




文章目录
FasterRCNN网络结构:
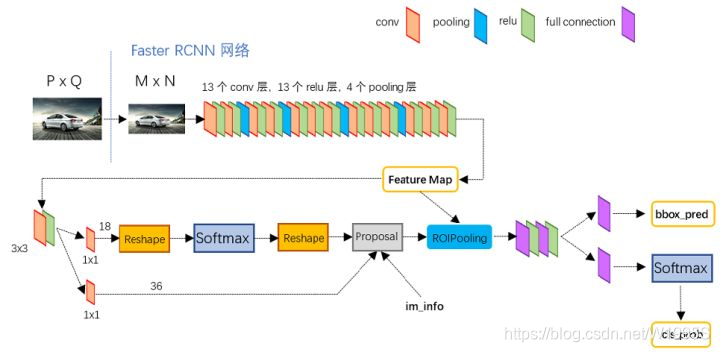
Faster RCNN可以分为4个主要内容
1、Conv layers。
特征提取网络Backbone。Faster RCNN首先使用一组基础conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
2、Region Proposal Networks。
RPN网络用于生成proposals(建议框)。该层通过softmax判断anchors(先验框)属于foreground或者background,利用bounding box regression修正anchors获得精确的proposals。
3、RoI Pooling。
该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续Fast RCNN全连接层判定目标类别。
4、Classification。
利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
1、Conv layers
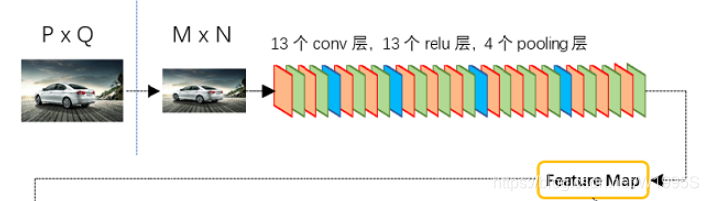
对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;Conv layers中包含了13个conv层+13个relu层+4个pooling层;且:
- 所有的conv层都是:kernel_size=3,pad=1
- 所有的pooling层都是:kernel_size=2,stride=2
在整个Conv layers中,conv和relu层不改变输入输出大小,只有pooling层使输出长宽都变为输入的1/2。一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16)。这样Conv layers生成的featuure map中都可以和原图对应起来。以VGG16为例,假设输入图像的维度为3X600X800,由于VGG16下采样率为16,因此输出的feature map的维度为512X38X 50。
2、RPN模块
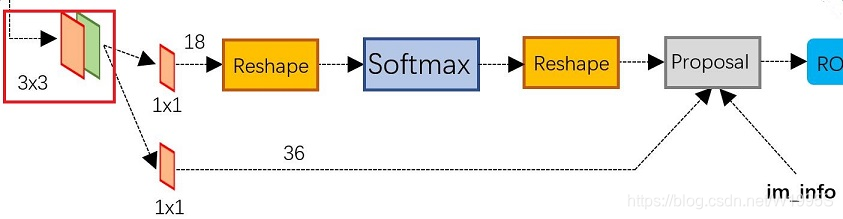
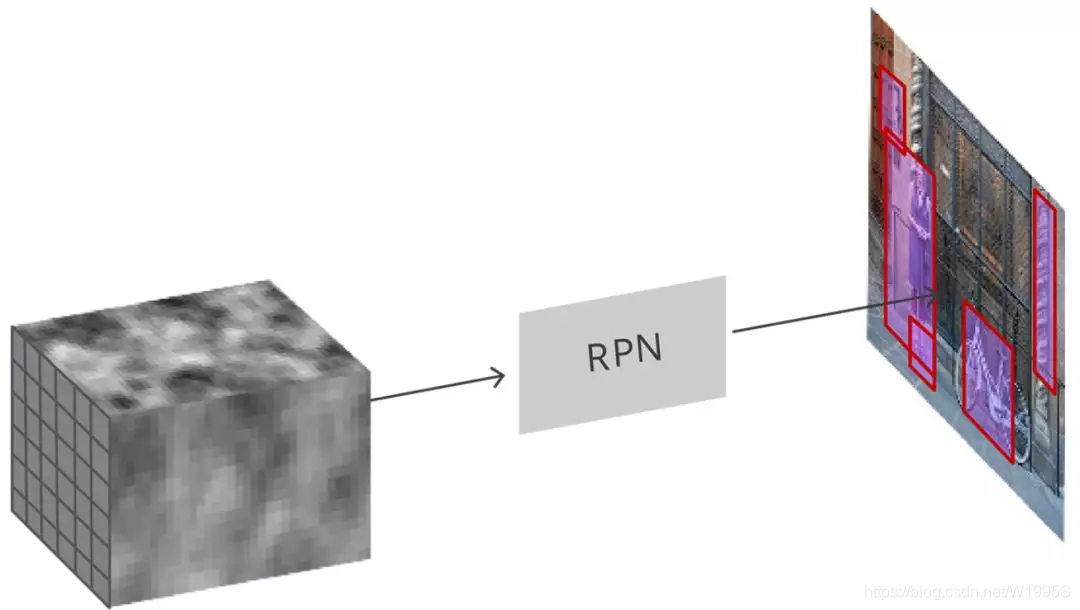 RPN 采用卷积特征图并在图像上生成proposal。
RPN 采用卷积特征图并在图像上生成proposal。
RPN网络: 生成较好的建议框proposal,这里用到了强先验的Anchor。
输入: feature map、 物体标签GT,即训练集中所有物体的类别与边框位置。
输出: Proposal、 分类Loss、 回归Loss, 其中,Proposal作为生成的区域,供后续模块分类与回归。两部分损失用作优化网络。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1296
1296





 到【灌水乐园】发言
到【灌水乐园】发言







