







注:本文大致翻译自EXACT STRING MATCHING ALGORITHMS,去掉一些废话,增加一些解释。
本文的算法一律输出全部的匹配位置。模式串在代码中用x[m]来表示,文本用y[n]来,而所有字符串都构造自一个有限集的字母表Σ,其大小为σ。
四、可以滑动多远
记得在穷举法中,每一趟比较后,无论成与不成,都将模式向右滑动一个位置,然后继续比较。有没有办法能利用之前的比较结果,使得模式滑动的更远一点呢?
Not So Naive
- preprocessing phase in constant time and space;
- searching phase in O(nm) time complexity;
- slightly (by coefficient) sub-linear in the average case.
During the searching phase of the Not So Naive algorithm the character comparisons are made with the pattern positions in the following order1, 2, ... , m-2, m-1, 0.
- void NSN(char *x, int m, char *y, int n) {
- int j, k, ell;
- /* Preprocessing */
- if (x[0] == x[1]) {
- k = 2;
- ell = 1;
- }
- else {
- k = 1;
- ell = 2;
- }
- /* Searching */
- j = 0;
- while (j <= n - m)
- if (x[1] != y[j + 1])
- j += k;
- else {
- if (memcmp(x + 2, y + j + 2, m - 2) == 0 &
- x[0] == y[j])
- OUTPUT(j);
- j += ell;
- }
- }
Quick Search
- simplification of the Boyer-Moore algorithm;
- uses only the bad-character shift;
- easy to implement;
- preprocessing phase in O(m+
 ) time and O() space complexity;
) time and O() space complexity; - searching phase in O(mn) time complexity;
- very fast in practice for short patterns and large alphabets.
- void preQsBc(char *x, int m, int qsBc[]) {
- int i;
- for (i = 0; i < ASIZE; ++i)
- qsBc[i] = m + 1;
- for (i = 0; i < m; ++i)
- qsBc[x[i]] = m - i;
- }
- void QS(char *x, int m, char *y, int n) {
- int j, qsBc[ASIZE];
- /* Preprocessing */
- preQsBc(x, m, qsBc);
- /* Searching */
- j = 0;
- while (j <= n - m) {
- if (memcmp(x, y + j, m) == 0)
- OUTPUT(j);
- j += qsBc[y[j + m]]; /* shift */
- }
- }
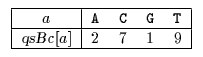
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | ||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (qsBc[G])
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 2 (qsBc[A])
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 2 (qsBc[A])
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 9 (qsBc[T])
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 7 (qsBc[C])
The Quick Search algorithm performs 15 character comparisons on the example.
示例解析:MP/KMP
- performs the comparisons from left to right;
- preprocessing phase in O(m) space and time complexity;
- searching phase in O(n+m) time complexity (independent from the alphabet size);
- performs at most 2n-1 information gathered during the scan of the text;
- delay bounded by m.
MP(Morris-Pratt algorithm)算法:
The design of the Morris-Pratt algorithm follows a tight analysis of the Brute Force algorithm, and especially on the way this latter wastes the information gathered during the scan of the text.
Let us look more closely at the brute force algorithm. It is possible to improve the length of the shifts and simultaneously remember some portions of the text that match the pattern. This saves comparisons between characters of the pattern and characters of the text and consequently increases the speed of the search.
Consider an attempt at a left position j on y, that is when the window is positioned on the text factor y[j .. j+m-1]. Assume that the first mismatch occurs between x[i] and y[i+j] with 0 < i < m. Then, x[0..i-1] = y[j .. i+j-1] = u and a = x[i]  y[i+j]=b.
y[i+j]=b.
When shifting, it is reasonable to expect that a prefix v of the pattern matches some suffix of the portion u of the text. The longest such prefix v is calledthe border of u (it occurs at both ends of u).
This introduces the notation: let mpNext[i] be the length of the longest border of x[0 .. i-1] for 0 < i  m. Then, after a shift, the comparisons can resume between characters c=x[mpNext[i]] and y[i+j]=b without missing any occurrence of x in y, and avoiding a backtrack on the text (see figure 6.1). The value of mpNext[0] is set to -1.
m. Then, after a shift, the comparisons can resume between characters c=x[mpNext[i]] and y[i+j]=b without missing any occurrence of x in y, and avoiding a backtrack on the text (see figure 6.1). The value of mpNext[0] is set to -1.
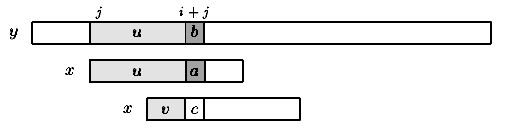
Figure 6.1: Shift in the Morris-Pratt algorithm (v border of u).
The table mpNext can be computed in O(m) space and time before the searching phase, applying the same searching algorithm to the pattern itself, as if x=y.
Then the searching phase can be done in O(m+n) time. The Morris-Pratt algorithm performs at most 2n-1 text character comparisons during the searching phase. Thedelay (maximal number of comparisons for a single text character) is bounded by m.
代码:
void preMp(char *x, int m, int Next[]) {
int i, j;
i = 0;
j = Next[0] = -1;
while (i < m) {
while (j > -1 && x[i] != x[j])
j = Next[j];
i++;
j++;
// 下面注掉的三行去掉注释就成KMP了
//if (x[i] == x[j])
// Next[i] = Next[j];
//else
Next[i] = j;
}
}
void MP(char *x, int m, char *y, int n) {
int i, j, Next[XSIZE];
/* Preprocessing */
preMp(x, m, Next);
/* Searching */
i = j = 0;
while (j < n) {
while (i > -1 && x[i] != y[j])
i = Next[i];
i++;
j++;
if (i >= m) {
OUTPUT(j - i);
i = Next[i];
}
}
}上述原始程序中,
MP函数是模式串和文本串比较,j是文本串y中的当前字符位置。
preMp函数是模式串和模式串自己比较,i是文本串x(相当于文本串)中的当前字符位置。
不便于记忆与理解。
下面的程序修改为preMp和MP中,j都是文本串中的当前字符位置,i都是模式串当前字符位置:
#define XSIZE 256
// preMp是模式字符串自己和自己比较,那么有一个相当于文本字符串
// MP是模式字符串和文本字符串比较
// preMp 和MP中,j都是文本字符串的当前位置
void preMp(char *x, int m, int Next[]) {
int i, j;
j = 0;
i = Next[0] = -1;
while (j < m) {
while (i > -1 && x[i] != x[j])
i = Next[i];
i++;
j++;
// 下面注掉的三行去掉注释就成KMP了
//if (x[i] == x[j])
// Next[j] = Next[i];
//else
Next[j] = i;
}
}
void MP(char *x, int m, char *y, int n) {
int i, j, Next[XSIZE];
/* Preprocessing */
preMp(x, m, Next);
/* Searching */
i = j = 0;
while (j < n) {
while (i > -1 && x[i] != y[j])
i = Next[i];
i++;
j++;
if (i >= m) {
OUTPUT(j - i);
//printf( "%d\n", j - i );
i = Next[i];
}
}
}示例:

| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | ||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 3 (i-mpNext[i]=3-0)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 7 (i-mpNext[i]=8-1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=1-0)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-mpNext[i]=0- -1)
The Morris-Pratt algorithm performs 19 character comparisons on the example.
示例解析:
preMp函数解析:
Next[0] = -1;
j = 0时,i = -1,然后跳过里层while, 然后j++ = 1,i++ = 0,Next[1] = i = 0;
j = 1时,i = 0,然后while: i = Next[i] = -1,然后j++ = 2,i++ = 0,Next[2] = i = 0;
j = 2时,i = 0,然后while: i = Next[i] = -1,然后j++ = 3,i++ = 0,Next[3] = i = 0;
j = 3时,i = 0,然后跳过里层while, 然后j++ = 4,i++ = 1,Next[4] = i = 1;
j = 4时,i = 1,然后while: i = Next[i] = -1,然后j++ = 5,i++ = 0,Next[5] = i = 0;
j = 5时,i = 0,然后跳过里层while, 然后j++ = 6,i++ = 1,Next[6] = i = 1;
j = 6时,i = 1,然后while: i = Next[i] = -1,然后j++ = 7,i++ = 0,Next[7] = i = 0;
j = 7时,i = 0,然后跳过里层while, 然后j++ = 8,i++ = 1,Next[8] = i = 1;
preMp函数主要是:模式的前缀与模式中的一部分比较,来判断shift的大小,也即Next的大小。
MP函数中while循环跟preMp函数类似,但是要注意判断条件x[i] != y[j],因为preMp函数是模式字符串自己与自己比较,而MP函数是模式字符串与文本字符串比较。分步解析:
j = 0,i = 0,跳过里层while, i++ = 1,j++ = 1,i < 8;
j = 1,i = 1,跳过里层while, i++ = 2,j++ = 2,i < 8;
j = 2,i = 2,跳过里层while, i++ = 3,j++ = 3,i < 8;
j = 3,i = 3,while:i =Next[i] = -1,i++ = 0,j++ = 4,i < 8;
j = 4,i = 0,while:i = Next[i] = -1,i++ = 0,j++ = 5,i < 8;
j = 5,i = 0,跳过里层while, i++ = 1,j++ = 6,i < 8;
j = 6,i = 1,跳过里层while, i++ = 2,j++ = 7,i < 8;
j = 7,i = 2,跳过里层while, i++ = 3,j++ = 8,i < 8;
j = 8,i = 3,跳过里层while, i++ = 4,j++ = 9,i < 8;
j = 9,i = 4,跳过里层while, i++ = 5,j++ = 10,i < 8;
j = 10,i = 5,跳过里层while, i++ = 6,j++ = 11,i < 8;
j = 11,i = 6,跳过里层while, i++ = 7,j++ = 12,i < 8;
j = 12,i = 7,跳过里层while, i++ = 8,j++ = 13,i = 8,匹配。并且i = Next[i] = 0,即下一轮模式串从0开始比较;
......
可以看到,while循环每运行一次,j自增1,即文本字符串往右移动一位。
例二:
当文本字符串为aaaaaa,模式字符串为aaa时,Next表为: -1,0,1,2。
那么MP函数中while循环中的内层循环不需要运行,从j为3开始,每次只需要比较模式字符串的最后一个字符与文本字符串的下一个字符即可。
MP函数中while循环分步解析:
j = 0,i = 0,跳过里层while, i++ = 1,j++ = 1,i < 3;
j = 1,i = 1,跳过里层while, i++ = 2,j++ = 2,i < 3;
j = 2,i = 2,跳过里层while, i++ = 3,j++ = 3,i = 3,匹配。并且i = Next[i] = 2,即下一轮模式串从2开始比较;
j = 3,i = 2,跳过里层while, i++ = 3,j++ = 4,i = 3,匹配。并且i = Next[i] = 2,即下一轮模式串从2开始比较;
j = 4,i = 2,跳过里层while, i++ = 1,j++ = 5,i = 3,匹配。并且i = Next[i] = 2,即下一轮模式串从2开始比较;
j = 5,i = 2,跳过里层while, i++ = 1,j++ = 6,i = 3,匹配。并且i = Next[i] = 2,即下一轮模式串从2开始比较;
完成。
- performs the comparisons from left to right;
- preprocessing phase in O(m) space and time complexity;
- searching phase in O(n+m) time complexity (independent from the alphabet size);
- delay bounded by log
 (m) where is the golden ratio (
(m) where is the golden ratio (  ).
).
The design of the Knuth-Morris-Pratt algorithm follows a tight analysis of the Morris and Pratt algorithm. Let us look more closely at the Morris-Pratt algorithm. It is possible to improve the length of the shifts.
Consider an attempt at a left position j, that is when the the window is positioned on the text factor y[j .. j+m-1]. Assume that the first mismatch occurs between x[i] and y[i+j] with 0 < i < m. Then, x[0 .. i-1] = y[j .. i+j-1] =u and a = x[i] y[i+j]=b.
When shifting, it is reasonable to expect that a prefix v of the pattern matches some suffix of the portion u of the text. Moreover, if we want to avoid another immediate mismatch, the character following the prefix v in the pattern must be different from a. The longest such prefix v is called the tagged border of u(it occurs at both ends of u followed by different characters in x).
This introduces the notation: let kmpNext[i] be the length of the longest border of x[0 .. i-1] followed by a character c different from x[i] and -1 if no such tagged border exits, for 0 < i m. Then, after a shift, the comparisons can resume between characters x[kmpNext[i]] and y[i+j] without missing any occurrence of x in y, and avoiding a backtrack on the text (see figure 7.1). The value of kmpNext[0] is set to -1.
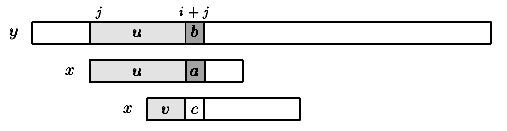
Figure 7.1: Shift in the Knuth-Morris-Pratt algorithm (v border of u and c b).
The table kmpNext can be computed in O(m) space and time before the searching phase, applying the same searching algorithm to the pattern itself, as if x=y.
The searching phase can be performed in O(m+n) time. The Knuth-Morris-Pratt algorithm performs at most 2n-1 text character comparisons during the searching phase. The delay (maximal number of comparisons for a single text character) is bounded by log![]() (m) where
(m) where ![]() is the golden ratio ( ).
is the golden ratio ( ).
#define XSIZE 256
// preMp是模式字符串自己和自己比较,那么有一个相当于文本字符串
// MP是模式字符串和文本字符串比较
// preMp 和MP中,j都是文本字符串的当前位置
void preMp(char *x, int m, int Next[]) {
int i, j;
j = 0;
i = Next[0] = -1;
while (j < m) {
while (i > -1 && x[i] != x[j])
i = Next[i];
i++;
j++;
// 下面注掉的三行去掉注释就成KMP了
if (x[i] == x[j])
Next[j] = Next[i];
else
Next[j] = i;
}
}
void MP(char *x, int m, char *y, int n) {
int i, j, Next[XSIZE];
/* Preprocessing */
preMp(x, m, Next);
/* Searching */
i = j = 0;
while (j < n) {
while (i > -1 && x[i] != y[j])
i = Next[i];
i++;
j++;
if (i >= m) {
OUTPUT(j - i);
//printf( "%d\n", j - i );
i = Next[i];
}
}
}示例:
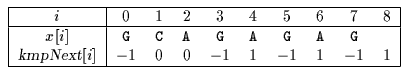
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | ||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 4 (i-kmpNext[i]=3- -1)(注:这一步后,i = -1,跳过KMP中的第二个while循环,i++, j++,所以文本串的第3个字符没有跟模式串比较了,直接是文本串的第4个字符跟模式串第0个字符比较)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-kmpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 7 (i-kmpNext[i]=8-1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-kmpNext[i]=1-0)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-kmpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-kmpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-kmpNext[i]=0- -1)
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | |||||||||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
Shift by: 1 (i-kmpNext[i]=0- -1)
The Knuth-Morris-Pratt algorithm performs 18 character comparisons on the example.
示例解析:
preMp函数解析:
Next[0] = -1;
j = 0时,i = -1,然后跳过里层while, 然后j++ = 1,i++ = 0,Next[1] = i = 0;
j = 1时,i = 0,然后while: i = Next[i] = -1,然后j++ = 2,i++ = 0,Next[2] = i = 0;
j = 2时,i = 0,然后while: i = Next[i] = -1,然后j++ = 3,i++ = 0,Next[3] =Next[i] = -1;
j = 3时,i = 0,然后跳过里层while, 然后j++ = 4,i++ = 1,Next[4] = i = 1;
j = 4时,i = 1,然后while: i = Next[i] = -1,然后j++ = 5,i++ = 0,Next[5] =Next[i] = -1;
j = 5时,i = 0,然后跳过里层while, 然后j++ = 6,i++ = 1,Next[6] = i = 1;
j = 6时,i = 1,然后while: i = Next[i] = -1,然后j++ = 7,i++ = 0,Next[7] =Next[i] = -1;
j = 7时,i = 0,然后跳过里层while, 然后j++ = 8,i++ = 1,Next[8] = i = 1;
preMp函数主要是:模式的前缀与模式中的一部分比较,来判断shift的大小,也即Next的大小。
MP函数中while循环跟preMp函数类似,但是要注意判断条件x[i] != y[j],因为preMp函数是模式字符串自己与自己比较,而MP函数是模式字符串与文本字符串比较。分步解析:
j = 0,i = 0,跳过里层while, i++ = 1,j++ = 1,i < 8;
j = 1,i = 1,跳过里层while, i++ = 2,j++ = 2,i < 8;
j = 2,i = 2,跳过里层while, i++ = 3,j++ = 3,i < 8;
j = 3,i = 3,while:i = Next[i] = -1,i++ = 0,j++ = 4,i < 8;
j = 4,i = 0,while:i = Next[i] = -1,i++ = 0,j++ = 5,i < 8;
j = 5,i = 0,跳过里层while, i++ = 1,j++ = 6,i < 8;
j = 6,i = 1,跳过里层while, i++ = 2,j++ = 7,i < 8;
j = 7,i = 2,跳过里层while, i++ = 3,j++ = 8,i < 8;
j = 8,i = 3,跳过里层while, i++ = 4,j++ = 9,i < 8;
j = 9,i = 4,跳过里层while, i++ = 5,j++ = 10,i < 8;
j = 10,i = 5,跳过里层while, i++ = 6,j++ = 11,i < 8;
j = 11,i = 6,跳过里层while, i++ = 7,j++ = 12,i < 8;
j = 12,i = 7,跳过里层while, i++ = 8,j++ = 13,i = 8,匹配。并且i = Next[i] = 0,即下一轮模式串从0开始比较;
......
可以看到,while循环每运行一次,j自增1,即文本字符串往右移动一位。
参考:















 1829
1829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









