







关注微信公共号:小程在线


关注CSDN博客:程志伟的博客
ClickHouse server version 21.6.6
创建表
dblab-VirtualBox :) CREATE TABLE limit_by(id Int, val Int) ENGINE = Memory;
CREATE TABLE limit_by
(
`id` Int,
`val` Int
)
ENGINE = Memory
Query id: 892b335b-f25f-4aef-ba60-5281dd752c1b
Ok.
0 rows in set. Elapsed: 0.006 sec.
dblab-VirtualBox :) INSERT INTO limit_by VALUES (1, 10), (1, 11), (2, 12), (3, 20), (3, 21);
INSERT INTO limit_by VALUES
Query id: 85429b01-5d58-4104-a550-bc477e158465
Ok.
5 rows in set. Elapsed: 0.011 sec.
dblab-VirtualBox :) select * from limit_by;
SELECT *
FROM limit_by
Query id: ec740af6-c451-4985-81b5-243106333a5a
┌─id─┬─val─┐
│ 1 │ 10 │
│ 1 │ 11 │
│ 2 │ 12 │
│ 3 │ 20 │
│ 3 │ 21 │
└────┴─────┘
5 rows in set. Elapsed: 0.004 sec.
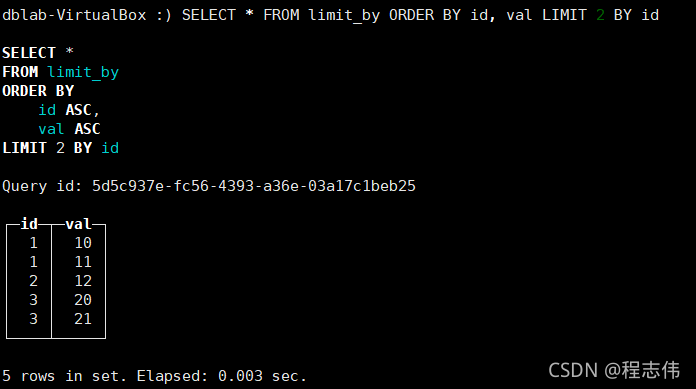
按照分组每个id取2个值
dblab-VirtualBox :) SELECT * FROM limit_by ORDER BY id, val LIMIT 2 BY id
SELECT *
FROM limit_by
ORDER BY
id ASC,
val ASC
LIMIT 2 BY id
Query id: 5d5c937e-fc56-4393-a36e-03a17c1beb25
┌─id─┬─val─┐
│ 1 │ 10 │
│ 1 │ 11 │
│ 2 │ 12 │
│ 3 │ 20 │
│ 3 │ 21 │
└────┴─────┘
5 rows in set. Elapsed: 0.003 sec.
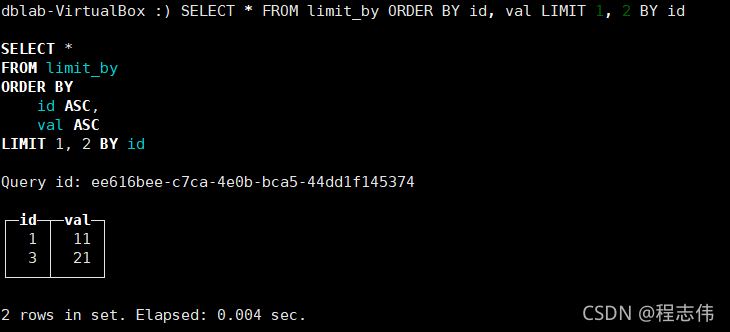
从第1位之后取值,取2个
dblab-VirtualBox :) SELECT * FROM limit_by ORDER BY id, val LIMIT 1, 2 BY id
SELECT *
FROM limit_by
ORDER BY
id ASC,
val ASC
LIMIT 1, 2 BY id
Query id: ee616bee-c7ca-4e0b-bca5-44dd1f145374
┌─id─┬─val─┐
│ 1 │ 11 │
│ 3 │ 21 │
└────┴─────┘
2 rows in set. Elapsed: 0.004 sec.

















 2023
2023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









