








 超级会员免费看
超级会员免费看

python编程题目:
A、B两个Excel表,数据根据指定值存在一对多的关系,将数据的关系找出来并合并两个表的数据:
A表的数据格式如下:

B表的数据格式如下:
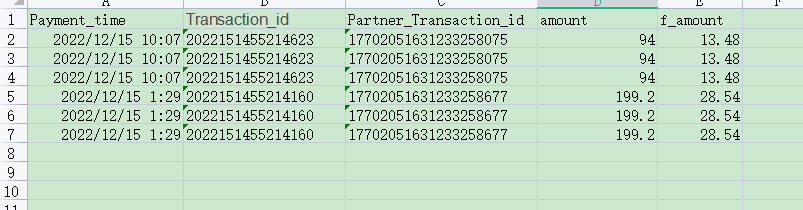
其中,这两个表中有相同的属性Transaction_id,并且A表的记录和B表的记录存在一对多的关系,实现根据Transaction_id的值将两者数据合并,并同时保留各自的表头信息。
python编程实现思路:
1)AB表都是Excel表,很容易联想到python中的pandas库中的dateframe数据结构,处理Excel表很方便;
2)既然有相同的属性值,那么我们可以通过A表中的Transaction_id来筛选B中的数据;
3)将A中的数据和根据Transaction_id筛选出来的B中的数据行进行拼接,可以使用pandas中的concat方法
4)要保留各自的表头,所以不能直接concat,而是把B的表格的头部信息当做一行数据来处理,这里很重要,不然直接concat的话,如果表头不一样,效果就不是我们想要的。
python实现代码:
import pandas as pd
# 读取Excel文件
df_a = pd.read_excel('A.xls',dtype=str)
df_b = pd.read_excel('B.xls',dtype=str)
#
df_result = pd.DataFrame()
for i in range(len(df_a)):
transaction_id = df_a.iloc[i]['Transaction_id']
df = df_b[df_b['Transaction_id']==transaction_id] #按transaction_id查找B表的数据
#合并数据
#当前行数据
df_current = df_a.iloc[i].to_frame().T
#获取Partner_Transaction_id列
coumn = pd.DataFrame([df.iloc[0]['Partner_Transaction_id']],columns=['Partner_Transaction_id'],index=[i])
# 增加一列Partner_Transaction_id
df_current = pd.concat([coumn,df_current],axis=1,)
df_result = pd.concat([df_result,df_current])
#增加一行(把B表符合条件的表头作为一行)
row= pd.DataFrame([df.columns.tolist()],columns=df_result.columns)
df_result = pd.concat([df_result,row])
#把B中符合条件的行都添加进来
for j in range(len(df)):
row = pd.DataFrame([df.iloc[j].tolist()], columns=df_result.columns)
df_result = pd.concat([df_result, row],ignore_index=True)
# 每2个记录之间添加一个空行,为了美观
row = pd.DataFrame([["" for a in range(len(df_current.columns))]], columns=df_current.columns)
df_result = pd.concat([df_result, row], ignore_index=True)
# 将结果保存到Excel文件 追加保存
df_result.to_excel('result_ab.xls',index=False)
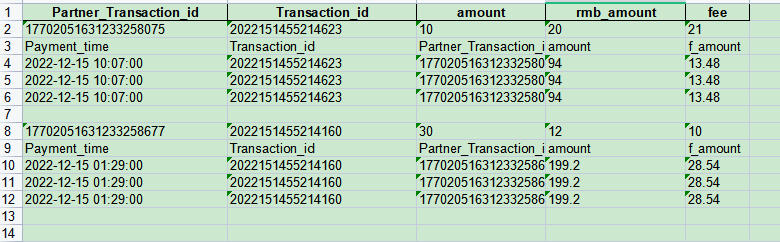
最终的效果:
















 5128
5128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











