







lstm原理
lstm可以一定长度上解决梯度消失问题
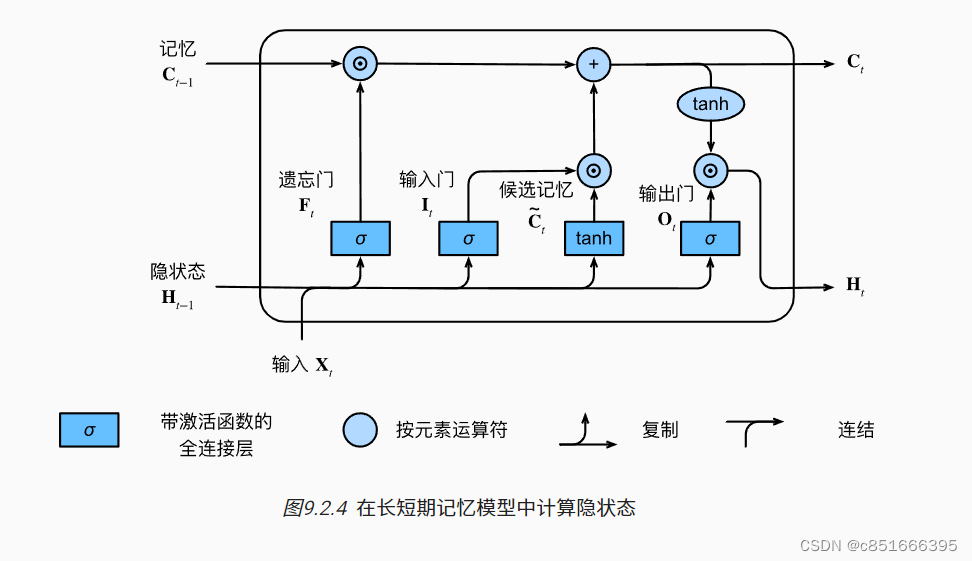
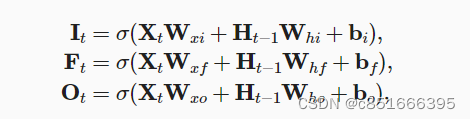
候选记忆单元(包含了新的信息):
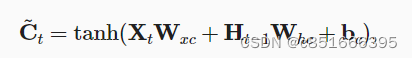
遗忘门使用: 遗忘门*上一次的记忆单元
![]()
输入门的使用: 输入门*候选记忆单元
![]()
记忆单元:
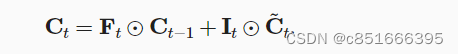
输出门的使用: 输出门*记忆单元
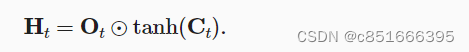
import torch
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
# 这里简写了 num_input=embedding_dim num_output=vocab_size
def normal(shape): # 按标准差 0.01的高斯分布初始化权重 bias 0
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
# 初始化lstm (h, c) 为0
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs: # 门:sigmoid 信息:tanh
# 输入门
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
# 遗忘门
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
# 输出门
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
# 候选记忆元(新信息)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
# 记忆元 = 遗忘门*上一次记忆元 + 输入门*候选记忆元
C = F * C + I * C_tilda
# H = 输出门 * C
H = O * torch.tanh(C)
# 输出层 output(有的直接append(H))
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)lstm输出
lstm输入: seq_len, batch_size, embedding
输出: output: seq_len, batch_size, n_direction*hid_dim
hidden: n_direction*num_layers, batch_size, hid_dim
cell: n_direction*num_layers, batch_size, hid_dim
gru输出
gru输入: seq_len, batch_size, embedding
输出: output: seq_len, batch_size, n_direction*hid_dim
hidden: n_direction*num_layers, batch_size, hid_dim
lstm输出中output和h的关系:
单向时 h相当于最后一个时间步输出,相当于output[ -1 ; ; ]
一对一输出的话用output
分类的话用hidden最后一层 双向可以用 hidden[ -2 ; ; ] 和 hidden[ -1 ; ; ] 拼接















 5897
5897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









