






接上回,接下来就到了大家关心的RKNN部分的操作啦,接下来看代码。
create_rknn_list(&rknn_list_);
// Get the sub-stream buffer for humanoid recognition
pthread_t read_thread;
pthread_create(&read_thread, NULL, GetMediaBuffer, NULL); //RKNN主线程static void *GetMediaBuffer(void *arg) {
printf("#Start %s thread, arg:%p\n", __func__, arg);
rknn_context ctx;
int ret;
int model_len = 0;
unsigned char *model;
printf("Loading model ...\n");
model = load_model(g_ssd_path, &model_len);
ret = rknn_init(&ctx, model, model_len, 0);
if (ret < 0) {
printf("rknn_init fail! ret=%d\n", ret);
return NULL;
}
// Get Model Input Output Info
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret != RKNN_SUCC) {
printf("rknn_query fail! ret=%d\n", ret);
return NULL;
}
printf("model input num: %d, output num: %d\n", io_num.n_input,
io_num.n_output);
printf("input tensors:\n");
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (unsigned int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]),
sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC) {
printf("rknn_query fail! ret=%d\n", ret);
return NULL;
}
printRKNNTensor(&(input_attrs[i]));
}
printf("output tensors:\n");
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (unsigned int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]),
sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC) {
printf("rknn_query fail! ret=%d\n", ret);
return NULL;
}
printRKNNTensor(&(output_attrs[i]));
}
MEDIA_BUFFER buffer = NULL;
while (g_flag_run) {
buffer = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, RK_NN_INDEX, -1);
if (!buffer) {
continue;
}
// printf("Get Frame:ptr:%p, fd:%d, size:%zu, mode:%d, channel:%d, "
// "timestamp:%lld\n",
// RK_MPI_MB_GetPtr(buffer), RK_MPI_MB_GetFD(buffer),
// RK_MPI_MB_GetSize(buffer),
// RK_MPI_MB_GetModeID(buffer), RK_MPI_MB_GetChannelID(buffer),
// RK_MPI_MB_GetTimestamp(buffer));
// nv12 to rgb24 and resize
int rga_buffer_size = cfg.session_cfg[RK_NN_INDEX].u32Width *
cfg.session_cfg[RK_NN_INDEX].u32Height *
3; // nv12 3/2, rgb 3
int rga_buffer_model_input_size = MODEL_INPUT_SIZE * MODEL_INPUT_SIZE * 3;
unsigned char *rga_buffer = malloc(rga_buffer_size);
unsigned char *rga_buffer_model_input = malloc(rga_buffer_model_input_size);
nv12_to_rgb24(RK_MPI_MB_GetPtr(buffer), rga_buffer,
cfg.session_cfg[RK_NN_INDEX].u32Width,
cfg.session_cfg[RK_NN_INDEX].u32Height);
rgb24_resize(rga_buffer, rga_buffer_model_input,
cfg.session_cfg[RK_NN_INDEX].u32Width,
cfg.session_cfg[RK_NN_INDEX].u32Height, MODEL_INPUT_SIZE,
MODEL_INPUT_SIZE);
// Set Input Data
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].size = rga_buffer_model_input_size;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].buf = rga_buffer_model_input;
ret = rknn_inputs_set(ctx, io_num.n_input, inputs);
if (ret < 0) {
printf("rknn_input_set fail! ret=%d\n", ret);
return NULL;
}
// Run
printf("rknn_run\n");
ret = rknn_run(ctx, NULL);
if (ret < 0) {
printf("rknn_run fail! ret=%d\n", ret);
return NULL;
}
// Get Output
rknn_output outputs[2];
memset(outputs, 0, sizeof(outputs));
outputs[0].want_float = 1;
outputs[1].want_float = 1;
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
if (ret < 0) {
printf("rknn_outputs_get fail! ret=%d\n", ret);
return NULL;
}
// Post Process
detect_result_group_t detect_result_group;
postProcessSSD((float *)(outputs[0].buf), (float *)(outputs[1].buf),
MODEL_INPUT_SIZE, MODEL_INPUT_SIZE, &detect_result_group);
// Release rknn_outputs
rknn_outputs_release(ctx, 2, outputs);
// Dump Objects
// for (int i = 0; i < detect_result_group.count; i++) {
// detect_result_t *det_result = &(detect_result_group.results[i]);
// printf("%s @ (%d %d %d %d) %f\n", det_result->name,
// det_result->box.left,
// det_result->box.top, det_result->box.right,
// det_result->box.bottom,
// det_result->prop);
// }
if (detect_result_group.count > 0) {
rknn_list_push(rknn_list_, getCurrentTimeMsec(), detect_result_group);
int size = rknn_list_size(rknn_list_);
if (size >= MAX_RKNN_LIST_NUM)
rknn_list_drop(rknn_list_);
// printf("size is %d\n", size);
}
RK_MPI_MB_ReleaseBuffer(buffer);
if (rga_buffer)
free(rga_buffer);
if (rga_buffer_model_input)
free(rga_buffer_model_input);
}
// release
if (ctx)
rknn_destroy(ctx);
if (model)
free(model);
return NULL;
}这部分代码我就不写注释了,大家先看英文注释吧,我在这理一下这部分做了什么。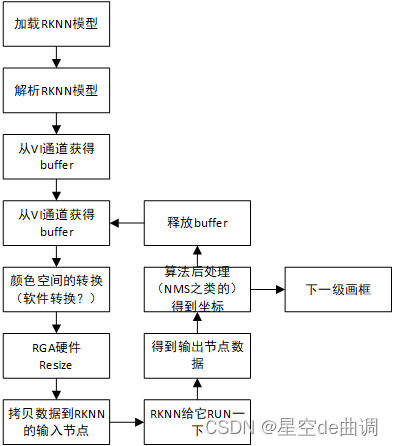
总的来说,就是模型加载后一直循环,取VI的帧数据,这边有点不解,为啥在RGA有能力处理颜色转换的情况下要用软件处理?我想过内存拷贝速度的问题,但是应该软件和硬件处理没啥速度上的区别,有大佬清楚原因不?















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









