







输入
bottom: 'rpn_cls_score' //1*24*64*64
bottom: 'gt_boxes' //标注坐标信息
bottom: 'im_info' //图像信息
bottom: 'data' //没用到
输出
top: 'rpn_labels' //1*1*(12*64)*64,IOU大于0.7为1,小于0.3为0,其他为-1不关注
top: 'rpn_bbox_targets' //1*(12*4)*64*64
top: 'rpn_bbox_inside_weights' //shape同label,label=1的为1,否则为0
top: 'rpn_bbox_outside_weights' //shape同上,label=-1的为0,其余为1/[num(bg)+num(fg)]
im_info存放图片尺寸及缩放比例。
label的shape 1*1*(12*64)*64,首先对应64*64的feature map 的形状,每个坐标点有7*6 个anchor(这是pvanet的数据,faster rcnn是4*3=12)。
inside_weight略去了判断为背景的框,outside_weight是归一化系数,这两个在smoothL1loss里用到。
2.softmaxwithloss layer
参考文章:http://blog.csdn.net/shuzfan/article/details/51460895
Loss Function
softmax_loss的计算包含2步:
(1)计算softmax归一化概率
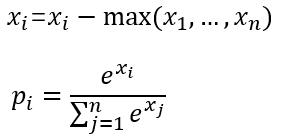
(2)计算损失
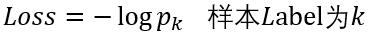
这里以batchsize=1的2分类为例:
设最后一层的输出为[1.2 0.8],减去最大值后为[0 -0.4],
然后计算归一化概率得到[0.5987 0.4013],
假如该图片的label为1,则Loss=-log0.4013=0.9130
可选参数
(1) ignore_label
int型变量,默认为空。
如果指定值,则label等于ignore_label的样本将不参与Loss计算,并且反向传播时梯度直接置0.
(2) normalize
bool型变量,即Loss会除以参与计算的样本总数;否则Loss等于直接求和
(3) normalization
enum型变量,默认为VALID,具体代表情况如下面的代码。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
归一化case的判断:
(1) 如果未设置normalization,但是设置了normalize。
则有normalize==1 -> 归一化方式为VALID
normalize==0 -> 归一化方式为BATCH_SIZE
(2) 一旦设置normalization,归一化方式则由normalization决定,不再考虑normalize。
使用方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
扩展使用
(1) 如上面的使用方法中所示,softmax_loss可以有2个输出,第二个输出为归一化后的softmax概率
(2) 最常见的情况是,一个样本对应一个标量label,但softmax_loss支持更高维度的label。
当bottom[0]的输入维度为N*C*H*W时,
其中N为一个batch中的样本数量,C为channel通常等于分类数,H*W为feature_map的大小通常它们等于1.
此时我们的一个样本对应的label不再是一个标量了,而应该是一个长度为H*W的矢量,里面的数值范围为0——C-1之间的整数。
至于之后的Loss计算,则采用相同的处理。
3. smoothL1loss layer
参考文章:http://blog.csdn.net/xyy19920105/article/details/50421225
在论文里给出的总loss公式
smoothL1loss是后半部分,其中,R的公式
,i是mini-batch(一张图上所有anchor)的anchor的索引。
最终代码里实现的loss公式是wout∗Smoothl1(win∗(b0−b1)),已经有inside_weight滤掉背景,outside_weight归一化,但是代码里最后还是除了一个=bottom->num(),如下
caffe_gpu_dot(count, ones_.gpu_data(), errors_.gpu_data(), &loss);
top[0]->mutable_cpu_data()[0] = loss / bottom[0]->num();这个地方存疑。
4.proposal layer
取top k个score最高的proposal,输出形状(k,5),其中5分成(img_id,x,y,h,w),img_id全为0,因为batch_size为0 。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









