknn_sdk_version结构体变量version用于存储版本信息。然后,通过rknn_query函数查询RKNN SDK的版本号,使用RKNN_QUERY_SDK_VERSION作为查询类型。如果查询失败,将返回负值。最后,如果查询成功,就打印出SDK版本号和驱动版本号。
rknn_context ctx; //保存RKNN信息
rknn_sdk_version version; //这个结构体不是自定义的,官方结构体吧应该。
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));
if (ret < 0)
{
printf(“rknn_init error ret=%d\n”, ret);
return -1;
}
printf(“sdk version: %s driver version: %s\n”, version.api_version, version.drv_version);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 查询模型的输入输出张量数量。
这段代码查询了模型的输入和输出数量,使用RKNN_QUERY_IN_OUT_NUM作为查询类型。并将结果存储在rknn_input_output_num结构体变量io_num中。这个结构体包含两个成员变量:n_input表示模型的输入数量,n_output表示模型的输出数量。
rknn_context ctx; //保存RKNN信息
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret < 0)
{
printf(“rknn_init error ret=%d\n”, ret);
return -1;
}
printf(“model input num: %d, output num: %d\n”, io_num.n_input, io_num.n_output);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 查询模型的输入、输出属性
这段代码使用RKNN_QUERY_INPUT_ATTR作为查询类型。查询了模型的输入属性,并将结果存储在数组input_attrs中。首先,它创建了一个大小为io_num.n_input的rknn_tensor_attr结构体数组input_attrs,用于存储模型的输入属性。然后,通过循环遍历模型的每个输入,依次查询其属性并填充到对应的数组元素中。在每次查询成功后,会调用dump_tensor_attr函数打印当前输入的属性信息,该函数可能用于输出输入属性的详细信息,例如数据类型、形状、布局等。
rknn_context ctx; //保存RKNN信息
rknn_tensor_attr input_attrs[io_num.n_input]; //输入属性。
rknn_tensor_attr output_attrs[io_num.n_output]; //输出属性。
memset(input_attrs, 0, sizeof(input_attrs)); //将输入属性结构体数值清空
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_input; i++)
{
input_attrs[i].index = i; //将属性索引编号
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
if (ret < 0)
{
printf(“rknn_init error ret=%d\n”, ret);
return -1;
}
dump_tensor_attr(&(input_attrs[i])); //打印 输入属性信息
}
for (int i = 0; i < io_num.n_output; i++)
{
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
dump_tensor_attr(&(output_attrs[i])); //打印 输出属性信息
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
下述代码用于输出属性信息。
static void dump_tensor_attr(rknn_tensor_attr *attr)
{
std::string shape_str = attr->n_dims < 1 ? "" : std::to_string(attr->dims[0]);
for (int i = 1; i < attr->n_dims; ++i)
{
shape_str += ", " + std::to_string(attr->dims[i]);
}
printf(" index=%d, name=%s, n_dims=%d, dims=[%s], n_elems=%d, size=%d, w_stride = %d, size_with_stride=%d, fmt=%s, "
"type=%s, qnt_type=%s, "
“zp=%d, scale=%f\n”,
attr->index, attr->name, attr->n_dims, shape_str.c_str(), attr->n_elems, attr->size, attr->w_stride,
attr->size_with_stride, get_format_string(attr->fmt), get_type_string(attr->type),
get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 检查输入张量的数据格式,获取模型输入的高、宽、通道。
这段代码根据模型输入张量的数据格式(fmt)来确定模型输入的宽度(width)、高度(height)和通道数(channel)。
通常在深度学习中,输入张量的数据格式有两种常见的表示方式:①NCHW(通道-高度-宽度):在这种格式中,张量的第一个维度表示通道数,第二个维度表示高度,第三个维度表示宽度。②NHWC(高度-宽度-通道):在这种格式中,张量的最后一个维度表示通道数,前两个维度表示高度和宽度。
代码首先检查输入张量的数据格式,如果是NCHW格式,则从input_attrs[0].dims数组中读取通道数、高度和宽度;如果是NHWC格式,则从相应位置读取。然后将这些值打印出来,以便开发者了解模型输入的尺寸和通道数。
int channel = 3;
int width = 0;
int height = 0;
if (input_attrs[0].fmt == RKNN_TENSOR_NCHW) //判断输入的类型,判断一个就可以,因为都一样。
{
printf("model is NCHW input fmt\n");
channel = input_attrs[0].dims[1];
height = input_attrs[0].dims[2];
width = input_attrs[0].dims[3];
}
else
{
printf("model is NHWC input fmt\n");
height = input_attrs[0].dims[1];
width = input_attrs[0].dims[2];
channel = input_attrs[0].dims[3];
}
printf("model input height=%d, width=%d, channel=%d\n", height, width, channel);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
二、图片输入预处理
- 准备模型输入数据
这段代码定义了一个名为inputs的rknn_input类型的数组,数组大小为1。然后使用memset函数将数组中的所有元素初始化为0。
index:指定了输入张量的索引,这里设为0,表示第一个输入张量。
type:指定了输入张量的数据类型,这里设为RKNN_TENSOR_UINT8,表示数据类型为无符号8位整数。
size:指定了输入张量的大小,这里计算了输入张量的总大小,即宽度(width)乘以高度(height)乘以通道数(channel)。
fmt:指定了输入张量的数据格式,这里设为RKNN_TENSOR_NHWC,表示数据格式为高度-宽度-通道。
pass_through:指定了是否直接透传数据,这里设为0,表示不透传。
这个过程是为了设置模型的输入张量属性,以便将输入数据传递给模型进行推理
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].type = RKNN_TENSOR_UINT8; // 假设输入是 uint8 类型
inputs[0].size = width height channel;// 输入数据的大小,这里为输入模型的宽、高、通道。
inputs[0].fmt = RKNN_TENSOR_NHWC; // 输入数据的格式为NHWC。
inputs[0].pass_through = 0; // 不使用零拷贝。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 读取图片,获取要识别的图片。orig_img 为原始图片。
char *input_path = argv[2]; //这里是运行可执行文件时,传入的第二个参数。
// 读取图片
printf("Read %s ...\n", input_path);
cv::Mat orig_img = cv::imread(input_path, 1); //0:灰度图像。1:RGB彩色图像。-1:原图像。
if (!orig_img.data) //是否读取到图片内容
{
printf("cv::imread %s fail!\n", input_path);
return -1;
}
cv::Mat img;
cv::cvtColor(orig_img, img, cv::COLOR_BGR2RGB); //因为读取的彩色图像并不是RGB格式,而是BGR格式。所以需要转换为RGB。
img_width = img.cols; //照片的宽
img_height = img.rows; //照片的高
printf("img width = %d, img height = %d\n", img_width, img_height);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 修改图片尺寸为模型输入尺寸大小,以准备将其作为输入传递给模型进行推理。
RGA(Rockchip GPU Acceleration)是由Rockchip提供的一种硬件加速技术,用于处理多媒体数据,包括图像处理和视频处理。RGA 提供了高效的硬件加速功能,可以在嵌入式设备上进行快速的图像缩放、旋转、颜色转换、格式转换等操作。其目标是减轻CPU的负担,提高图像处理的效率和性能。
Letterbox是一种用在图像和视频处理领域的技术,用于在保持原始纵横比的同时,将图像或视频适配到不同的显示分辨率。具体来说,当一个图像或视频的纵横比不匹配目标显示区域的纵横比时,为了避免变形或裁剪,letterbox 会在图像或视频的上下(或者左右)添加黑边,以填满整个显示区域。
typedef struct _BOX_RECT
{
int left;
int right;
int top;
int bottom;
} BOX_RECT;
std::string option = “letterbox”;
// 指定目标大小和预处理方式,默认使用LetterBox的预处理
BOX_RECT pads;
memset(&pads, 0, sizeof(BOX_RECT));
初始化RGA上下文。用于描述图像缓冲区。
//具体来说,这些结构体用于定义源图像和目标图像的信息,如图像的数据指针、宽度、高度、格式等
rga_buffer_t src; //结构体为rga库里声明。
rga_buffer_t dst;
memset(&src, 0, sizeof(src));
memset(&dst, 0, sizeof(dst));
//cv::Size 是 OpenCV 库中用于表示图像大小的类。
cv::Size target_size(width, height); //创建目标图像的尺寸。这里的width和height为“标题一,5中获取的模型输入的尺寸大小”
cv::Mat resized_img(target_size.height, target_size.width, CV_8UC3);//创建了一个大小为目标尺寸的CV_8UC3类型的空图像resized_img,用于存储预处理后的图像。
if (img_width != width || img_height != height) //如果图片尺寸和模型输入的尺寸不同
{
//如果预处理选项option为"resize",则调用resize_rga函数对图像进行直接缩放,并保存预处理后的图像为"resize_input.jpg"。
if (option “resize”)
{
printf(“resize image by rga\n”);
ret = resize_rga(src, dst, img, resized_img, target_size);
if (ret != 0)
{
fprintf(stderr, “resize with rga error\n”);
return -1;
}
// 保存预处理图片
cv::imwrite(“resize_input.jpg”, resized_img);
}
//如果预处理选项为"letterbox",则调用letterbox函数对图像进行按比例缩放和填充处理,并保存预处理后的图像为"letterbox_input.jpg"。
else if (option “letterbox”)
{
// 计算缩放比例
float scale_w = (float)target_size.width / img.cols; //这里的img.cols为上述2中读取图片获得的图像宽度。
float scale_h = (float)target_size.height / img.rows;//这里的img.rows为上述2中读取图片获得的图像高度。
printf(“resize image with letterbox\n”);
float min_scale = std::min(scale_w, scale_h); //找出scale_w和scale_h之间最小的。
scale_w = min_scale;
scale_h = min_scale;
letterbox(img, resized_img, pads, min_scale, target_size);//将处理的图片存在resized_img中。
// 保存预处理图片
cv::imwrite(“letterbox_input.jpg”, resized_img);
}
else
{
fprintf(stderr, “Invalid resize option. Use ‘resize’ or ‘letterbox’.\n”);
return -1;
}
inputs[0].buf = resized_img.data; //准备好模型的输入数据
}
else //如果图片尺寸和模型输入的尺寸相同
{
inputs[0].buf = img.data; //准备好模型的输入数据
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
上述代码中所使用的函数如下。
int resize_rga(rga_buffer_t &src, rga_buffer_t &dst, const cv::Mat &image, cv::Mat &resized_image, const cv::Size &target_size) { //定义图像的矩形区域。 im_rect src_rect; //源图像处理区域。 im_rect dst_rect;//目标图像的处理区域。 memset(&src_rect, 0, sizeof(src_rect)); memset(&dst_rect, 0, sizeof(dst_rect));<span class="token class-name">size_t</span> img_width <span class="token operator">=</span> image<span class="token punctuation">.</span>cols<span class="token punctuation">;</span> <span class="token class-name">size_t</span> img_height <span class="token operator">=</span> image<span class="token punctuation">.</span>rows<span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>image<span class="token punctuation">.</span><span class="token function">type</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">!=</span> CV_8UC3<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token function">printf</span><span class="token punctuation">(</span><span class="token string">"source image type is %d!\n"</span><span class="token punctuation">,</span> image<span class="token punctuation">.</span><span class="token function">type</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token class-name">size_t</span> target_width <span class="token operator">=</span> target_size<span class="token punctuation">.</span>width<span class="token punctuation">;</span> <span class="token class-name">size_t</span> target_height <span class="token operator">=</span> target_size<span class="token punctuation">.</span>height<span class="token punctuation">;</span> <span class="token comment"> 设置源图像缓冲区信息</span> src <span class="token operator">=</span> <span class="token function">wrapbuffer_virtualaddr</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token keyword">void</span> <span class="token operator">*</span><span class="token punctuation">)</span>image<span class="token punctuation">.</span>data<span class="token punctuation">,</span> img_width<span class="token punctuation">,</span> img_height<span class="token punctuation">,</span> RK_FORMAT_RGB_888<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">// 设置目标图像缓冲区信息</span> dst <span class="token operator">=</span> <span class="token function">wrapbuffer_virtualaddr</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token keyword">void</span> <span class="token operator">*</span><span class="token punctuation">)</span>resized_image<span class="token punctuation">.</span>data<span class="token punctuation">,</span> target_width<span class="token punctuation">,</span> target_height<span class="token punctuation">,</span> RK_FORMAT_RGB_888<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">int</span> ret <span class="token operator">=</span> <span class="token function">imcheck</span><span class="token punctuation">(</span>src<span class="token punctuation">,</span> dst<span class="token punctuation">,</span> src_rect<span class="token punctuation">,</span> dst_rect<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//确保缓冲区和矩形区域有效。</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>IM_STATUS_NOERROR <span class="token operator">!=</span> ret<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token function">fprintf</span><span class="token punctuation">(</span><span class="token constant">stderr</span><span class="token punctuation">,</span> <span class="token string">"rga check error! %s"</span><span class="token punctuation">,</span> <span class="token function">imStrError</span><span class="token punctuation">(</span><span class="token punctuation">(</span>IM_STATUS<span class="token punctuation">)</span>ret<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> IM_STATUS STATUS <span class="token operator">=</span> <span class="token function">imresize</span><span class="token punctuation">(</span>src<span class="token punctuation">,</span> dst<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//调用RGA实现快速图像缩放操作。</span> <span class="token keyword">return</span> <span class="token number">0</span><span class="token punctuation">;</span>
}
void letterbox(const cv::Mat &image, cv::Mat &padded_image, BOX_RECT &pads, const float scale, const cv::Size &target_size, const cv::Scalar &pad_color)
{
// 调整图像大小
cv::Mat resized_image;
//输入数据:image,输出数据:resized_image。cv::Size()(空的大小),所以输出图像的大小将由缩放因子决定。
// scale, scale 为宽度缩放因子、高度缩放因子。
cv::resize(image, resized_image, cv::Size(), scale, scale);
<span class="token comment">// 计算填充大小</span>
<span class="token keyword">int</span> pad_width <span class="token operator">=</span> target_size<span class="token punctuation">.</span>width <span class="token operator">-</span> resized_image<span class="token punctuation">.</span>cols<span class="token punctuation">;</span> <span class="token comment">//目标宽度-缩放后的宽度。</span>
<span class="token keyword">int</span> pad_height <span class="token operator">=</span> target_size<span class="token punctuation">.</span>height <span class="token operator">-</span> resized_image<span class="token punctuation">.</span>rows<span class="token punctuation">;</span> <span class="token comment">//目标高度-缩放后的高度。</span>
pads<span class="token punctuation">.</span>left <span class="token operator">=</span> pad_width <span class="token operator">/</span> <span class="token number">2</span><span class="token punctuation">;</span>
pads<span class="token punctuation">.</span>right <span class="token operator">=</span> pad_width <span class="token operator">-</span> pads<span class="token punctuation">.</span>left<span class="token punctuation">;</span>
pads<span class="token punctuation">.</span>top <span class="token operator">=</span> pad_height <span class="token operator">/</span> <span class="token number">2</span><span class="token punctuation">;</span>
pads<span class="token punctuation">.</span>bottom <span class="token operator">=</span> pad_height <span class="token operator">-</span> pads<span class="token punctuation">.</span>top<span class="token punctuation">;</span>
<span class="token comment">// 在图像周围添加填充</span>
<span class="token comment">//resized_image输入图像,padded_image输出图像,pads.top添加到顶部的宽度(像素值)..</span>
<span class="token comment">//BORDER_CONSTANT选择常数值填充,pad_color填充颜色。</span>
cv<span class="token operator">::</span><span class="token function">copyMakeBorder</span><span class="token punctuation">(</span>resized_image<span class="token punctuation">,</span> padded_image<span class="token punctuation">,</span> pads<span class="token punctuation">.</span>top<span class="token punctuation">,</span> pads<span class="token punctuation">.</span>bottom<span class="token punctuation">,</span> pads<span class="token punctuation">.</span>left<span class="token punctuation">,</span> pads<span class="token punctuation">.</span>right<span class="token punctuation">,</span> cv<span class="token operator">::</span>BORDER_CONSTANT<span class="token punctuation">,</span> pad_color<span class="token punctuation">)</span><span class="token punctuation">;</span>
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 绑定模型输入数据,设置模型输出类型。
rknn_inputs_set(ctx, io_num.n_input, inputs); //将输入数据设置到模型中
rknn_output outputs[io_num.n_output]; //定义模型输出
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++)
{
outputs[i].want_float = 0; //模型输出类型为整数型。0:整数,1:浮点数(float 32)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
三、模型推理
绑定好输入数据后,就可以进行模型的推理了。
模型推理是将训练好的模型应用到新数据上的过程,其目的是利用模型所学到的知识来对新数据进行预测和分析。这一过程在许多领域中都有广泛的应用,从而为各类应用场景提供智能化的解决方案。
struct timeval start_time, stop_time;
gettimeofday(&start_time, NULL); //获取开始的时间
// 执行推理
ret = rknn_run(ctx, NULL); //ctx为之前设置好的RKNN上下文,NULL为默认设置。
// 获取输出
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
gettimeofday(&stop_time, NULL); //获取结束时间
printf(“once run use %f ms\n”, (__get_us(stop_time) - __get_us(start_time)) / 1000); //打印运行时间
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取us的函数:
double __get_us(struct timeval t)
{
return (t.tv_sec * 1000000 + t.tv_usec);
}
- 1
- 2
- 3
- 4
四、后处理操作
我们可以查看rknn模型的输入以及输出。发现模型有三个输出,如下所示。我们将这三个输出放到后处理函数中进行处理。
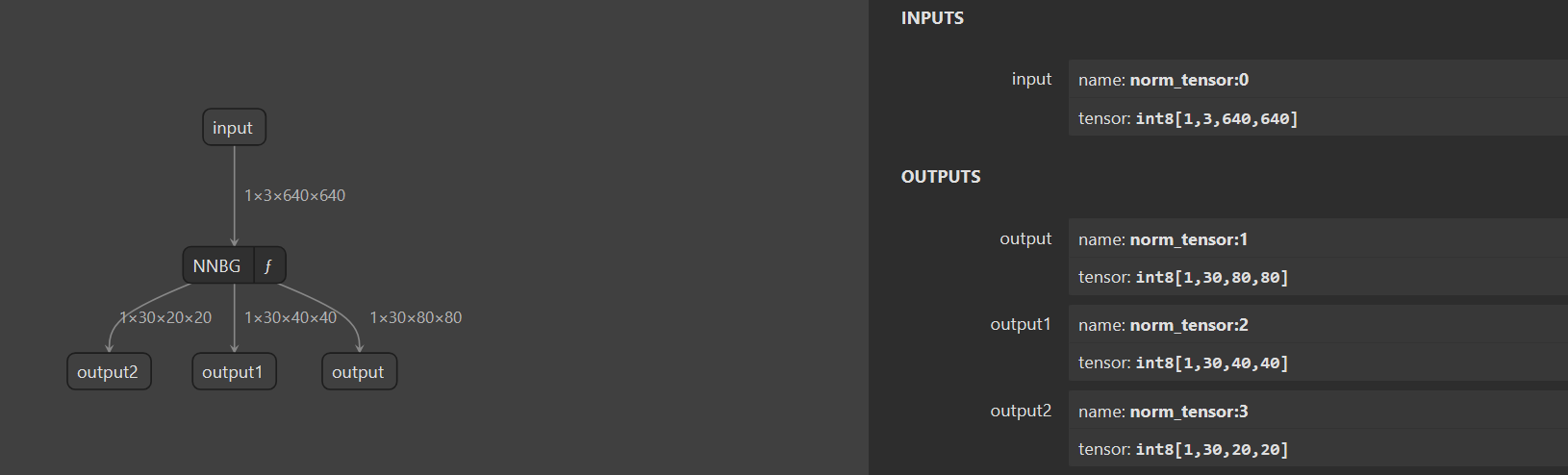
模型的后处理(Post-Processing)是指在模型推理(即模型对输入数据进行预测)之后,对模型的输出进行进一步的处理和优化,以使结果更加符合实际应用需求。模型的后处理是一个关键步骤,通过对模型的原始输出进行必要的处理,使其适应具体的应用需求,并提高结果的准确性和实用性。无论是分类、检测、分割还是其他任务,后处理都在确保模型预测结果的可用性和可靠性方面扮演着重要角色。
常见的后处理操作:① 结果转换和格式化 。② 阈值处理。③ 非极大值抑制④ 边界框解码。⑤图像后处理。⑥文本后处理。⑦坐标变换。⑧数据聚合…等操作。
//--------------------------------主函数中使用后处理函数-----------------------
#define OBJ_NAME_MAX_SIZE 16 //检测类别名称的长度
#define OBJ_NUMB_MAX_SIZE 64 //检测结果的个数
// 后处理
detect_result_group_t detect_result_group;
std::vector<float> out_scales;//定义float向量(动态数组)
std::vector<int32_t> out_zps;//定义int向量(动态数组)
for (int i = 0; i < io_num.n_output; ++i) //遍历模型输出
{
//将模型输出的比例因子(scale)和零点偏移(zero point)值存储。
//push_back,它会将指定的元素添加到向量的末尾,并且如果需要,向量的大小会自动增加以容纳新元素。
out_scales.push_back(output_attrs[i].scale);
out_zps.push_back(output_attrs[i].zp);
}
post_process((int8_t )outputs[0].buf, (int8_t )outputs[1].buf, (int8_t *)outputs[2].buf, height, width,
box_conf_threshold, nms_threshold, pads, scale_w, scale_h, out_zps, out_scales, &detect_result_group);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上述代码关联代码如下:
- 后处理函数
用于对模型输出的目标检测结果进行后处理,包括过滤、排序、非极大值抑制(NMS)和转换坐标等操作,最终将处理后的结果保存在 group 结构体中。
#define LABEL_NALE_TXT_PATH "./model/coco_80_labels_list.txt"
#define OBJ_CLASS_NUM 80
static char *labels[OBJ_CLASS_NUM];
//这些数组是目标检测算法中使用的锚框(Anchor Boxes)的尺寸信息。 第一个为宽
const int anchor0[6] = {
10, 13, 16, 30, 33, 23}; //含了三个尺寸为 (10, 13), (16, 30), (33, 23) 的锚框。
const int anchor1[6] = {
30, 61, 62, 45, 59, 119}; //包含了三个尺寸为 (30, 61), (62, 45), (59, 119) 的锚框。
const int anchor2[6] = {
116, 90, 156, 198, 373, 326};//包含了三个尺寸为 (116, 90), (156, 198), (373, 326) 的锚框。
typedef struct __detect_result_t
{
char name[OBJ_NAME_MAX_SIZE]; //检测结果类别名称
BOX_RECT box; //识别框
float prop; //置信度
} detect_result_t;
typedef struct _detect_result_group_t
{
int id;
int count;
detect_result_t results[OBJ_NUMB_MAX_SIZE];
} detect_result_group_t;
int post_process(int8_t input0, int8_t input1, int8_t input2, int model_in_h, int model_in_w, float conf_threshold,
float nms_threshold, BOX_RECT pads, float scale_w, float scale_h, std::vector<int32_t> &qnt_zps,
std::vector<float> &qnt_scales, detect_result_group_t group)
{
static int init = -1;
if (init == -1)
{
int ret = 0;
ret = loadLabelName(LABEL_NALE_TXT_PATH, labels); //获取地址文本里的标签,存到labels数组里。
if (ret < 0)
{
return -1;
}
init = 0;
}
memset(group, 0, sizeof(detect_result_group_t)); //清空group数组。
//定义向量(动态数组)
std::vector<float> filterBoxes;
std::vector<float> objProbs; //目标概率
std::vector<int> classId;
<span class="token comment">// stride 8 //stride即跨度。</span>
<span class="token keyword">int</span> stride0 <span class="token operator">=</span> <span class="token number">8</span><span class="token punctuation">;</span>
<span class="token keyword">int</span> grid_h0 <span class="token operator">=</span> model_in_h <span class="token operator">/</span> stride0<span class="token punctuation">;</span> <span class="token comment">//计算目标检测的网格高度,通过将模型输入高度`model_in_h`除以步幅值`stride0`得到。</span>
<span class="token keyword">int</span> grid_w0 <span class="token operator">=</span> model_in_w <span class="token operator">/</span> stride0<span class="token punctuation">;</span> <span class="token comment">//计算目标检测的网格宽度</span>
<span class="token keyword">int</span> validCount0 <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> <span class="token comment">//validCount非常重要, 就是在80x80这个维度, 所有预测框中超过置信度阈值的总个数.</span>
<span class="token comment">//调用`process`函数,传递输入数据、锚框、网格高度、网格宽度、模型输入高度、模型输入宽度、步幅值、过滤框、目标概率、类别ID、置信度阈值、量化偏置和量化缩放等参数进行处理,并将处理后的有效目标数量赋值给`validCount0`。</span>
validCount0 <span class="token operator">=</span> <span class="token function">process</span><span class="token punctuation">(</span>input0<span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token keyword">int</span> <span class="token operator">*</span><span class="token punctuation">)</span>anchor0<span class="token punctuation">,</span> grid_h0<span class="token punctuation">,</span> grid_w0<span class="token punctuation">,</span> model_in_h<span class="token punctuation">,</span> model_in_w<span class="token punctuation">,</span> stride0<span class="token punctuation">,</span> filterBoxes<span class="token punctuation">,</span> objProbs<span class="token punctuation">,</span>
classId<span class="token punctuation">,</span> conf_threshold<span class="token punctuation">,</span> qnt_zps<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">,</span> qnt_scales<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token comment">// stride 16</span>
<span class="token keyword">int</span> stride1 <span class="token operator">=</span> <span class="token number">16</span><span class="token punctuation">;</span>
<span class="token keyword">int</span> grid_h1 <span class="token operator">=</span> model_in_h <span class="token operator">/</span> stride1<span class="token punctuation">;</span>
<span class="token keyword">int</span> grid_w1 <span class="token operator">=</span> model_in_w <span class="token operator">/</span> stride1<span class="token punctuation">;</span>
<span class="token keyword">int</span> validCount1 <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> <span class="token comment">//validCount非常重要, 就是在80x80这个维度, 所有预测框中超过置信度阈值的总个数.</span>
validCount1 <span class="token operator">=</span> <span class="token function">process</span><span class="token punctuation">(</span>input1<span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token keyword">int</span> <span class="token operator">*</span><span class="token punctuation">)</span>anchor1<span class="token punctuation">,</span> grid_h1<span class="token punctuation">,</span> grid_w1<span class="token punctuation">,</span> model_in_h<span class="token punctuation">,</span> model_in_w<span class="token punctuation">,</span> stride1<span class="token punctuation">,</span> filterBoxes<span class="token punctuation">,</span> objProbs<span class="token punctuation">,</span>
classId<span class="token punctuation">,</span> conf_threshold<span class="token punctuation">,</span> qnt_zps<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">,</span> qnt_scales<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token comment">// stride 32</span>
<span class="token keyword">int</span> stride2 <span class="token operator">=</span> <span class="token number">32</span><span class="token punctuation">;</span>
<span class="token keyword">int</span> grid_h2 <span class="token operator">=</span> model_in_h <span class="token operator">/</span> stride2<span class="token punctuation">;</span>
<span class="token keyword">int</span> grid_w2 <span class="token operator">=</span> model_in_w <span class="token operator">/</span> stride2<span class="token punctuation">;</span>
<span class="token keyword">int</span> validCount2 <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> <span class="token comment">//validCount非常重要, 就是在80x80这个维度, 所有预测框中超过置信度阈值的总个数.</span>
validCount2 <span class="token operator">=</span> <span class="token function">process</span><span class="token punctuation">(</span>input2<span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token keyword">int</span> <span class="token operator">*</span><span class="token punctuation">)</span>anchor2<span class="token punctuation">,</span> grid_h2<span class="token punctuation">,</span> grid_w2<span class="token punctuation">,</span> model_in_h<span class="token punctuation">,</span> model_in_w<span class="token punctuation">,</span> stride2<span class="token punctuation">,</span> filterBoxes<span class="token punctuation">,</span> objProbs<span class="token punctuation">,</span>
classId<span class="token punctuation">,</span> conf_threshold<span class="token punctuation">,</span> qnt_zps<span class="token punctuation">[</span><span class="token number">2</span><span class="token punctuation">]</span><span class="token punctuation">,</span> qnt_scales<span class="token punctuation">[</span><span class="token number">2</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">int</span> validCount <span class="token operator">=</span> validCount0 <span class="token operator">+</span> validCount1 <span class="token operator">+</span> validCount2<span class="token punctuation">;</span> <span class="token comment">//总的预测框数目</span>
<span class="token comment">// no object detect</span>
<span class="token keyword">if</span> <span class="token punctuation">(</span>validCount <span class="token operator"><=</span> <span class="token number">0</span><span class="token punctuation">)</span>
<span class="token punctuation">{<!-- --></span>
<span class="token keyword">return</span> <span class="token number">0</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
std<span class="token operator">::</span>vector<span class="token operator"><</span><span class="token keyword">int</span><span class="token operator">></span> indexArray<span class="token punctuation">;</span> <span class="token comment">//索引向量</span>
<span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">int</span> i <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> i <span class="token operator"><</span> validCount<span class="token punctuation">;</span> <span class="token operator">++</span>i<span class="token punctuation">)</span>
<span class="token punctuation">{<!-- --></span>
indexArray<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token comment">//根据目标概率objProbs, 对indexArray做一个排序.</span>
<span class="token function">quick_sort_indice_inverse</span><span class="token punctuation">(</span>objProbs<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> validCount <span class="token operator">-</span> <span class="token number">1</span><span class="token punctuation">,</span> indexArray<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token comment">//std::set<int>表示一组不重复、有序的整数集合。升序排列。</span>
std<span class="token operator">::</span>set<span class="token operator"><</span><span class="token keyword">int</span><span class="token operator">></span> <span class="token function">class_set</span><span class="token punctuation">(</span>std<span class="token operator">::</span><span class="token function">begin</span><span class="token punctuation">(</span>classId<span class="token punctuation">)</span><span class="token punctuation">,</span> std<span class="token operator">::</span><span class="token function">end</span><span class="token punctuation">(</span>classId<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> c <span class="token operator">:</span> class_set<span class="token punctuation">)</span> <span class="token comment">// `auto` 关键字是用来自动推导循环中元素的类型</span>
<span class="token punctuation">{<!-- --></span>
<span class="token comment">// 对每一个类比如person做非极大值抑制</span>
<span class="token function">nms</span><span class="token punctuation">(</span>validCount<span class="token punctuation">,</span> filterBoxes<span class="token punctuation">,</span> classId<span class="token punctuation">,</span> indexArray<span class="token punctuation">,</span> c<span class="token punctuation">,</span> nms_threshold<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">int</span> last_count <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span>
group<span class="token operator">-></span>count <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span>
<span class="token comment">/* box valid detect target */</span>
<span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">int</span> i <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> i <span class="token operator"><</span> validCount<span class="token punctuation">;</span> <span class="token operator">++</span>i<span class="token punctuation">)</span>
<span class="token punctuation">{<!-- --></span>
<span class="token keyword">if</span> <span class="token punctuation">(</span>indexArray<span class="token punctuation">[</span>i<span class="token punctuation">]</span> <span class="token operator">==</span> <span class="token operator">-</span><span class="token number">1</span> <span class="token operator">||</span> last_count <span class="token operator">>=</span> OBJ_NUMB_MAX_SIZE<span class="token punctuation">)</span>
<span class="token punctuation">{<!-- --></span>
<span class="token keyword">continue</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">int</span> n <span class="token operator">=</span> indexArray<span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">;</span>
<span class="token keyword">float</span> x1 <span class="token operator">=</span> filterBoxes<span class="token punctuation">[</span>n <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">-</span> pads<span class="token punctuation">.</span>left<span class="token punctuation">;</span>
<span class="token keyword">float</span> y1 <span class="token operator">=</span> filterBoxes<span class="token punctuation">[</span>n <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">-</span> pads<span class="token punctuation">.</span>top<span class="token punctuation">;</span>
<span class="token keyword">float</span> x2 <span class="token operator">=</span> x1 <span class="token operator">+</span> filterBoxes<span class="token punctuation">[</span>n <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">2</span><span class="token punctuation">]</span><span class="token punctuation">;</span>
<span class="token keyword">float</span> y2 <span class="token operator">=</span> y1 <span class="token operator">+</span> filterBoxes<span class="token punctuation">[</span>n <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">3</span><span class="token punctuation">]</span><span class="token punctuation">;</span>
<span class="token keyword">int</span> id <span class="token operator">=</span> classId<span class="token punctuation">[</span>n<span class="token punctuation">]</span><span class="token punctuation">;</span>
<span class="token keyword">float</span> obj_conf <span class="token operator">=</span> objProbs<span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">;</span>
group<span class="token operator">-></span>results<span class="token punctuation">[</span>last_count<span class="token punctuation">]</span><span class="token punctuation">.</span>box<span class="token punctuation">.</span>left <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token keyword">int</span><span class="token punctuation">)</span><span class="token punctuation">(</span><span class="token function">clamp</span><span class="token punctuation">(</span>x1<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> model_in_w<span class="token punctuation">)</span> <span class="token operator">/</span> scale_w<span class="token punctuation">)</span><span class="token punctuation">;</span>
group<span class="token operator">-></span>results<span class="token punctuation">[</span>last_count<span class="token punctuation">]</span><span class="token punctuation">.</span>box<span class="token punctuation">.</span>top <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token keyword">int</span><span class="token punctuation">)</span><span class="token punctuation">(</span><span class="token function">clamp</span><span class="token punctuation">(</span>y1<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> model_in_h<span class="token punctuation">)</span> <span class="token operator">/</span> scale_h<span class="token punctuation">)</span><span class="token punctuation">;</span>
group<span class="token operator">-></span>results<span class="token punctuation">[</span>last_count<span class="token punctuation">]</span><span class="token punctuation">.</span>box<span class="token punctuation">.</span>right <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token keyword">int</span><span class="token punctuation">)</span><span class="token punctuation">(</span><span class="token function">clamp</span><span class="token punctuation">(</span>x2<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> model_in_w<span class="token punctuation">)</span> <span class="token operator">/</span> scale_w<span class="token punctuation">)</span><span class="token punctuation">;</span>
group<span class="token operator">-></span>results<span class="token punctuation">[</span>last_count<span class="token punctuation">]</span><span class="token punctuation">.</span>box<span class="token punctuation">.</span>bottom <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token keyword">int</span><span class="token punctuation">)</span><span class="token punctuation">(</span><span class="token function">clamp</span><span class="token punctuation">(</span>y2<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> model_in_h<span class="token punctuation">)</span> <span class="token operator">/</span> scale_h<span class="token punctuation">)</span><span class="token punctuation">;</span>
group<span class="token operator">-></span>results<span class="token punctuation">[</span>last_count<span class="token punctuation">]</span><span class="token punctuation">.</span>prop <span class="token operator">=</span> obj_conf<span class="token punctuation">;</span>
<span class="token keyword">char</span> <span class="token operator">*</span>label <span class="token operator">=</span> labels<span class="token punctuation">[</span>id<span class="token punctuation">]</span><span class="token punctuation">;</span>
<span class="token function">strncpy</span><span class="token punctuation">(</span>group<span class="token operator">-></span>results<span class="token punctuation">[</span>last_count<span class="token punctuation">]</span><span class="token punctuation">.</span>name<span class="token punctuation">,</span> label<span class="token punctuation">,</span> OBJ_NAME_MAX_SIZE<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token comment">// printf("result %2d: (%4d, %4d, %4d, %4d), %s\n", i, group->results[last_count].box.left,</span>
<span class="token comment">// group->results[last_count].box.top,</span>
<span class="token comment">// group->results[last_count].box.right, group->results[last_count].box.bottom, label);</span>
last_count<span class="token operator">++</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
group<span class="token operator">-></span>count <span class="token operator">=</span> last_count<span class="token punctuation">;</span>
<span class="token keyword">return</span> <span class="token number">0</span><span class="token punctuation">;</span>
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
后处理中所用函数如下:
(1)读取标签,存储到label数组中。
#define OBJ_CLASS_NUM 80
//clamp 函数用于限制 val 的取值在 min 和 max 之间。
inline static int clamp(float val, int min, int max) { return val > min ? (val < max ? val : max) : min; }
//函数用于从文件中读取一行内容。它会动态地分配内存来存储读取的行,并在读取结束时返回一个指向该行的指针。
//如果读取失败或遇到内存分配问题,则返回 NULL。
char readLine(FILE fp, char buffer, int len)
{
int ch;
int i = 0;
size_t buff_len = 0;
buffer = (char *)malloc(buff_len + 1);
if (!buffer)
return NULL; // Out of memory
while ((ch = fgetc(fp)) != ‘\n’ && ch != EOF)
{
buff_len++;
void tmp = realloc(buffer, buff_len + 1);
if (tmp == NULL)
{
free(buffer);
return NULL; // Out of memory
}
buffer = (char )tmp;
buffer<span class="token punctuation">[</span>i<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token keyword">char</span><span class="token punctuation">)</span>ch<span class="token punctuation">;</span>
i<span class="token operator">++</span><span class="token punctuation">;</span>
}
buffer[i] = ‘\0’;
*len = buff_len;
// Detect end
if (ch EOF && (i 0 || ferror(fp)))
{
free(buffer);
return NULL;
}
return buffer;
}
//于从指定文件中读取多行内容,并将每行存储在一个字符串中,然后将所有行存储在一个字符串数组中。它会循环调用 readLine 函数来读取文件中的每一行,直到文件结束或达到最大行数。
//读取过程中会动态地分配内存来存储每行内容,并将指向每行的指针存储在 lines 数组中。读取完成后,函数会关闭文件并返回读取的行数。
int readLines(const char fileName, char lines[], int max_line)
{
FILE file = fopen(fileName, “r”);
char s;
int i = 0;
int n = 0;
if (file == NULL)
{
printf(“Open %s fail!\n”, fileName);
return -1;
}
while ((s = readLine(file, s, &n)) != NULL)
{
lines[i++] = s;
if (i >= max_line)
break;
}
fclose(file);
return i;
}
//加载包含类别标签名称的文本文件。它调用 readLines 函数从指定的文件中读取类别标签,并将每个标签存储在 label 数组中。
int loadLabelName(const char locationFilename, char label[])
{
printf(“loadLabelName %s\n”, locationFilename);
readLines(locationFilename, label, OBJ_CLASS_NUM);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
(2)量化与反量化
这些函数提供了在浮点数和固定点数表示之间进行转换的功能,有助于在嵌入式设备或者硬件加速器上进行模型推理时的性能优化和资源节约。
假设我们有一个神经网络模型,输出层包含三个节点,每个节点都输出一个浮点数作为结果。现在,我们模型放在嵌入式设备上进行后续处理,为了提高计算效率并节省内存消耗,我们可以使用量化函数将这些浮点数转换为固定点数(整型)。首先需要确定固定点数的缩放因子(scale)和零点(zp),并通过量化函数将浮点数转为整型数据。这样可以提高计算效率并节省内存消耗。
//__clip 函数用于将输入值 val 限制在指定的范围内 [min, max],如果 val 小于 min,则返回 min;如果 val 大于 max,则返回 max;否则返回 val 本身。
inline static int32_t __clip(float val, float min, float max)
{
float f = val <= min ? min : (val >= max ? max : val);
return f;
}
//函数将浮点数 f32 进行量化,使用了仿射变换的方法。
//首先,它将输入值 f32 除以量化尺度 scale,然后加上量化零点 zp,得到量化后的值 dst_val。最后,将 dst_val 限制在 [-128, 127] 的范围内,并返回结果。
static int8_t qnt_f32_to_affine(float f32, int32_t zp, float scale)
{
float dst_val = (f32 / scale) + zp;
int8_t res = (int8_t)__clip(dst_val, -128, 127);
return res;
}
//将量化后的固定点表示 qnt 反量化为浮点数,使用了仿射变换的逆过程。
//首先,将量化后的值 qnt 减去量化零点 zp,然后乘以量化尺度 scale,得到反量化后的浮点数值,并返回结果。
static float deqnt_affine_to_f32(int8_t qnt, int32_t zp, float scale)
{
return ((float)qnt - (float)zp) * scale;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(3)这段代码是一个用于处理神经网络模型输出的函数,用于解析模型输出并提取检测到的目标框及其相关信息。
/* int8_t *input:输入数据为int8类型的。 int *anchor :锚框。锚框的参数,宽度和高度等。 int grid_h, int grid_w :目标检测的网格高度和宽度。 int height, int width :模型的高度和宽度 int stride :这是一个表示步幅(stride)的整数,用于定义网格的间距。 std::vector<float> &boxes :用于存储检测到的目标的边界框(bounding box)信息,如位置和尺寸。 std::vector<float> &objProbs :用于存储检测到的目标的概率或置信度。 std::vector<int> &classId :用于存储检测到的目标所属的类别或类别索引。 float threshold :阈值参数,用于过滤检测结果中置信度低于阈值的目标。 int32_t zp : 输入数据进行零偏移(zero point)调整。(量化参数) float scale : 输入数据进行缩放调整。(量化参数) */ static int process(int8_t *input, int *anchor, int grid_h, int grid_w, int height, int width, int stride, std::vector<float> &boxes, std::vector<float> &objProbs, std::vector<int> &classId, float threshold, int32_t zp, float scale) { int validCount = 0; int grid_len = grid_h * grid_w; int8_t thres_i8 = qnt_f32_to_affine(threshold, zp, scale); for (int a = 0; a < 3; a++) { for (int i = 0; i < grid_h; i++) { for (int j = 0; j < grid_w; j++) { int8_t box_confidence = input[(PROP_BOX_SIZE * a + 4) * grid_len + i * grid_w + j]; if (box_confidence >= thres_i8) { int offset = (PROP_BOX_SIZE * a) * grid_len + i * grid_w + j; int8_t *in_ptr = input + offset; float box_x = (deqnt_affine_to_f32(*in_ptr, zp, scale)) * 2.0 - 0.5; float box_y = (deqnt_affine_to_f32(in_ptr[grid_len], zp, scale)) * 2.0 - 0.5; float box_w = (deqnt_affine_to_f32(in_ptr[2 * grid_len], zp, scale)) * 2.0; float box_h = (deqnt_affine_to_f32(in_ptr[3 * grid_len], zp, scale)) * 2.0; box_x = (box_x + j) * (float)stride; box_y = (box_y + i) * (float)stride; box_w = box_w * box_w * (float)anchor[a * 2]; box_h = box_h * box_h * (float)anchor[a * 2 + 1]; box_x -= (box_w / 2.0); box_y -= (box_h / 2.0);<span class="token class-name">int8_t</span> maxClassProbs <span class="token operator">=</span> in_ptr<span class="token punctuation">[</span><span class="token number">5</span> <span class="token operator">*</span> grid_len<span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token keyword">int</span> maxClassId <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">int</span> k <span class="token operator">=</span> <span class="token number">1</span><span class="token punctuation">;</span> k <span class="token operator"><</span> OBJ_CLASS_NUM<span class="token punctuation">;</span> <span class="token operator">++</span>k<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token class-name">int8_t</span> prob <span class="token operator">=</span> in_ptr<span class="token punctuation">[</span><span class="token punctuation">(</span><span class="token number">5</span> <span class="token operator">+</span> k<span class="token punctuation">)</span> <span class="token operator">*</span> grid_len<span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>prob <span class="token operator">></span> maxClassProbs<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> maxClassId <span class="token operator">=</span> k<span class="token punctuation">;</span> maxClassProbs <span class="token operator">=</span> prob<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>maxClassProbs <span class="token operator">></span> thres_i8<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> objProbs<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token function">deqnt_affine_to_f32</span><span class="token punctuation">(</span>maxClassProbs<span class="token punctuation">,</span> zp<span class="token punctuation">,</span> scale<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token operator">*</span> <span class="token punctuation">(</span><span class="token function">deqnt_affine_to_f32</span><span class="token punctuation">(</span>box_confidence<span class="token punctuation">,</span> zp<span class="token punctuation">,</span> scale<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> classId<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>maxClassId<span class="token punctuation">)</span><span class="token punctuation">;</span> validCount<span class="token operator">++</span><span class="token punctuation">;</span> boxes<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>box_x<span class="token punctuation">)</span><span class="token punctuation">;</span> boxes<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>box_y<span class="token punctuation">)</span><span class="token punctuation">;</span> boxes<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>box_w<span class="token punctuation">)</span><span class="token punctuation">;</span> boxes<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>box_h<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span>
}
return validCount;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
(4)数组快速排序
实现了对输入数组的快速排序,并且根据排序结果对另一个数组中的元素进行重新排列,以保持两个数组之间的关联关系。在排序过程中,indices 数组的元素顺序会跟随 input 数组的排序而变化,但它们始终保持了对应关系,即 indices[i] 存储了原始数组中第 i 个元素的索引。这样做的目的是在排序后,可以根据 indices 数组的顺序快速找到原始数据对应的索引位置,以便进一步操作原始数据
static int quick_sort_indice_inverse(std::vector<float> &input, int left, int right, std::vector<int> &indices)
{
float key;
int key_index;
int low = left;
int high = right;
if (left < right)
{
key_index = indices[left];
key = input[left];
while (low < high)
{
while (low < high && input[high] <= key)
{
high--;
}
input[low] = input[high];
indices[low] = indices[high];
while (low < high && input[low] >= key)
{
low++;
}
input[high] = input[low];
indices[high] = indices[low];
}
input[low] = key;
indices[low] = key_index;
quick_sort_indice_inverse(input, left, low - 1, indices);
quick_sort_indice_inverse(input, low + 1, right, indices);
}
return low;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
(5)NMS非极大值抑制函数。
在目标检测任务中,用于消除多次检测到同一个目标的冗余框。NMS通过保留置信度最高的框,并删除与其重叠较大的其他框,从而减少重复检测。
/*输入参数: validCount:表示有效的框的数量。 outputLocations:存储目标框位置信息的向量,每个目标框由4个值表示:左上角点的x坐标、y坐标以及目标框的宽度和高度。 classIds:存储目标框对应的类别标签。 order:存储目标框的索引,按照置信度降序排列。 filterId:需要过滤的类别标签。 threshold:IOU(交并比)阈值,用于判断两个框是否重叠。 */ static int nms(int validCount, std::vector<float> &outputLocations, std::vector<int> classIds, std::vector<int> &order, int filterId, float threshold) { for (int i = 0; i < validCount; ++i) { if (order[i] == -1 || classIds[i] != filterId) { continue; } int n = order[i]; for (int j = i + 1; j < validCount; ++j) { int m = order[j]; if (m == -1 || classIds[i] != filterId) { continue; } float xmin0 = outputLocations[n * 4 + 0]; float ymin0 = outputLocations[n * 4 + 1]; float xmax0 = outputLocations[n * 4 + 0] + outputLocations[n * 4 + 2]; float ymax0 = outputLocations[n * 4 + 1] + outputLocations[n * 4 + 3];<span class="token keyword">float</span> xmin1 <span class="token operator">=</span> outputLocations<span class="token punctuation">[</span>m <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token keyword">float</span> ymin1 <span class="token operator">=</span> outputLocations<span class="token punctuation">[</span>m <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token keyword">float</span> xmax1 <span class="token operator">=</span> outputLocations<span class="token punctuation">[</span>m <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">+</span> outputLocations<span class="token punctuation">[</span>m <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">2</span><span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token keyword">float</span> ymax1 <span class="token operator">=</span> outputLocations<span class="token punctuation">[</span>m <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">+</span> outputLocations<span class="token punctuation">[</span>m <span class="token operator">*</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">3</span><span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token keyword">float</span> iou <span class="token operator">=</span> <span class="token function">CalculateOverlap</span><span class="token punctuation">(</span>xmin0<span class="token punctuation">,</span> ymin0<span class="token punctuation">,</span> xmax0<span class="token punctuation">,</span> ymax0<span class="token punctuation">,</span> xmin1<span class="token punctuation">,</span> ymin1<span class="token punctuation">,</span> xmax1<span class="token punctuation">,</span> ymax1<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>iou <span class="token operator">></span> threshold<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> order<span class="token punctuation">[</span>j<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span>
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
nms阈值检测中所用函数:
static float CalculateOverlap(float xmin0, float ymin0, float xmax0, float ymax0, float xmin1, float ymin1, float xmax1,
float ymax1)
{
float w = fmax(0.f, fmin(xmax0, xmax1) - fmax(xmin0, xmin1) + 1.0);
float h = fmax(0.f, fmin(ymax0, ymax1) - fmax(ymin0, ymin1) + 1.0);
float i = w * h;
float u = (xmax0 - xmin0 + 1.0) * (ymax0 - ymin0 + 1.0) + (xmax1 - xmin1 + 1.0) * (ymax1 - ymin1 + 1.0) - i;
return u <= 0.f ? 0.f : (i / u);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
五、画框和概率
在检测结果处理后(后处理完成),将检测结果绘制在图像上的过程。它首先从检测结果集中获取每个检测结果,然后在原始图像上绘制边界框和标签文本。
typedef struct __detect_result_t
{
char name[OBJ_NAME_MAX_SIZE]; //检测结果类别名称
BOX_RECT box; //识别框
float prop; //置信度
} detect_result_t;
char text[256]; // 用于存储要显示的文本信息
for (int i = 0; i < detect_result_group.count; i++) // 遍历所有检测结果
{
detect_result_t det_result = &(detect_result_group.results[i]); // 获取第 i 个检测结果的指针
sprintf(text, “%s %.1f%%”, det_result->name, det_result->prop 100); // 将检测结果的类别名和置信度格式化为文本
// 打印检测结果的信息,包括类别名、边界框坐标和置信度
printf(“%s : (%d %d %d %d) %f\n”, det_result->name, det_result->box.left, det_result->box.top,
det_result->box.right, det_result->box.bottom, det_result->prop);
// 获取边界框的左上角和右下角的坐标
int x1 = det_result->box.left;
int y1 = det_result->box.top;
int x2 = det_result->box.right;
int y2 = det_result->box.bottom;
// 在原始图像上绘制边界框。 cv::Scalar(256, 0, 0, 256):前三个参数为BGR,最后一个为透明度。 3:线粗
rectangle(orig_img, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(256, 0, 0, 256), 3);
// 在边界框的左上角绘制类别名和置信度
//字体为 cv::FONT_HERSHEY_SIMPLEX,字体缩放因子为 0.4,颜色为白色
putText(orig_img, text, cv::Point(x1, y1 + 12), cv::FONT_HERSHEY_SIMPLEX, 0.4, cv::Scalar(255, 255, 255));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
六、保存画框后的输出结果
//这段代码首先打印一条消息,告知用户检测结果将保存到指定路径。接着,它将包含检测结果的图像保存到该路径。最后,它释放用于存储推理输出的内存,以防止内存泄漏。完整的流程从检测到结果保存,确保了内存管理的正确性和检测结果的持久化。
std::string out_path = "./out.jpg";
//在 printf 函数中,%s 格式符期望一个 C 风格字符串作为参数,所以我们使用 out_path.c_str() 来传递 C 风格的路径字符串给 printf。即将c++风格字符串变为c风格字符串。
printf("save detect result to %s\n", out_path.c_str());
imwrite(out_path, orig_img); //将orig_img图像保存到路径下。
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);//释放输出资源。以便进行下一次推理或结束程序时释放内存,防止资源泄露。
- 1
- 2
- 3
- 4
- 5
- 6
七、推理性能测试
通过循环执行多次推理,可以评估模型在不同输入上的平均推理时间。这对于评估模型的实时性能和优化推理过程中的性能提升非常有用。
int test_count = 10; //测试次数
#define PERF_WITH_POST 1 //是否执行后处理
gettimeofday(&start_time, NULL); //记录开始时间
for (int i = 0; i < test_count; ++i)
{
rknn_inputs_set(ctx, io_num.n_input, inputs); //设置模型输入
ret = rknn_run(ctx, NULL); //进行推理
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL); //获取模型输出
#if PERF_WITH_POST
post_process((int8_t )outputs[0].buf, (int8_t )outputs[1].buf, (int8_t *)outputs[2].buf, height, width,
box_conf_threshold, nms_threshold, pads, scale_w, scale_h, out_zps, out_scales, &detect_result_group);
#endif
ret = rknn_outputs_release(ctx, io_num.n_output, outputs); //释放模型输出资源,以便进行下一次推理或结束程序时释放内存,防止资源泄露。
}
gettimeofday(&stop_time, NULL); //获取结束时间
printf(“loop count = %d , average run %f ms\n”, test_count,
(__get_us(stop_time) - __get_us(start_time)) / 1000.0 / test_count); //打印平均耗时
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
获取us函数:
double __get_us(struct timeval t)
{
return (t.tv_sec * 1000000 + t.tv_usec);
}
- 1
- 2
- 3
- 4
八、释放资源
在程序结束或不再需要使用分配的内存时,就可以手动来释放资源,防止内存泄漏。
内存泄漏指的是在程序运行期间分配了内存空间,但在不再需要使用这些内存空间时未将其释放的情况。这会导致程序持续消耗内存,最终可能耗尽系统的可用内存,导致程序崩溃或系统变慢。
deinitPostProcess(); //释放标签内存
// 销毁创建的RKNN上下文ctx,释放与其相关的资源。
ret = rknn_destroy(ctx);
if (model_data) //释放加载模型时的模型数据。
{
free(model_data);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上述使用代码:释放标签内存函数
void deinitPostProcess()
{
for (int i = 0; i < OBJ_CLASS_NUM; i++)
{
if (labels[i] != nullptr)
{
free(labels[i]); //labels在后处理中定义
labels[i] = nullptr;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
附录:自定义yolov5模型与官方模型转为onnx输出对比
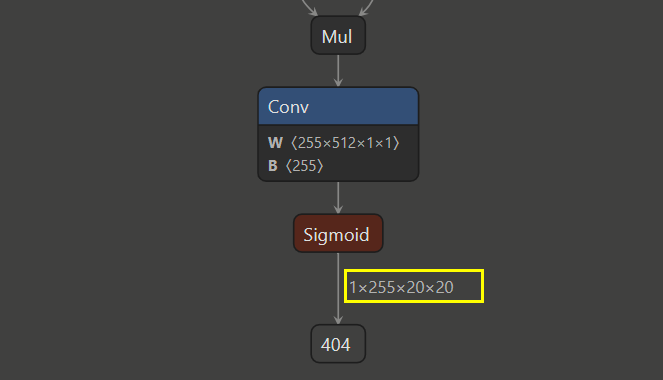
模型1:官方.pt模型转为的onnx模型。
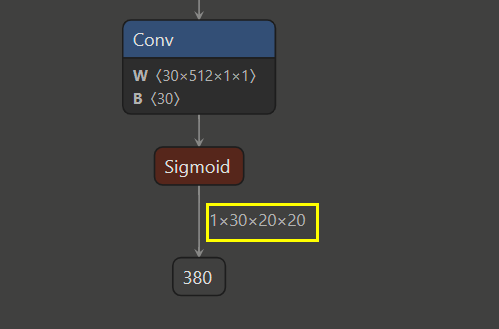
模型2:自训练模型转为的onnx模型。
问题:我们发现上面的模型之前的每一步都相同,为什么输出不同呢?
答:这肯定与模型的结构有关。于是我就发现原来模型的最后一层卷积是与设置的类别数量有关。模型的定义在yolo.py文件。
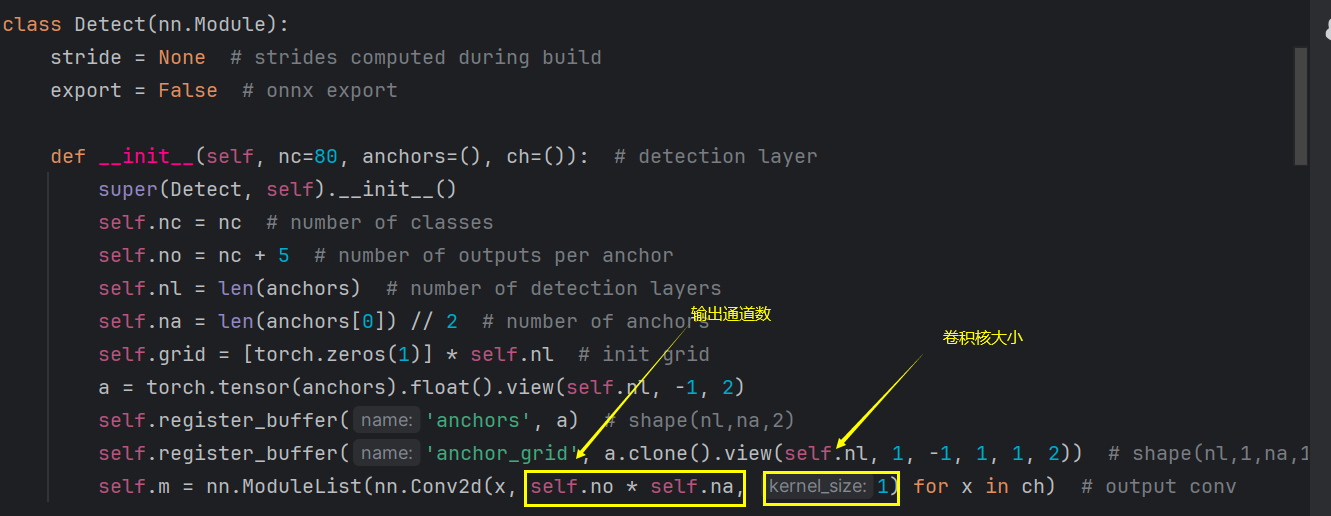
self.nc = nc:表示类别数,即目标检测任务中的类别数量。
self.no = nc + 5:表示每个锚点的输出数,通常为类别数加上5,其中5是指目标的坐标信息(4个)和置信度分数(1个)。
self.na = len(anchors[0]) // 2 :这里为每个检测层锚点的个数。每个锚点由两个值表示,所以要除2。
因为我们的模型是通过train.py进行训练的,所以我们可以查看一下其参数来源。我们发现参数是由我们自定义的yaml文件提供的,所以我们来查看一下这两个文件里面的内容。

yolov5_thing.yaml文件里下面这里是类别数量。
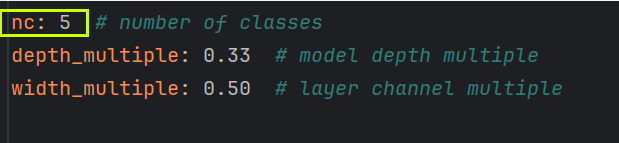
下面anchors 列表中每个子列表包含了每个检测层对应的锚点。每个锚点由两个值表示,分别是它在特征图上的宽度和高度的相对像素值。所以每个检测出都有三个锚点。
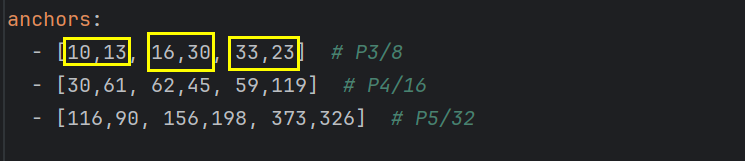
同时也要对应修改thing.yaml文件里的类别数。注意:这里names的个数要等于类别数。
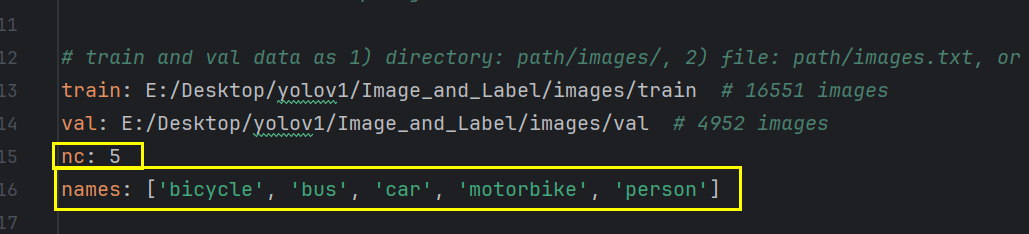
根据上面内容可得:模型输出的通道数=3*(5+5)=30。
所以这样我们就知道了为什么我们的模型输出通道数为30,而不是255了。那为什么官方的模型通道为255呢?因为官方的类别数量为80,所以其通道数为3*(80+5)=255。















 1638
1638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









