







第八讲-流程挖掘(Process Mining)学习日志之高级过程发现技术概述
α算法很好地说明了过程发现背后的主要思想,但是这个简单的算法无法处理第六讲中描述的4个质量维度(适应度、简洁度、精确度和泛化度)的权衡。为了成功地将过程挖掘应用到实践中,我们需要处理噪声和不完备性。本讲关注更加高级的过程发现技术,目的并不是展示某个特定技术的细节,而是对相关方法进行概述,这将会帮助读者选择合适的过程挖掘技术。此外,理解各种方法的优点和弱点有助于正确解释和有效利用发现的模型。
参考:PROCESS MINING:Discovery,Conformance and Enhancement of Business Processes
文章目录
图 6.1 总结了α算法的问题。每个黑点代表与事件日志中一个或多个案例相关的一个轨迹(即活动序列)。(多个案例可能对应同一个轨迹。)一个事件日志通常只包含可能行为的一部分,也就是说图中的点仅仅是更大的可能行为集合的样例。此外,通常我们主要对频繁行为而不是所有可能行为感兴趣,也就是说,我们希望从噪声中提取出频繁行为,因此,并不是所有的点都必须与要构建的过程模型相关。
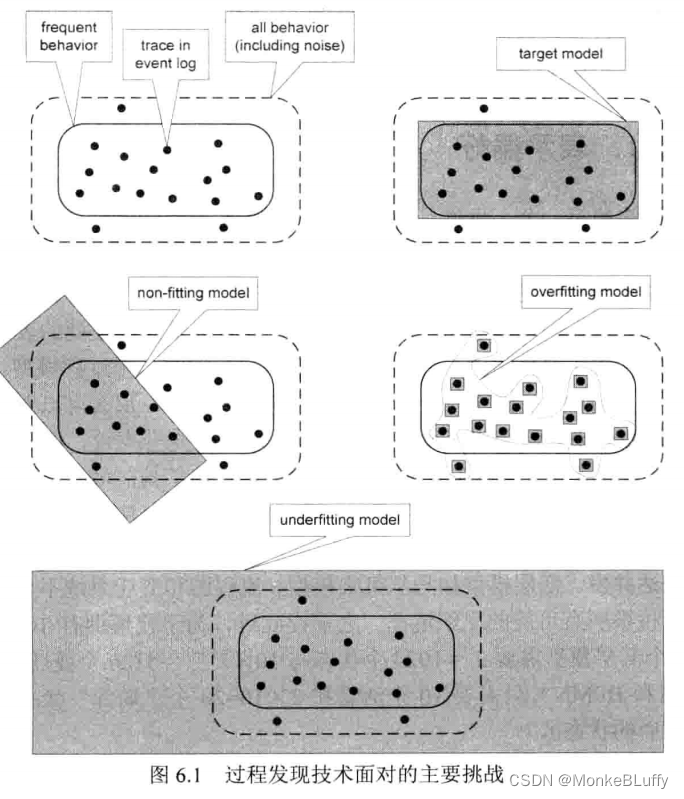
回忆之前我们将噪声定义为不频繁或者异常的行为,分析这样的噪声行为很有意思, 然而在构建总的过程模型时,含有不频繁或异常行为会导致模型变得复杂。此外,在给定小观察集的情况下,通常不可能对噪声下可靠的定论。图 6.1 区分了频繁行为(圆角实线矩形)和所有行为(虚线矩形),即正常加上噪声行为。正常和噪声行为之间的差别是一个定义问题,例如正常行为可以被定义为最频繁出现轨迹的80%。之前我们提到 80/20 模型, 即过程模型能够描述日志中所见80%的行为,这一模型通常比较简单,因为日志中剩余的20%能够反映模型80%的变化。
假定我们可以无限观察过程并且过程不变(无概念漂移),从而能够确定这两个圆角矩形。基于该假设,图 6.1 用带阴影的矩形描绘了发现的4个模型,这些模型基于日志中的样例轨迹,也就是图中的黑点。当过程可以被无限观察并且保持固定状态时,“理想的过程模型”与可见的频繁行为相一致。图 6.1 中的“不适合模型”无法描述过程的特征,因为它甚至无法表达用于学习模型的事件日志中的行为。“过拟合模型”没有进行泛化,仅仅描述了当前事件日志中的例子,新的例子很有可能与模型不符。“欠拟合模型”缺少精确度, 并且它会允许无限观察过程中从未被观测到的行为发生。
图 6.1 展示了过程发现技术需要面对的挑战:如何提取一个不欠拟合、不过拟合、也不会不适合的简单目标模型? 显然,α算法无法做到这一点。因此,我们将介绍更多高级方法。在此之前,我们先了解一下过程发现算法的典型特征。
8.1 特征1:表示偏好
过程发现算法的第一个,也许是最重要的一个特征是表示偏好,即能够发现的过程模型类型。例如,α算法只能够发现每个变迁具有唯一可见标签的Petri 网。除 Petri 网之外,还可以使用很多其他的表现方式,例如 BPMN 、EPC 、YAWL、隐马尔可夫模型、变迁系统和因果网。表示偏好决定了搜索空间,同时潜在地限定了发现模型的表达能力。举例而言,考虑图 5.21 中关于事件日志L=[<a,b,c>20,<a,c>3] 的3个过程模型。如果表示偏好允许重复的标签(两个标签相同的变迁)或者无声(t) 变迁,那么可以发现一个更加合适的工作流网。然而如果表示偏好不允许,那么发现算法注定会失败,即无法发现一个合适的工作流网。工作流模式 (workflow patterns)是一种工具,可以用于讨论和确定一种语言的表示偏好。在此,我们并不讨论40多个控制流模式,而是讨论典型的表达偏好对某些过程发现算法的限制:
-
不能表达并发。低层模型如马尔可夫模型、流程图和变迁系统不允许建模并发,它们只能枚举所有可能的交织情况。之前提到过,为了建模拥有10个并发活动的过程, 一个低层模型需要210=1024个状态与10×210-1=5120个变迁。而高层模型(如 Petri 网和BPMN) 只需要10个活动和2×10=20个“局部”状态(在每个活动之前和之后的状态)。
-
不能处理(任意)循环。许多过程挖掘算法在循环上加上了一些限制,例如α算法在处理短循环时需要预处理和后处理步骤。某些假设潜在模型是块结构的挖掘算法,通常不支持“任意循环”模式。
-
不能表达无声动作。许多表示方法不能建模无声(隐藏)动作,比如跳过一个活动。尽管这样的事件无法明确地被记录在事件日志中,但是在模型中需要有所反映。这限制了模型表达能力。
-
不能表达重复活动。许多表示法不允许两个活动带有相同的标签。如果同一活动出现在过程的不同部分,但是该活动的不同实例在事件日志中无法区分,那么多数算法会假定过程中只存在单一活动,进而避免生成在实际过程中不存在的因果依赖 (例如不存在的循环)。
-
不能建模 OR-split 和 OR-join。正如在第2章中看到的,YAWL、BPMN、EPC 和因果网等允许建模 OR-split 和 OR-join。如果一个发现算法的表示偏好不允许建模 OR-split 和 OR-join, 那么发现的模型可能变得更加复杂或者该算法无法找到合适的模型。
-
不能表达非自由选择行为。多数算法不允许非自由选择结构,即并发和选择结合。 图5.1使用了非自由选择结构,因为库所pl 和 p2 同时作为 XOR-split (执行e 或者 执行b 和 c 的选择)和AND-split(开始活动b 和 c 的并发),这个工作流网可以被 α算法发现。然而,非自由选择结构也能表现非局部依赖,如图5.14中的工作流网所示,这样的工作流网不能被基本的α算法发现。工作流网可以表达非自由选择行为,但是许多发现算法使用了不能表达非自由选择行为的表示偏好。
-
不能表达层次。大多数过程发现算法处理的是“扁平”模型,一个值得关注的例外是提取层次模型的模糊挖掘器,出现频次低但与其他低频次活动紧密相关的活动可以被组织成子过程。原则上,表示偏好决定了层次模型是否能够被发现。
8.2 特征2:处理噪声的能力
发现的模型应该不包含噪声行为,即异常或不频繁行为。首先,用户通常希望看到主流行为。其次,不可能从极其罕见的活动或模式中推出有意义的信息。因此,大多数算法会通过“忽略”异常或不频繁的行为来处理这一问题。可以通过预处理日志来移除噪声,或者发现算法可以在构造模型时提取出噪声。能否处理噪声是过程发现算法的一个重要特征。
8.3 特征3:完备性假设
与噪声相关的是完备性问题,大多数过程发现算法做出了隐含或明确的完备性假设。例如α算法假设>L关系是完备的,即如果一个活动可以直接跟在另一个活动后面,那么这一行为至少能够在日志中看到一次。其他算法有不同的完备性假设,有的算法假设事件日志包含所有可能的轨迹,即非常强的完备性假设,这是非常不现实的,会导致过拟合的模型。做出强完备性假设的算法倾向于过拟合日志,而过弱的完备性假设则倾向于产生欠拟合的结果模型。
8.4 特征4:使用的方法
有很多方法可以用于过程发现,很难给出完整的概述。此外,某些方法在使用的技术上还相互重叠。因此本书将简要介绍4类典型的方法。
8.4.1 直接的算术方法
第一类过程发现方法,从事件日志中抽取一些足迹并使用这些足迹直接构建出过程模 型。a 算法23是这种方法的一个例子:从日志中抽取出>L关系,并基于这一关系构建 Petri 网。有很多α算法的变体使用相似的方法。使用“基于语言的区域”方法通过将事件日志转换为不等式系统来推出库所,在这种情况下,不等式系统可以被看作用于构建 Petri 网的足迹。在文献中可以找到产生 Petri 网的过程挖掘方法的综述。中描述的方法也从事件日志中提取了足迹,但是这些方法在处理噪声和不完备 性相关问题时考虑了频率。
8.4.2 两阶段方法
第二类过程发现方法包含两个步骤,第一步构建一个“低层模型”(例如一个变迁系统或马尔可夫模型),第二步将低层模型转换为能够表达并发和其他(更加高级的)控制流模式的“高层模型”。[20]描述了这种方法的一个例子,使用可定制的抽象机制从日志中抽取出一个变迁系统,然后使用“基于状态区域”方法将这个变迁系统转换成一个 Petri 网。 结果模型可以使用 Petri 网表示,同时也可以被转换为其他表示法(如 BPMN 和 EPC) 。与之相似,可以使用隐马尔可夫模型来表示低层模型,使用期望最大化 (EM) 算法,如 Baum-Welch 算法,可以从日志中获取“最合适的”马尔可夫模型,随后这个模型被转换为高层模型。这类方法的一个缺点是在发现的过程中不能利用表示偏好。此外,某些映射是 “有损的”,也就是需要对低层过程模型进行细微的改动才能使它适合目标语言,而且与更加直接的算数方法相比,两阶段算法通常较慢。
8.4.3 计算智能方法
第三类过程发现方法源于计算智能领域的技术,这些技术包括蚁群算法、遗传程序设计、遗传算法、模拟退火、强化学习、机器学习、神经网络、模糊集、粗糙集和群体智能等,它们的共同点是使用了进化方法,也就是说,不是直接把日志转变为模型,而是使用迭代的过程去模拟自然演化过程。此处无法给出计算智能技术的概述,但我们可以参考并使用中描述的遗传过程挖掘方法作为例子。这一方法从一个初始的个体集合开始,每个个体对应一个随机生成的过程模型。对每个个体计算一个适合值,代表该模型符合日志的程度。为了使集合演化,选择最适合的个体并使用遗传操作如交叉(结合两个个体的部分)和突变(随机修改个体)来生成新的个体。适合值一代代提高,直到获得一个质量可接受的个体(即模型)时,演化过程结束。
8.4.4 局部方法
至今描述的方法都生成一个完整的端到端过程模型,其实也可以将关注点放在规则和频繁模式上。描述了一种挖掘顺序模式的方法这种方法与关联规则的发现相似,但它考虑了事件的顺序。描述了另一种使用类似 Apriori 方法的技术,它能够发现频繁的片段。此处使用一个滑动窗口来分析一个“片段”(即偏序)出现的频繁度。 相似的方法可以用于学习声明式(基于LTL的)语言。
下面我们将深入讨论3种方法:启发式挖掘、遗传过程挖掘以及基于区域的挖掘。最后介绍过程发现的历史,我们将回顾 Marc Gold 、Anil Nerode、 Alan Biermann 以及其他人的经典工作。














 1225
1225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









