




 本文介绍如何使用Go语言实现Raft一致性算法。通过实验理解分布式系统中Raft算法的工作原理,包括领导选举、日志复制及安全性保障。文中详细解释了Raft节点的结构、状态转换以及选举流程。
本文介绍如何使用Go语言实现Raft一致性算法。通过实验理解分布式系统中Raft算法的工作原理,包括领导选举、日志复制及安全性保障。文中详细解释了Raft节点的结构、状态转换以及选举流程。
Introduction
本次实验主要是用go语言实现简单的raft算法,熟悉一下分布式系统的一致性算法,这次实验实现的raft算法是后续实验的基础。推荐可以先看一下一个介绍raft的flash网站raft。
replicated服务(比如键值对数据库)使用raft算法来帮助管理replica节点。使用replica的目的是当系统中的部分replica节点down掉或者网络连接挂了时系统仍然能提供服务。当节点失败时,replica节点上的数据就可能不一致了,这时raft算法就能筛选出正确的数据。
raft算法的基本思路是实现一个复制状态机,它将客户端的请求组织成日志,确保所有的replica节点上的log都一致。每个replica节点根据日志里的请求顺序执行,应用请求结果到状态机中。由于所有活跃的replicas节点能够看到一样的日志内容,按照相同顺序执行请求,因此能够拥有相同的服务状态。假如一个节点挂了然后恢复,raft能小心地更新它的日志到最新状态。当系统中的大部分节点是活跃的并且能互相通信,那么raft就能持续服务。
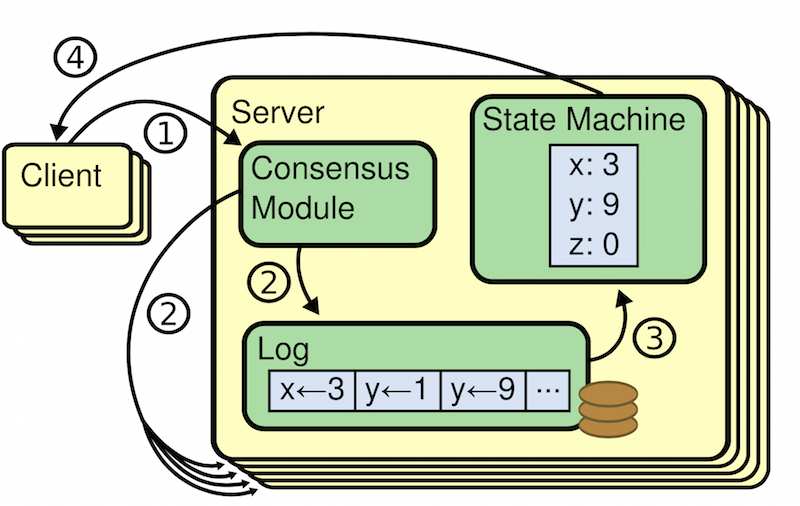
这次实验的代码量不多,重点是读懂raft的论文extended Raft paper,填充相应结构和实现相应方法。如果看英文比较吃力的,这里有中文翻译版本的链接raft。
Content
Raft 将一致性问题分解成了三个相对独立的子问题:
1、领导选举:一个新的领导人需要被选举出来,当先存的领导人宕机的时候(章节 5.2)
2、日志复制:领导人必须从客户端接收日志然后复制到集群中的其他节点,并且强制要求其他节点的日志保持和自己相同。
3、安全性:在 Raft 中安全性的关键是在图 3 中展示的状态机安全:如果有任何的服务器节点已经应用了一个确定的日志条目到它的状态机中,那么其他服务器节点不能在同一个日志索引位置应用一个不同的指令。章节 5.4 阐述了 Raft 算法是如何保证这个特性的;这个解决方案涉及到一个额外的选举机制(5.2 节)上的限制。
要想完成实验,最好的方法是先看懂测试代码,从中入手能够明白整个流程。
本次实验使用的是实验提供的labrpc框架(基于官方的rpc库rpc)来实现节点之间的通信。使用方法在labrpc/labrpc.go文件中说明,例子如下:
net := MakeNetwork() --新建1个网络来容纳客户端和服务器
end := net.MakeEnd(endname) --新建1个客户端来与服务器交流
net.AddServer(servername, server) -- 将1个服务器加入到网络中
net.DeleteServer(servername) --从网络中删除1个服务器
net.Connect(endname, servername) --将1个客户端连接到1个服务器
net.Enable(endname, enabled) -- enable/disable 1个客户端
end.Call("Raft.AppendEntries", &args, &reply) --发送1个rpc请求等待回复,其中Raft是服务结构体的名字,AppendEntries是服务器结构体中的1个方法,args是方法调用的参数,reply保存方法调用的返回结果。rpc调用返回值是bool类型,false表示网络丢失请求或者回复或者服务器挂了,true表示reply有效。
srv := MakeServer()
srv.AddService(svc) -- 1个服务器可以提供多种服务,比如raft和k/v
svc := MakeService(receiverObject) -- obj's methods will handle RPCs首先查看TestInitialElection函数(raft/test_test.go)。
func TestInitialElection(t *testing.T) {
servers := 3
cfg := make_config(t, servers, false)
defer cfg.cleanup()
fmt.Printf("Test: initial election ...\n")
// is a leader elected?
cfg.checkOneLeader()
// does the leader+term stay the same there is no failure?
term1 := cfg.checkTerms()
time.Sleep(2 * RaftElectionTimeout)
term2 := cfg.checkTerms()
if term1 != term2 {
fmt.Printf("warning: term changed even though there were no failures")
}
fmt.Printf(" ... Passed\n")
}第1个重要的函数是make_config函数,定义在config.go中,主要功能是创建初始化raft系统,返回值是config类型。config定义如下:
type config struct {
mu sync.Mutex
t *testing.T
net *labrpc.Network
n int
done int32 // tell internal threads to die
rafts []*Raft
applyErr []string // from apply channel readers
connected []bool // whether each server is on the net
saved []*Persister
endnames [][]string // the port file names each sends to
logs []map[int]int // copy of each server's committed entries
}主要成员是类型为labrpc.Network的net、raft系统节点的数组rafts、节点应用请求的反馈信息applyErr、节点实现永久存储的类型saved、每个节点rpc调用暴露的接口endnames和每个节点提交的日志。
func make_config(t *testing.T, n int, unreliable bool) *config {
runtime.GOMAXPROCS(4)
cfg := &config{}
cfg.t = t
cfg.net = labrpc.MakeNetwork()
cfg.n = n
cfg.applyErr = make([]string, cfg.n)
cfg.rafts = make([]*Raft, cfg.n)
cfg.connected = make([]bool, cfg.n)
cfg.saved = make([]*Persister, cfg.n)
cfg.endnames = make([][]string, cfg.n)
cfg.logs = make([]map[int]int, cfg.n)
cfg.setunreliable(unreliable)
cfg.net.LongDelays(true)
// create a full set of Rafts.
for i := 0; i < cfg.n; i++ {
cfg.logs[i] = map[int]int{}
cfg.start1(i)
}
// connect everyone
for i := 0; i < cfg.n; i++ {
cfg.connect(i)
}
return cfg
}在make_config函数中主要是进行config结构体变量的初始化,然后在第1个for循环中调用start1函数进行新建初始化raft节点,最后相互连接每个节点。
func (cfg *config) checkOneLeader() int {
for iters := 0; iters < 10; iters++ {
time.Sleep(500 * time.Millisecond)
leaders := make(map[int][]int)
for i := 0; i < cfg.n; i++ {
if cfg.connected[i] {
if t, leader := cfg.rafts[i].GetState(); leader {
leaders[t] = append(leaders[t], i)
}
}
}
lastTermWithLeader := -1
for t, leaders := range leaders {
if len(leaders) > 1 {
cfg.t.Fatalf("term %d has %d (>1) leaders", t, len(leaders))
}
if t > lastTermWithLeader {
lastTermWithLeader = t
}
}
if len(leaders) != 0 {
return leaders[lastTermWithLeader][0]
}
}
cfg.t.Fatalf("expected one leader, got none")
return -1
} 在checkOneLeader函数中循环10次,每次sleep500毫秒,每次调用raft节点的GetState函数获取节点当前状态,即是否处于Leader状态。判断系统中是否存在且只存在1个Leader。
至此TestInitialElection函数主要部分结束了,checkTerms函数用于获取leader节点的current Term,然后判断2倍选举超时之后leader节点的current Term与前面获得的值是否相同,正常情况下没有节点fail的情况下,leader不变且term也不变。
Raft Node
首先根据论文第5部分信息来填充raft.go文件中的raft节点,即每个节点应该包含哪些信息。



//
// log entry contains command for state machine, and term when entry
// was received by leader
//
type LogEntry struct {
Command interface{}
Term int
}
//
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex
peers []*labrpc.ClientEnd
persister *Persister
me int // index into peers[]
// Persistent state on all servers
currentTerm int
votedFor int
logs []LogEntry
// Volatile state on all servers
commitIndex int // index of highest log entry known to be committed
lastApplied int //index of highest log entry applied to state machine
// Volatile state on leaders
nextIndex []int // index of the next log entry to send to that server
matchIndex []int // index of highest log entry known to be replicated on server
// granted vote number
granted_votes_count int
// State and applyMsg chan
state string
applyCh chan ApplyMsg
// Log and Timer
//logger *log.Logger
timer *time.Timer
}其中timer用于节点的定时器,granted_vote_count用于统计投赞成票的数量。紧接着是Make函数用于初始化节点即raft结构体。
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here.
rf.currentTerm = 0
rf.votedFor = -1
rf.logs = make([]LogEntry, 0)
rf.commitIndex = -1
rf.lastApplied = -1
rf.nextIndex = make([]int, len(peers))
rf.matchIndex = make([]int, len(peers))
rf.state = FOLLOWER
rf.applyCh = applyCh
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
rf.persist()
rf.resetTimer()
return rf
}Leader Election
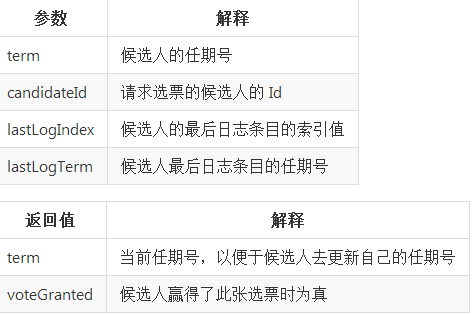
要开始一次选举过程,跟随者先要增加自己的当前任期号并且转换到候选人状态。然后他会并行的向集群中的其他服务器节点发送请求投票的 RPCs 来给自己投票。所以先要实现RequestVoteArgs和RequestVoteReply结构体,即请求投票RPC的参数和反馈结果。
type AppendEntryArgs struct {
Term int
Leader_id int
PrevLogIndex int
PrevLogTerm int
Entries []LogEntry
LeaderCommit int
}
type AppendEntryReply struct {
Term int
Success bool
CommitIndex int
}领导人选举中涉及的一个概念是超时,在raft节点超时时才会转换成候选者发出请求投票RPC。
func (rf *Raft) handleTimer() {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != LEADER {
rf.state = CANDIDATE
rf.currentTerm += 1
rf.votedFor = rf.me
rf.granted_votes_count = 1
rf.persist()
// rf.logger.Printf("New election, Candidate:%v term:%v\n", rf.me, rf.currentTerm)
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: len(rf.logs) - 1,
}
if len(rf.logs) > 0 {
args.LastLogTerm = rf.logs[args.LastLogIndex].Term
}
for server := 0; server < len(rf.peers); server++ {
if server == rf.me {
continue
}
go func(server int, args RequestVoteArgs) {
var reply RequestVoteReply
ok := rf.sendRequestVote(server, args, &reply)
if ok {
rf.handleVoteResult(reply)
}
}(server, args)
}
} else {
rf.SendAppendEntriesToAllFollwer()
}
rf.resetTimer()
} handleTimer函数用于处理节点超时。当节点超时时若节点不为领导人,则转换状态为候选者,term加1,并为自己投票。然后构建请求投票RPC的参数,向其他节点发送投票RPC请求,当有反馈时处理RPC调用的结果,最后调用resetTimer函数重置时钟。
接着来看一下sendRequestVote函数,该函数用于调用RPC请求。
func (rf *Raft) sendRequestVote(server int, args RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}RequestVote函数是接收到投票请求的raft节点的处理函数。
func (rf *Raft) RequestVote(args RequestVoteArgs, reply *RequestVoteReply) {
// Your code here.
rf.mu.Lock()
defer rf.mu.Unlock()
may_grant_vote := true
// current server's log must newer than the candidate
if len(rf.logs) > 0 {
if rf.logs[len(rf.logs)-1].Term > args.LastLogTerm ||
(rf.logs[len(rf.logs)-1].Term == args.LastLogTerm &&
len(rf.logs)-1 > args.LastLogIndex) {
may_grant_vote = false
}
}
// current server's current term bigger than the candidate
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
}
// current server's current term same as the candidate
if args.Term == rf.currentTerm {
// no voted candidate
if rf.votedFor == -1 && may_grant_vote {
rf.votedFor = args.CandidateId
rf.persist()
}
reply.Term = rf.currentTerm
reply.VoteGranted = (rf.votedFor == args.CandidateId)
return
}
// current server's current term smaller than the candidate
if args.Term > rf.currentTerm {
rf.state = FOLLOWER
rf.currentTerm = args.Term
rf.votedFor = -1
if may_grant_vote {
rf.votedFor = args.CandidateId
rf.persist()
}
rf.resetTimer()
reply.Term = args.Term
reply.VoteGranted = (rf.votedFor == args.CandidateId)
return
}
} 主要思路是这样的:先判断当前节点日志是否比候选者的新,要么最后一项日志的Term比参数中的Term大,要么Term一样但是最后一项日志的Index比参数中的Index大。如果当前节点日志比候选者的新,那么就不可能投票。然后判断当前节点的Term是否比候选者当前的Term大,如果大那么拒绝投票。如果相等,再判断当前节点在该Term中是否已经投过票,如果没投票并且能投票(日志更旧),那么就投票给该候选者。如果当前节点的Term比候选者节点的Term小,那么当前节点转换为Follwer状态,并且更新该节点的当前Term为候选者节点的Term,如果能投票则投票给该候选者节点。注意当2个节点的Term一样大时,当前节点的状态不能转变为Follwer,因为当前节点可能为候选者正在等待投票结果。
最后看一下候选者节点处理投票结果的函数。
func (rf *Raft) handleVoteResult(reply RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// old term ignore
if reply.Term < rf.currentTerm {
return
}
// newer reply item push peer to be follwer again
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.state = FOLLOWER
rf.votedFor = -1
rf.resetTimer()
return
}
if rf.state == CANDIDATE && reply.VoteGranted {
rf.granted_votes_count += 1
if rf.granted_votes_count >= majority(len(rf.peers)) {
rf.state = LEADER
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
rf.nextIndex[i] = len(rf.logs)
rf.matchIndex[i] = -1
}
rf.resetTimer()
}
return
}
} 在handleVoteResult函数中,如果候选者节点的Term大于反馈结果中的Term则忽视该信息。如果反馈结果中的Term比候选者节点的大,那么节点应该转换为Follwer状态。如果相等并且反馈结果中有投票,那么判断当前获得的投票总数是否大于一半,如果是则转换为Leader状态,并为相关节点信息初始化。
至此完整的领导人选举内容就完成了。
回过头看一下测试代码中的第2个测试TestReElection函数。
func TestReElection(t *testing.T) {
servers := 3
cfg := make_config(t, servers, false)
defer cfg.cleanup()
fmt.Printf("Test: election after network failure ...\n")
leader1 := cfg.checkOneLeader()
// if the leader disconnects, a new one should be elected.
cfg.disconnect(leader1)
cfg.checkOneLeader()
// if the old leader rejoins, that shouldn't
// disturb the old leader.
cfg.connect(leader1)
leader2 := cfg.checkOneLeader()
// if there's no quorum, no leader should
// be elected.
cfg.disconnect(leader2)
cfg.disconnect((leader2 + 1) % servers)
time.Sleep(2 * RaftElectionTimeout)
cfg.checkNoLeader()
// if a quorum arises, it should elect a leader.
cfg.connect((leader2 + 1) % servers)
cfg.checkOneLeader()
// re-join of last node shouldn't prevent leader from existing.
cfg.connect(leader2)
cfg.checkOneLeader()
fmt.Printf(" ... Passed\n")
} 该测试新建1个含有3个节点的raft系统,然后测试当领导人失去连接时,系统应该要重新选举出1个领导人。当先前领导人重新加入系统中时,现有的领导人应该不会发生变化,因为先前领导人的Term小于此时领带人的Term,会被迫更新。当移除2个节点时,系统中应该没有领导人。重新加入1个节点时,构成1个选举,此时系统中应该含有1个领导人。

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









