







一、前言
最近DeepSeek也是比较火,我也去学习了一下如何本都部署DeepSeek,目前主要方法有两种吧,一种是自己拉取开发环境并且运行模型,另一种则是使用框架来运行模型。使用框架运行模型也是目前部署DeepSeek最简单的方法。那么本次教程,就来教大家如何使用本地的模型框架来运行DeepSeek模型并且调用这个模型的API,如果你准备好了,那就让我们开始吧!
二、使用的框架及硬件要求
本次教程中,会为大家介绍使用Ollama和LM Studio两种框架运行DeepSeek模型,这两款框架在一些地方也各有自己的优缺点,具体的大家可以自行体会。之前的教程中已经为大家演示过如何安装Ollama并且运行llama模型。但是没有教大家如何修改Ollama的路径,本次教程会将这一空缺补齐。
现在来讲讲硬件要求,首先要明确一点的是要运行大模型需要比较高的算力,所以,尽量不要使用太老的电脑进行尝试。对于一些被量化过的模型,比如1.5B参数的模型甚至更小的模型,使用CPU就可以勉强运行。对于一些较大的模型,比如4B,6B,8B的模型,可能就需要显卡了,当然这里的显卡我们通常指的是NVIDIA的显卡。这些大的模型不是CPU不能运行,而是运行起来太慢了。当然,这只是性能方面的问题,还有一些内存与显存方面的问题。假如一个模型是8B的模型没有被量化就需要大约8GB的显存,4B的模型3GB或者4GB的显存都能运行。这个就需要大家自己进行估计了,如果你没有显卡上面所说的显存都为占用到内存中。当然,显存和内存的大小直接就决定了这个模型能不能运行,显存或者内存太小可能直接导致这个无法加载。CPU和显卡的性能直接决定了模运行的速度。
三、框架的安装
说了上面那么多,我们现在就来实操一下吧。这里会为大家介绍LM Studio与Ollama两种框架的安装方法。Ollama与LM Studio一样,都是用来推理模型的框架,如果没有特殊需求的话,两个任选一个安装即可。
1.LM Studio的安装
这里我们可以直接在浏览器中搜索LM Studio:
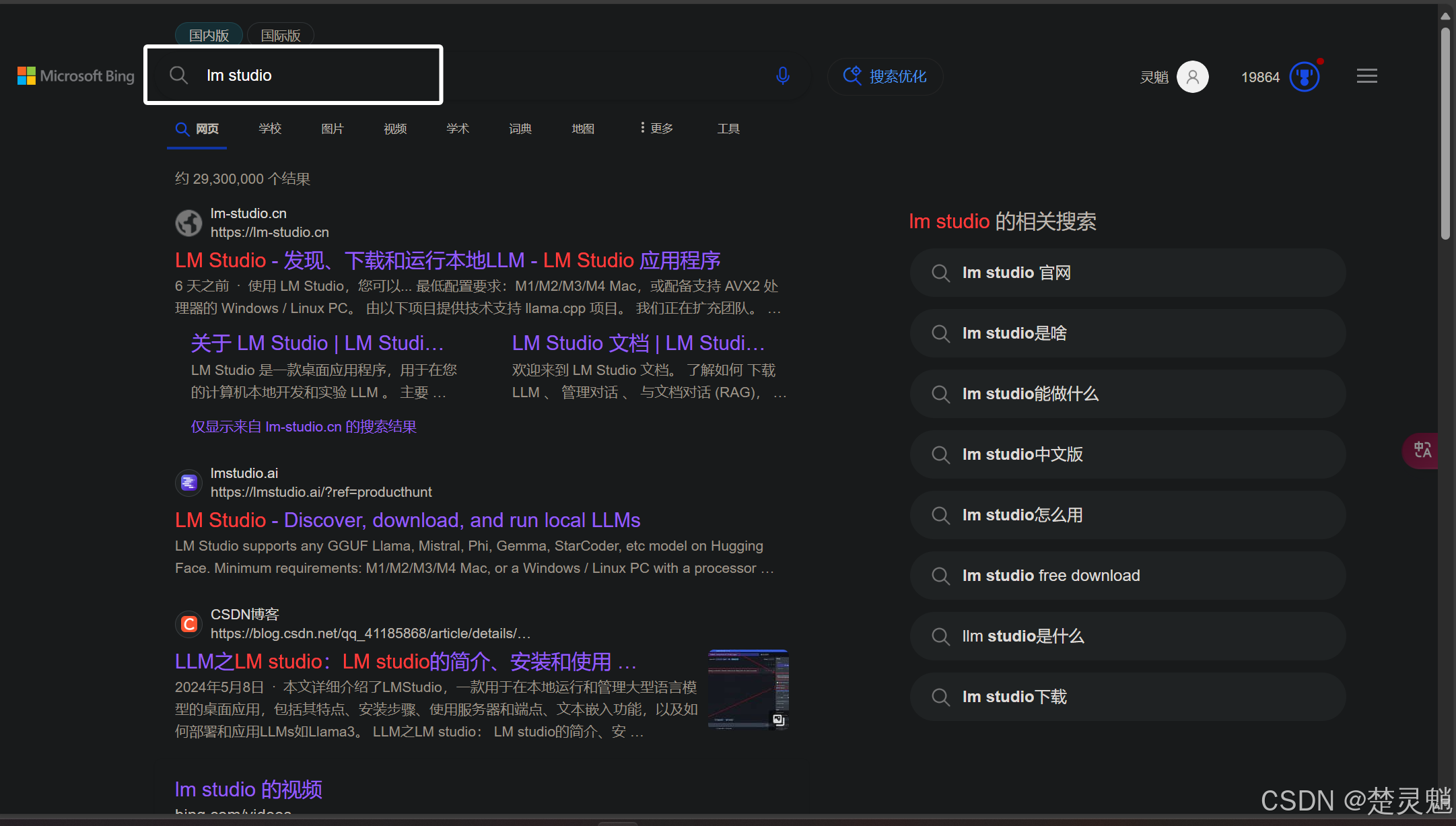
这里我们可以看到,搜索到的第一个就是LM Studio的官网了:
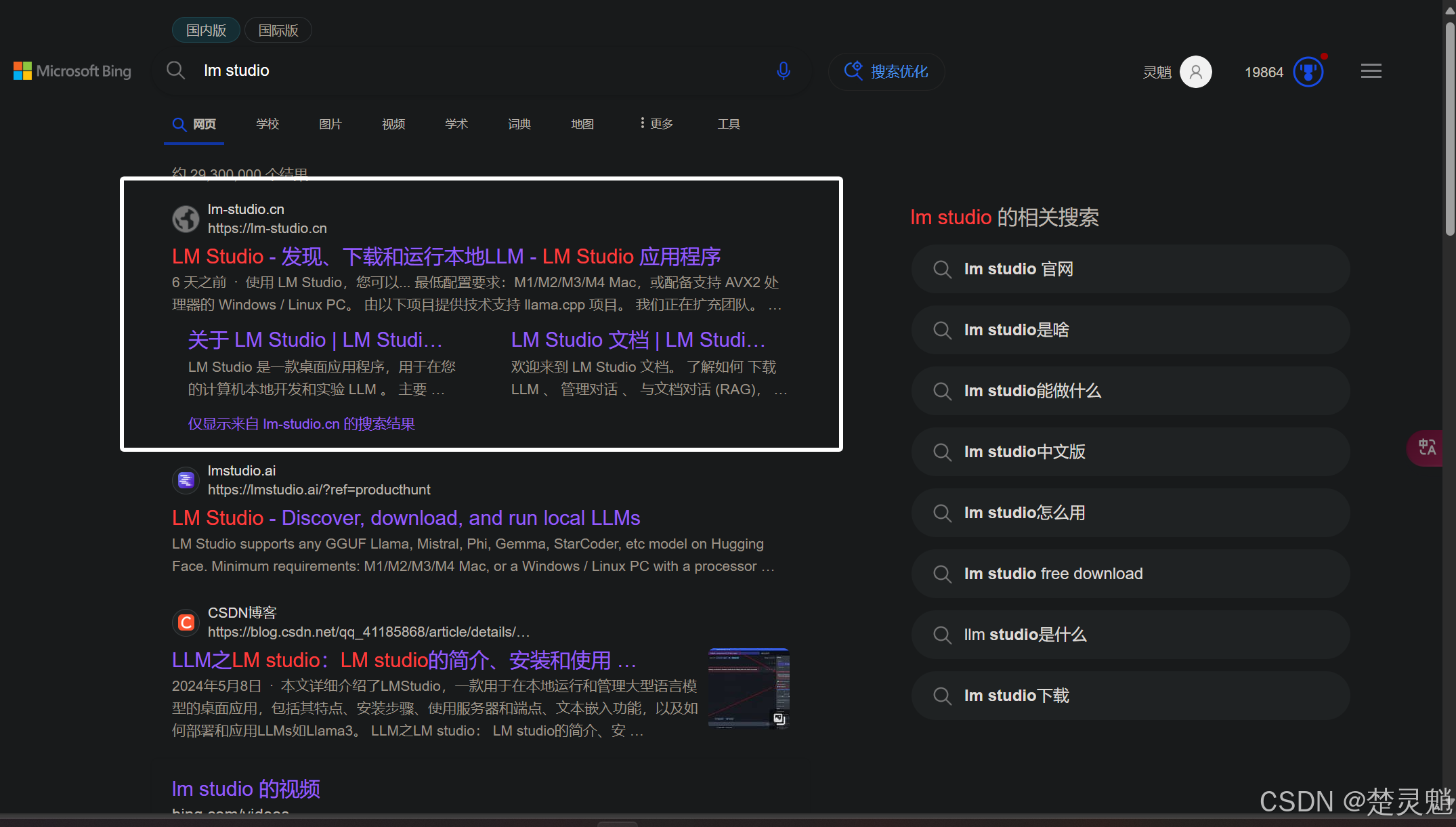
当然,如果大家没找到的话,也可以点击下方的链接前往:
LM Studio:LM Studio - 发现、下载和运行本地LLM - LM Studio 应用程序
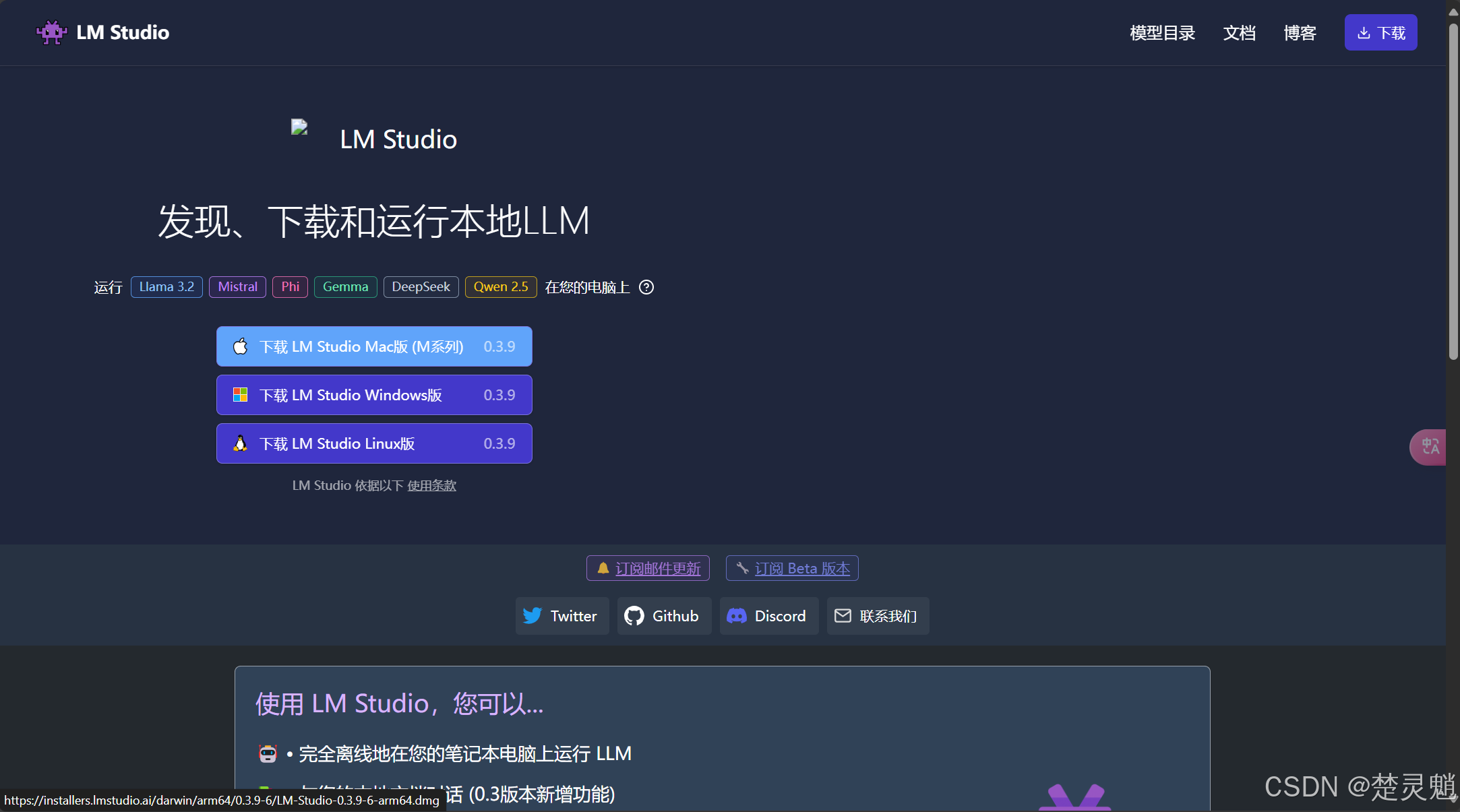
进入LM Studio的官网以后,就能看到以下界面了:
这里我们直接选择下载Windows版:
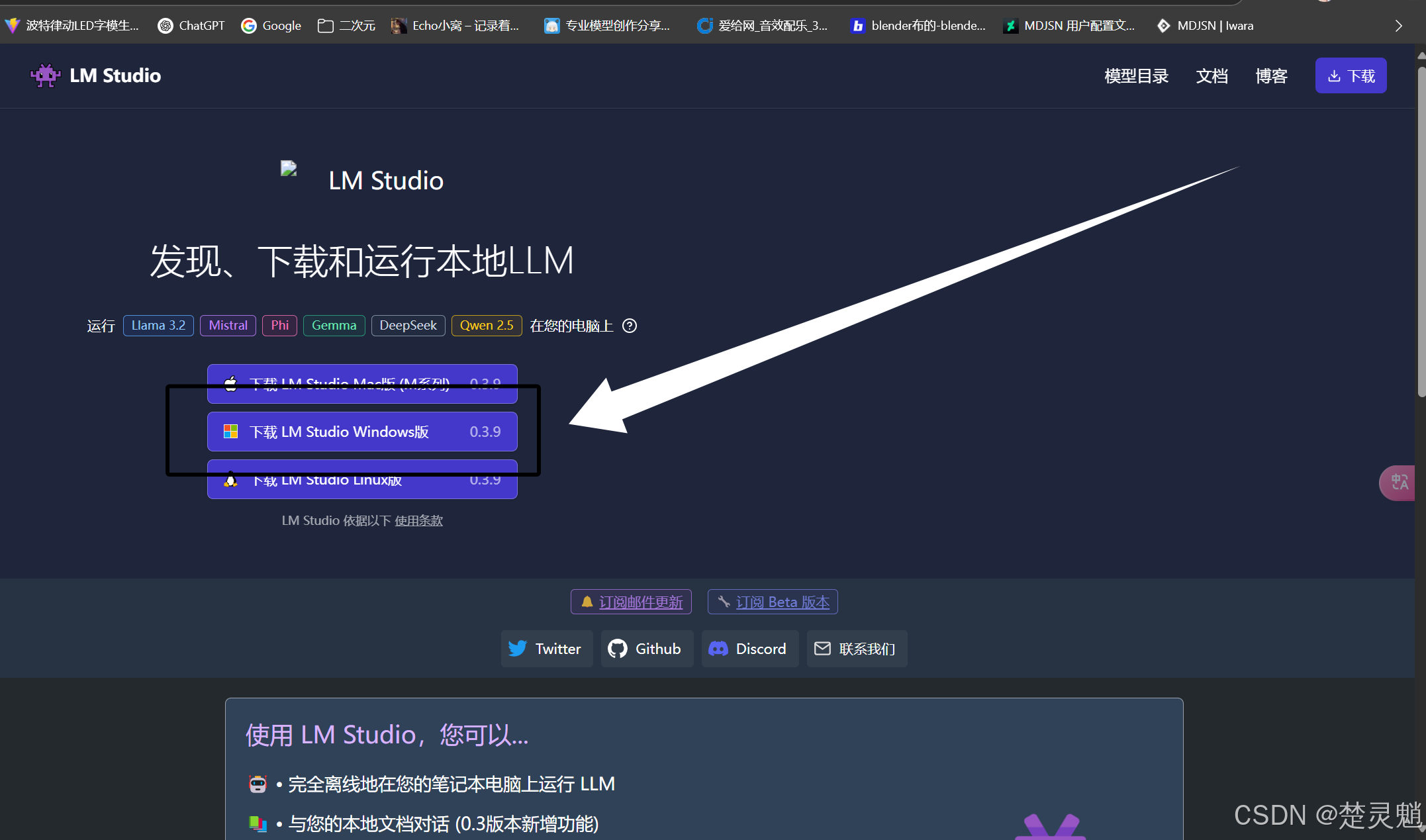
过一会儿浏览器就会弹出下载了:
这里大家将其下载到自己能找到的地方即可:
随后我们双击这个应用安装引导程序进行安装:
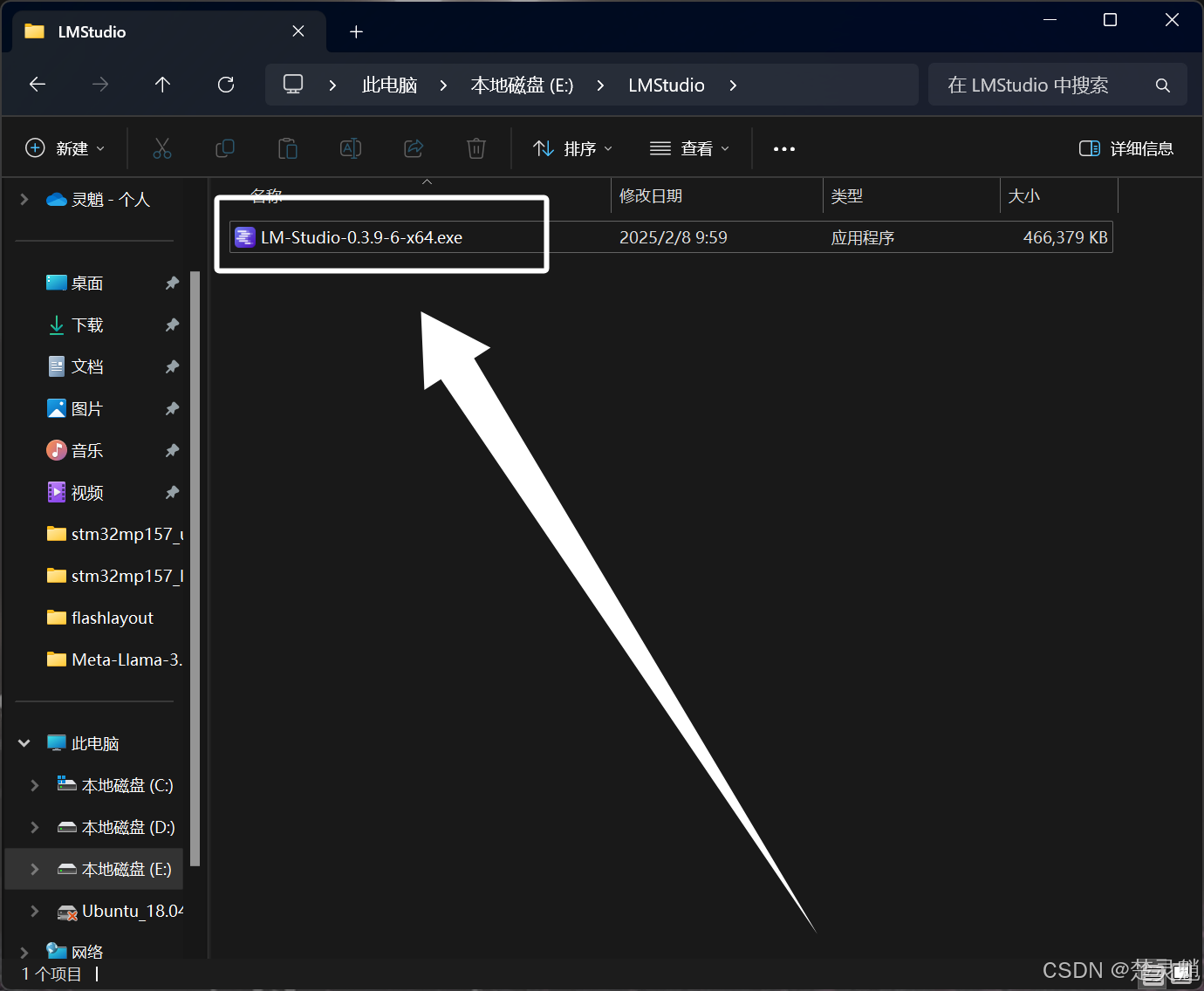
下面的“仅为我安装”和“为所有用户安装”大家自己进行选择,为所有用户安装后,计算机的每一个用户都能看到这个应用,我这里选择的是仅为我安装,如果你是小白,请跟着我操作,选择好以后点击下一步即可:
随后是选择安装的路径,这里建议大家和我一样在某个盘新建一个文件夹,选择好路径以后点击安装即可:
这里我们等待进度条走完:
可以看到,这里我们已经安装完成了,点击“完成”即可:
至此,我们LM Studio的安装就已经完成了。
2.Ollama的安装与路径修改
下面来教大家如何安装Ollama,这里我们直接在浏览器中搜索Ollama:
这里搜索到的第一个就是Ollama的官网了:
当然,大家也可以点击下方的链接前往:
Ollama官网:Ollama
进入官网以后,就能看到以下界面了:
这里我们直接点击“Download”:
点击以后,就跳转到了以下界面:
在下面的界面中,我们选择Windows,随后点击Download for Windows:
过一会儿浏览器就会弹出下载了:
大家将其下载到自己能找到的地方:
这里双击下载好的exe文件启动应用安装引导程序:
这里我们直接点击Install即可:
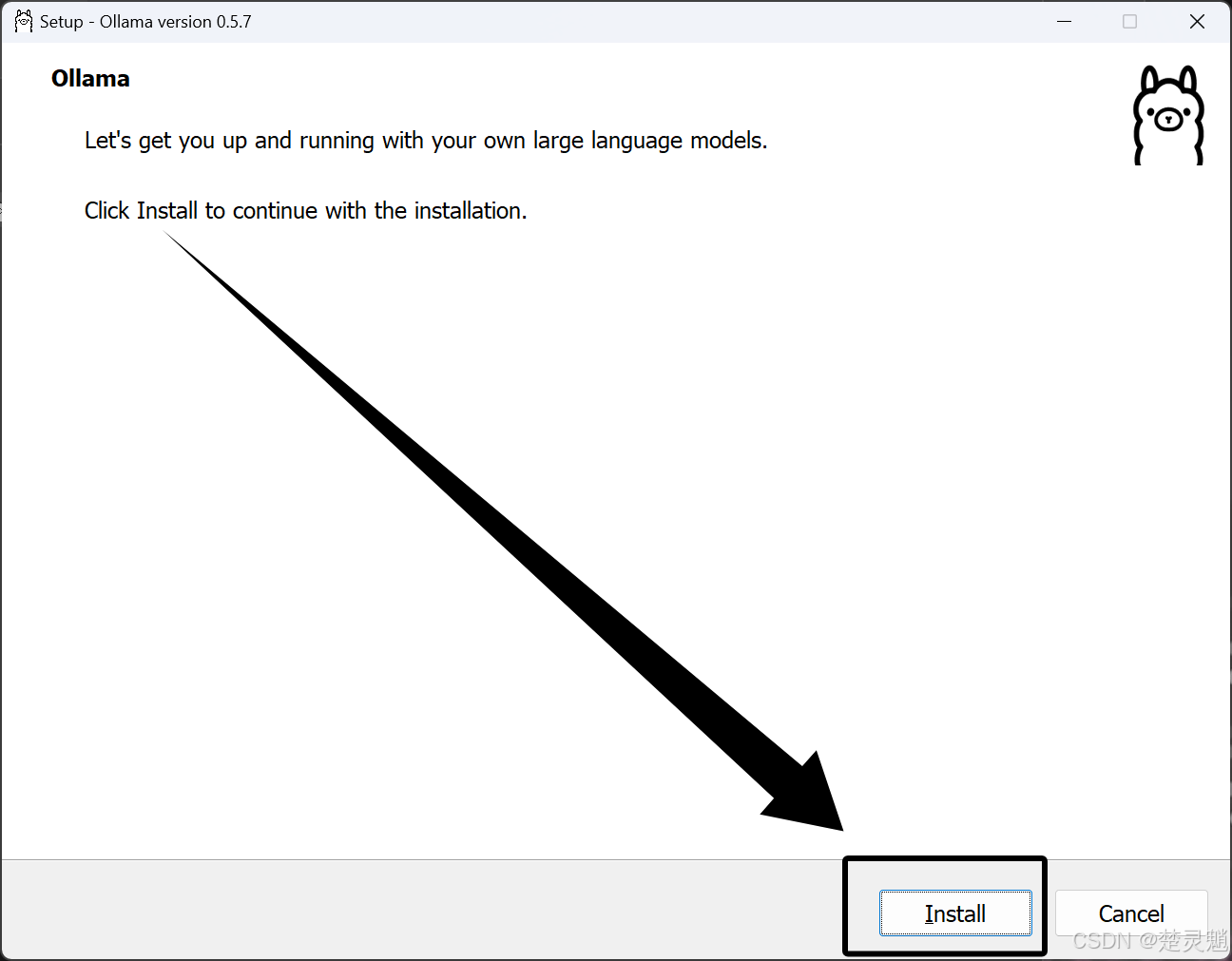
这里我们等待进度条走完,我们可以看到它被安装到C盘了,后面会教大家如何修改:
安装完成以后,Ollama会出现在任务栏中:

下面来教大家如何修改Ollama的路径,这里我们进入到C盘,有一个名为用户的文件夹,当然你的电脑中这个文件夹可能不叫用户,可能叫Users,这都是同一个文件夹:
进入这个文件夹可以看到以下文件夹:
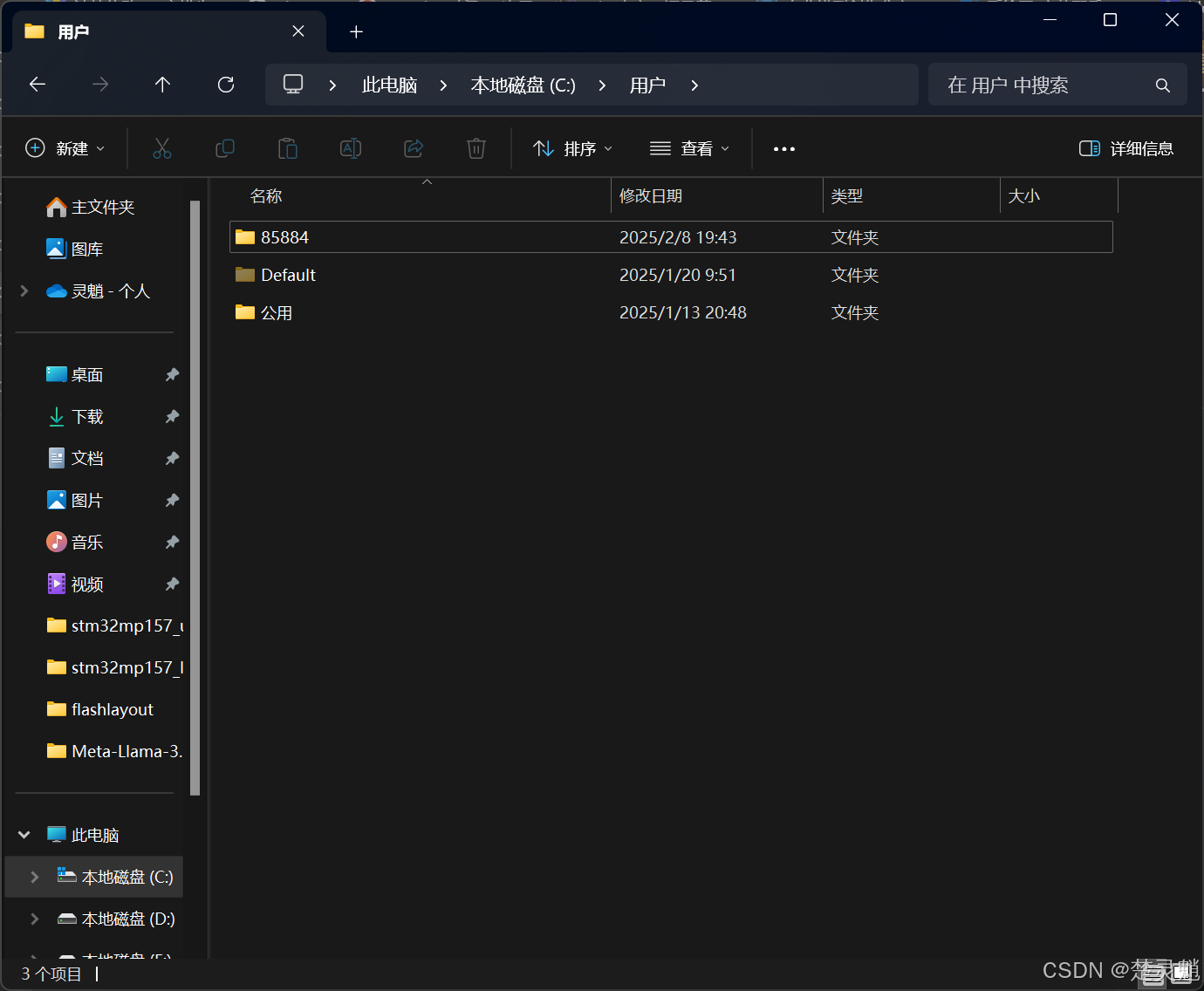
这里,大家需要确定自己的用户文件夹,比如我这里的用户文件夹就是名为“85884”的这个文件夹,进入这个用户文件夹下的“AppData\Local\Programs”文件夹下就可以看到一个名为Ollama的文件夹:
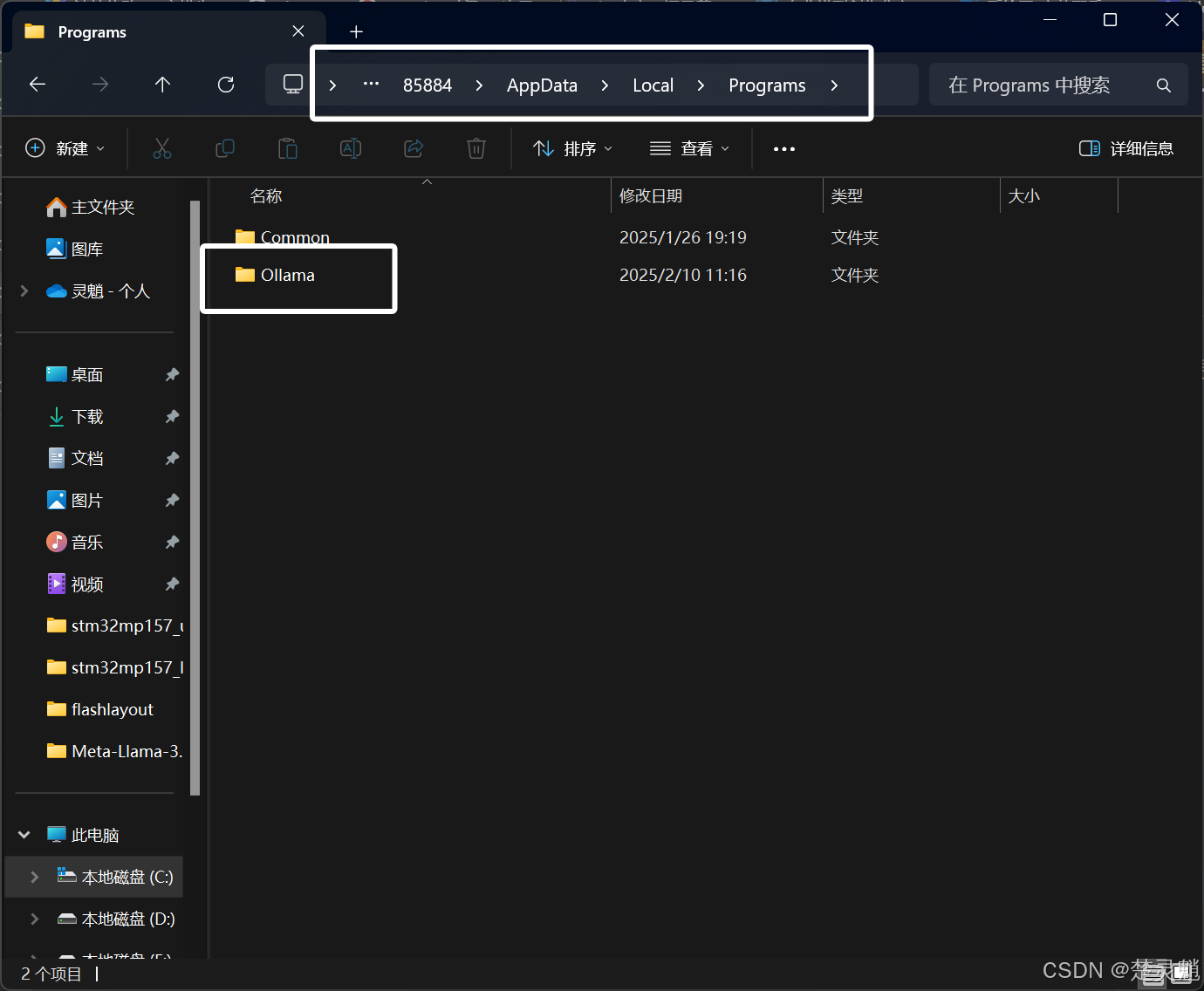
如果在你的用户文件夹中你没有找到“AppData”文件夹,可以将隐藏的项目打上勾:
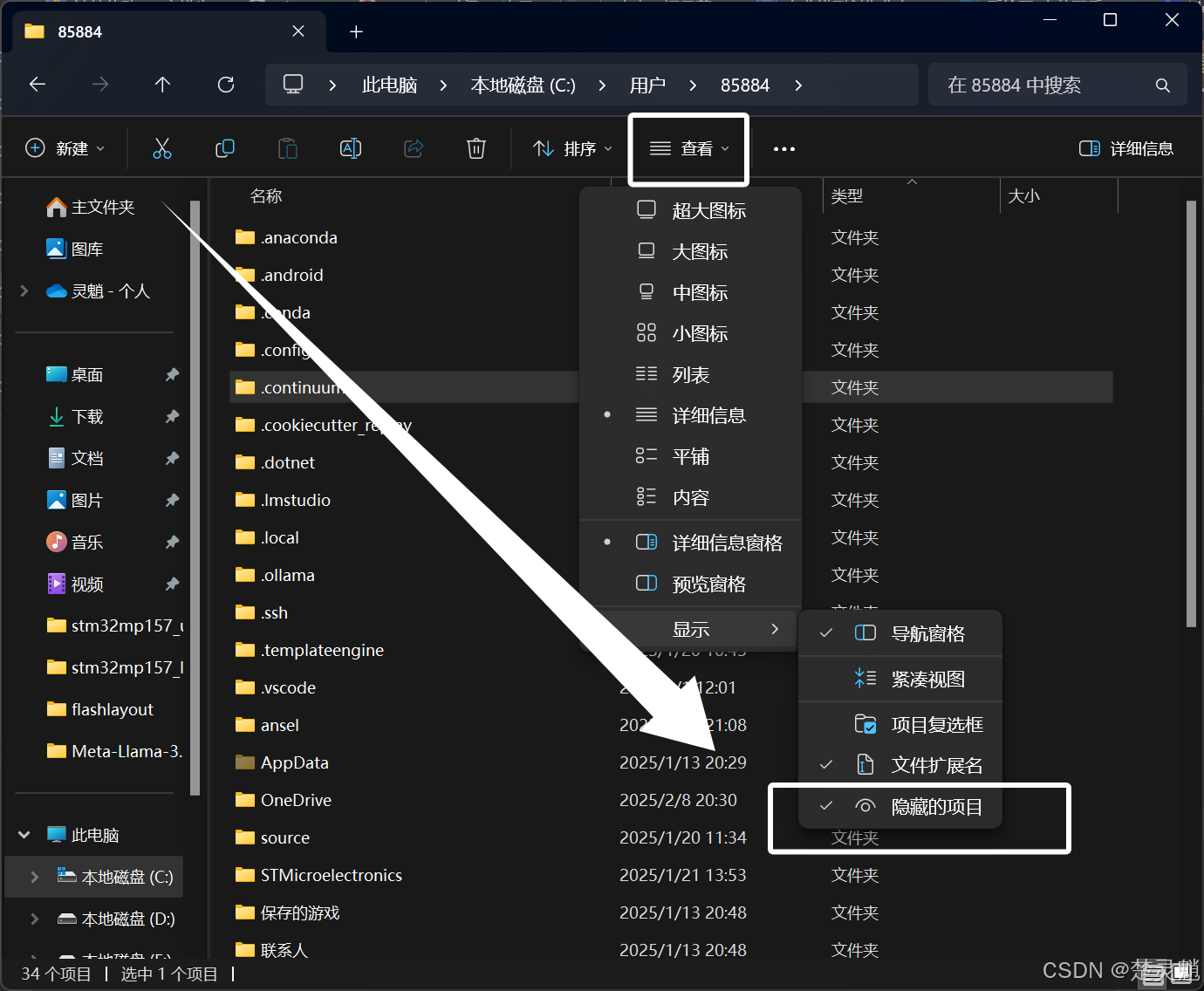
好,继续回到改路径的话题,当你找到我所说的路径下的Ollama的文件夹以后,查看一下这个文件夹的大小,避免搞错了,这个Ollama的文件夹一般在4个G以上:
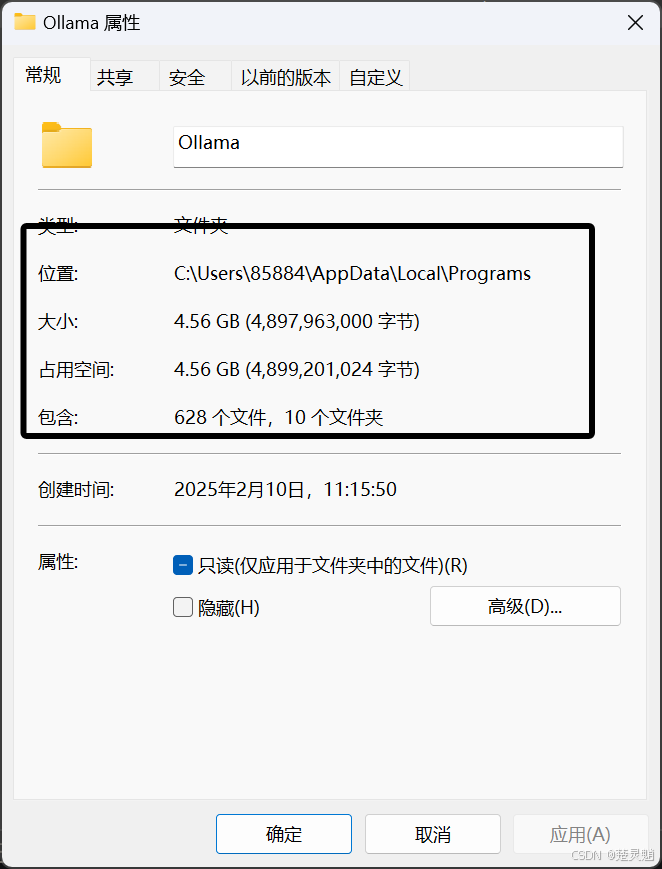
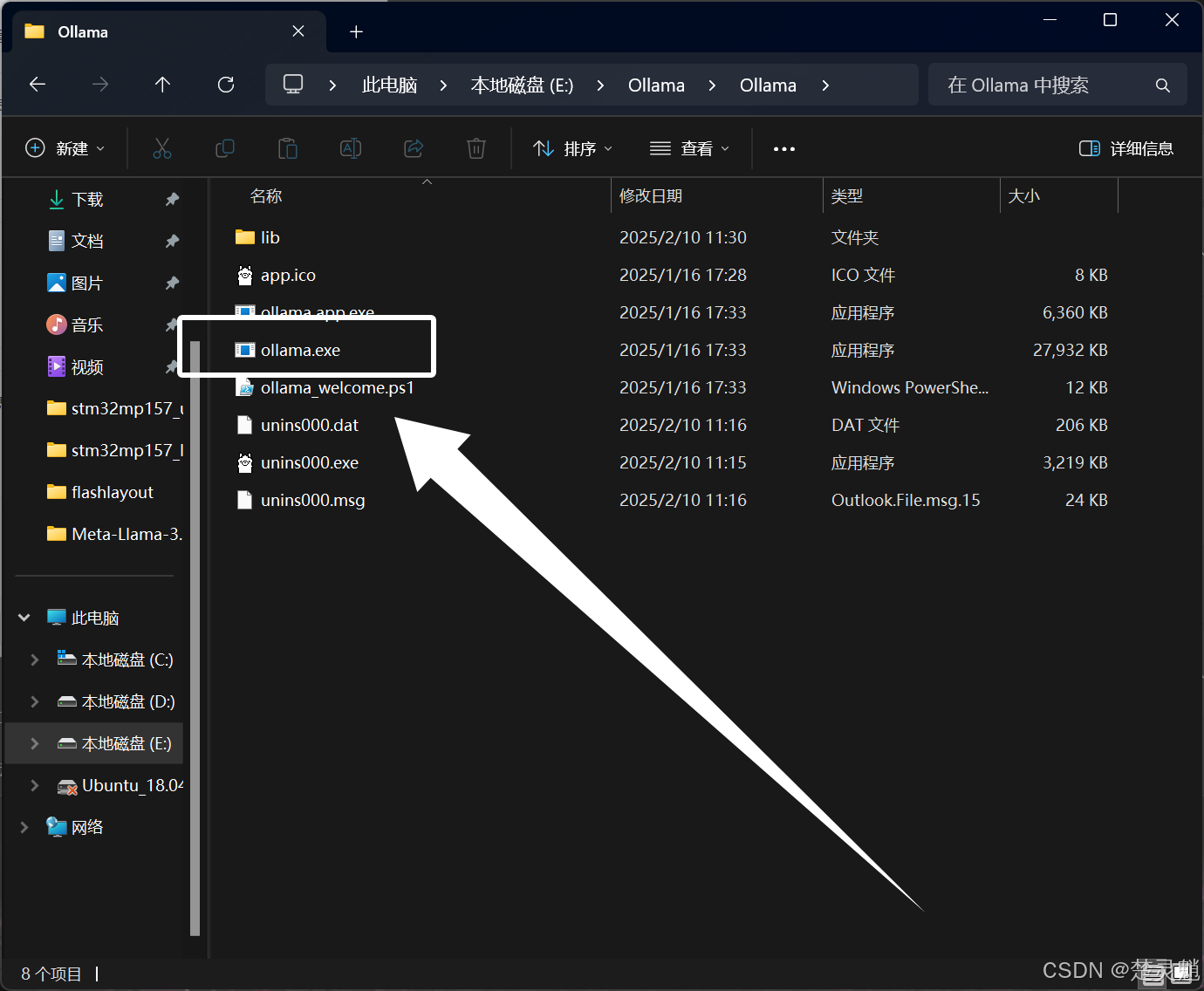
确定好就是这个文件夹以后,我们直接将其剪切到我们想放的目录,这里我将其剪切到E盘的新建的目录下:
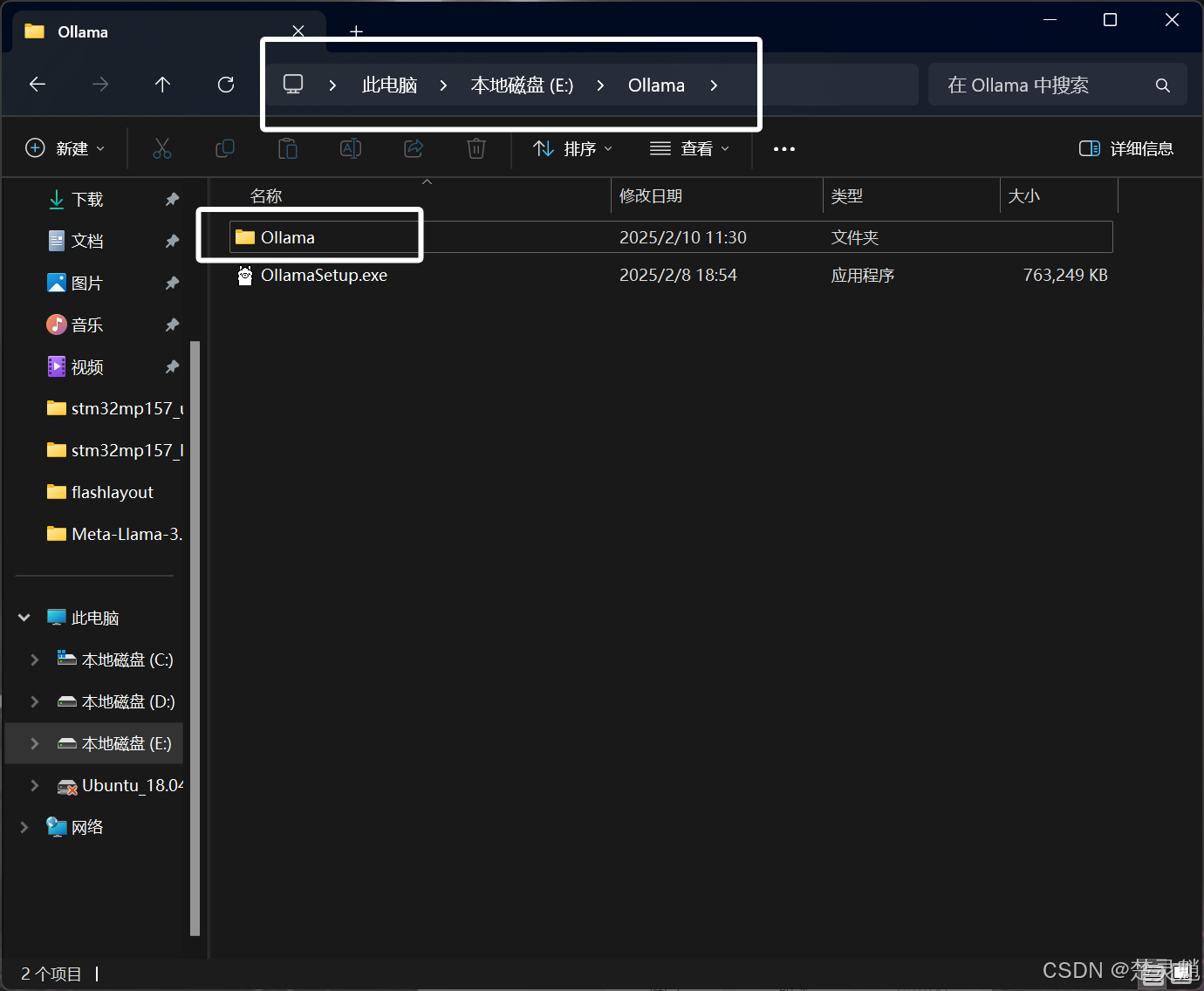
如果你在剪切时被提示什么文件被占用,你只需要在任务管理器或者任务栏中将Ollama结束掉即可。
现在光是剪切过来还不行,我们需要让我们的计算机能够找到这个程序,所以还需要修改一下环境变量,我们在设置中,找到系统信息,如图:
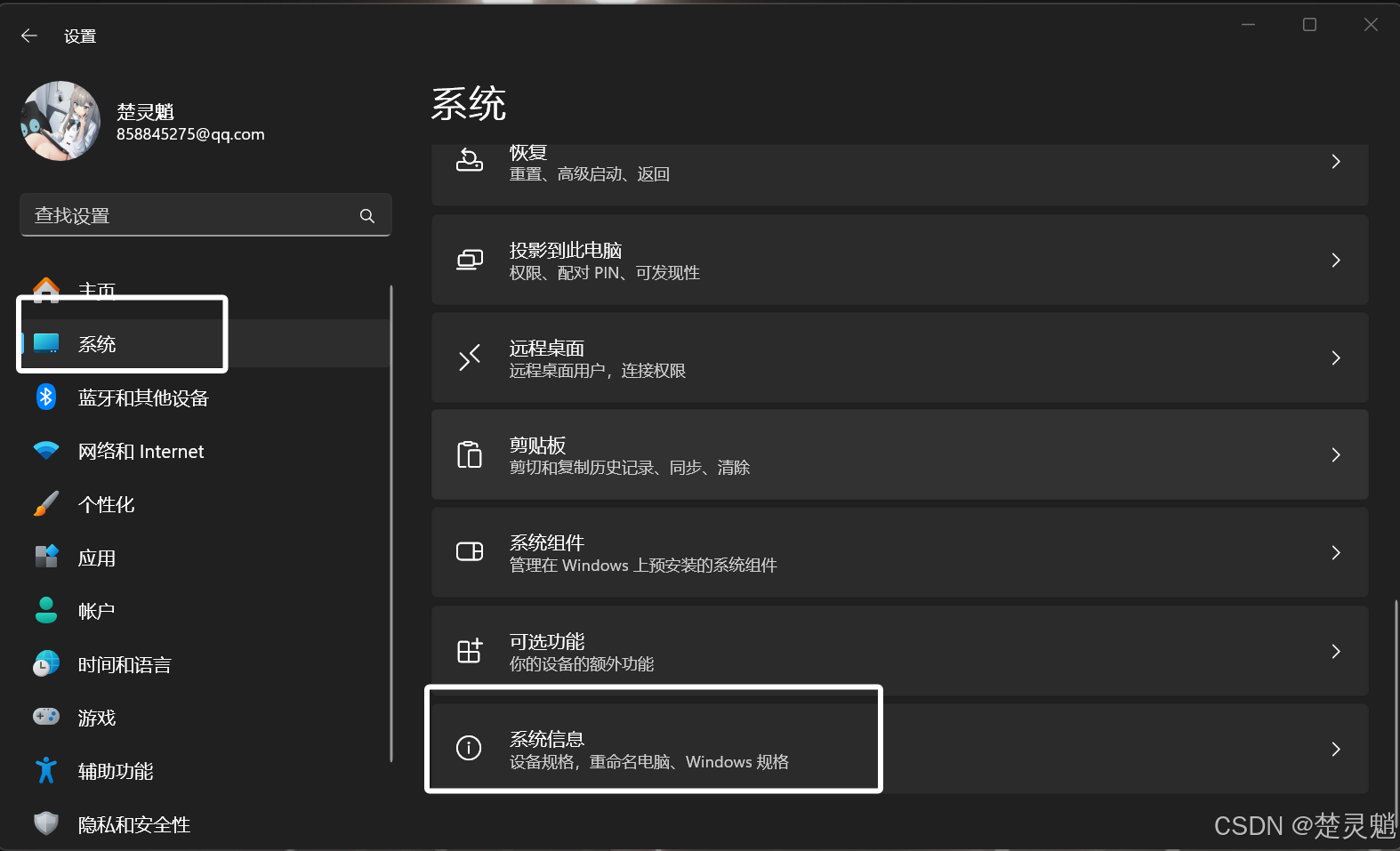
点击系统信息就能看到以下界面了:
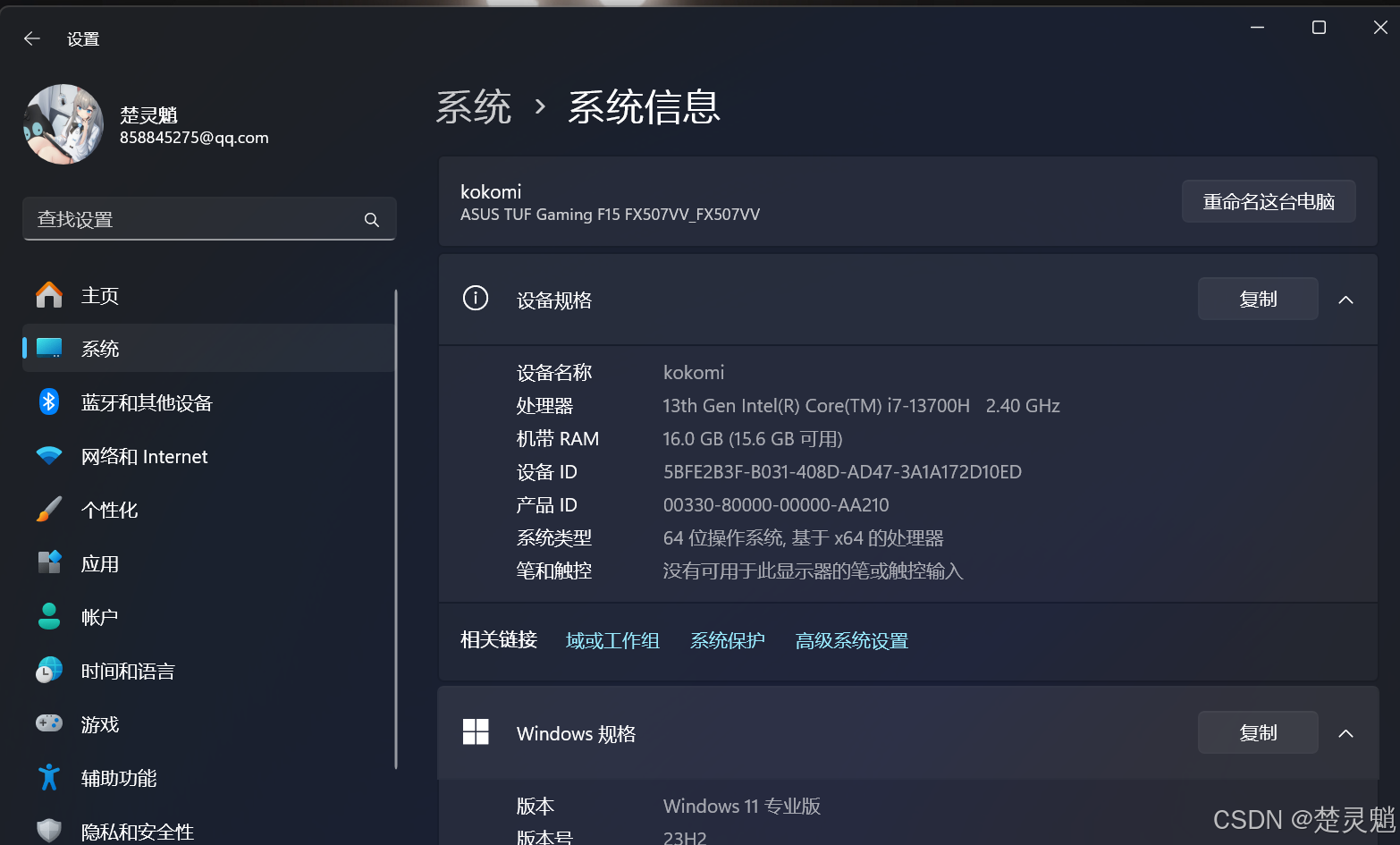
下面我们点击“高级系统设置”:
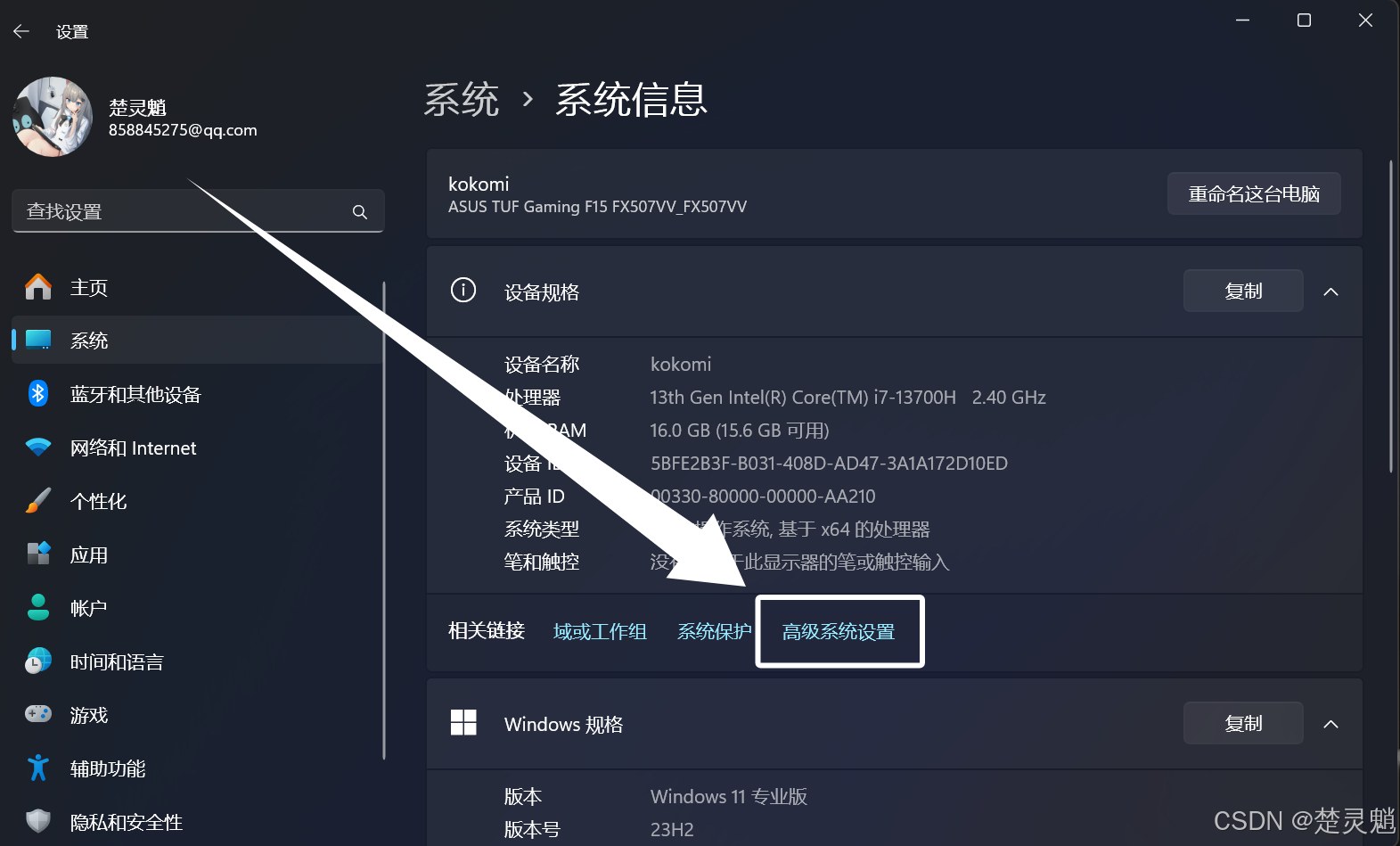
随后再点击“环境变量”:
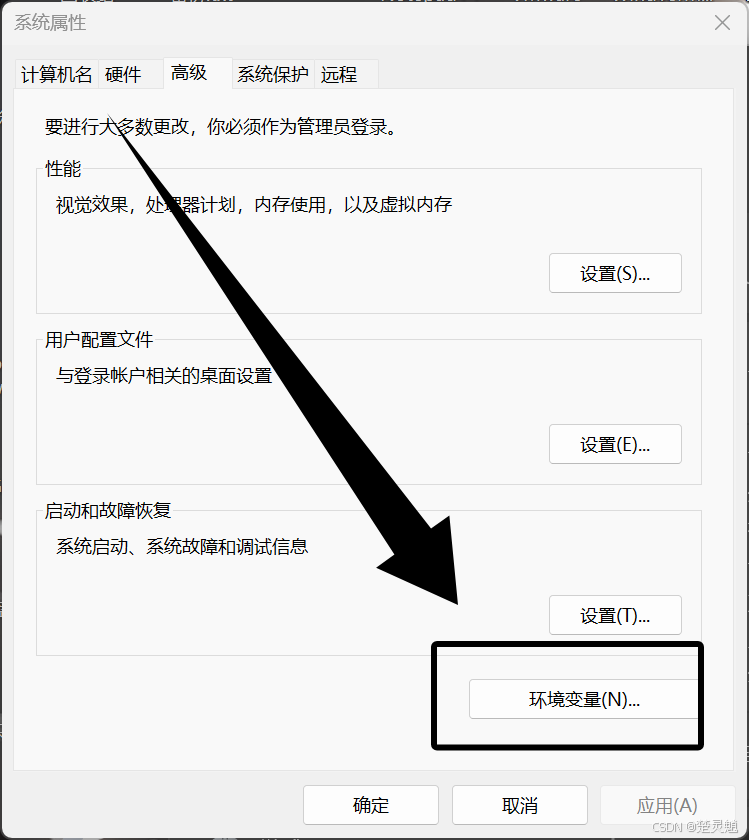
点击以后,就能看到以下界面了,这里我们主要修改用户环境变量,也就是上半部分:
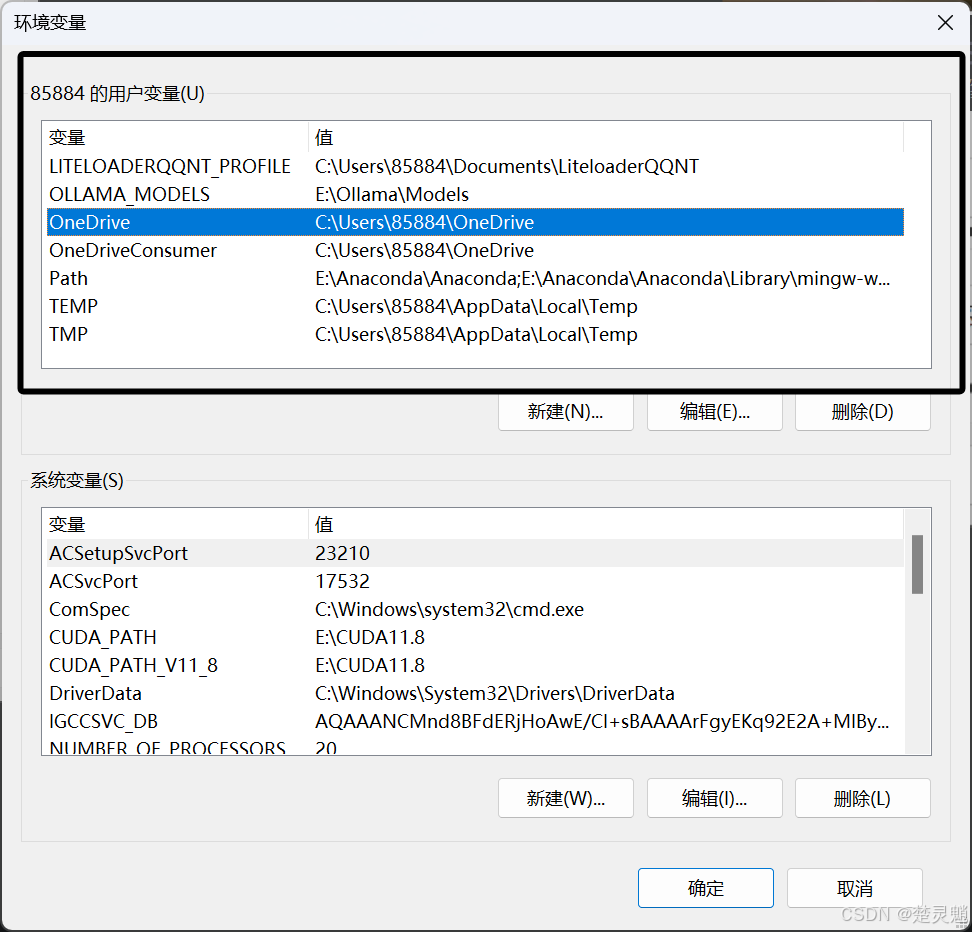
这里我们首先点击新建,我们要新建一个Ollama的模型路径环境变量,不然ollama的模型会一直放在C盘,非常占用空间,这里新建环境变量的名字是“OLLAMA_MODELS”,变量的值就是你想将Ollama模型存放到的路径,在添加环境变量时,可以使用“浏览目录”来快速选择目录:
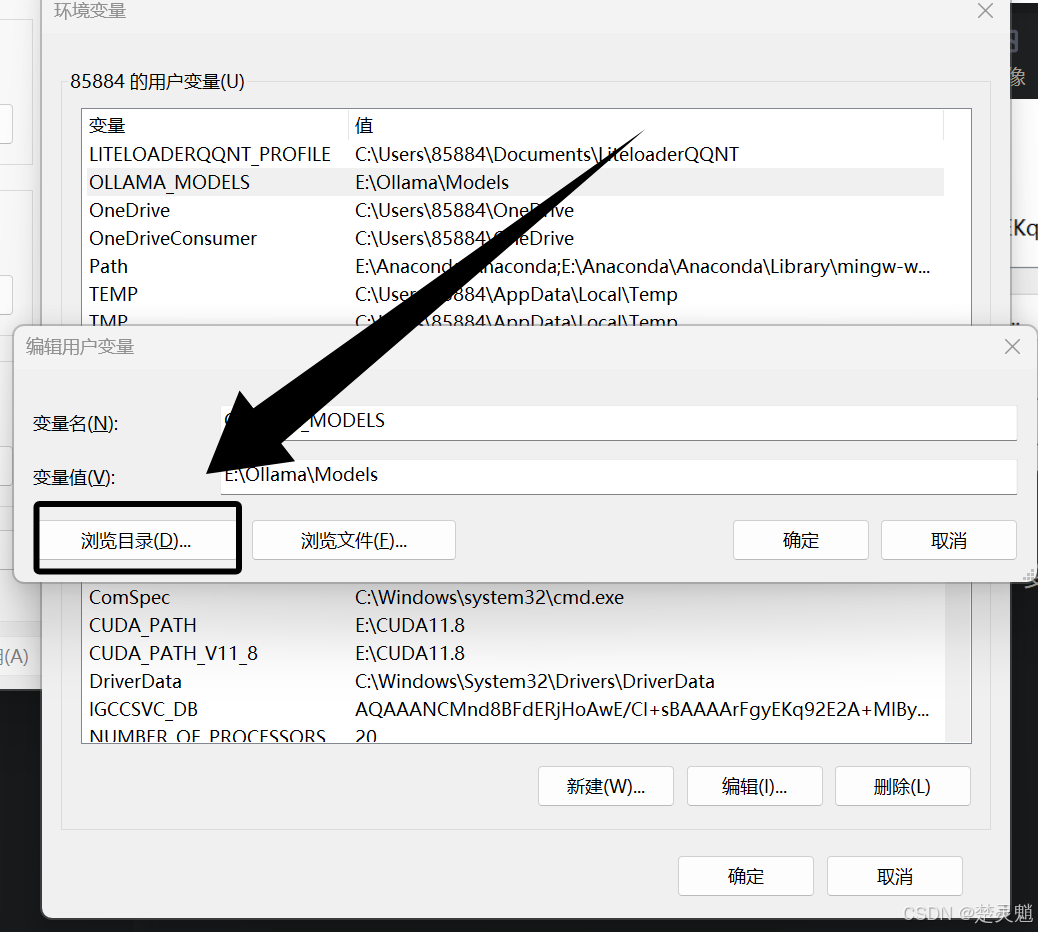
这里我讲Ollama的模型路径改到了E盘的Ollama目录下的Models文件夹下。
添加完成以后,如图所示:
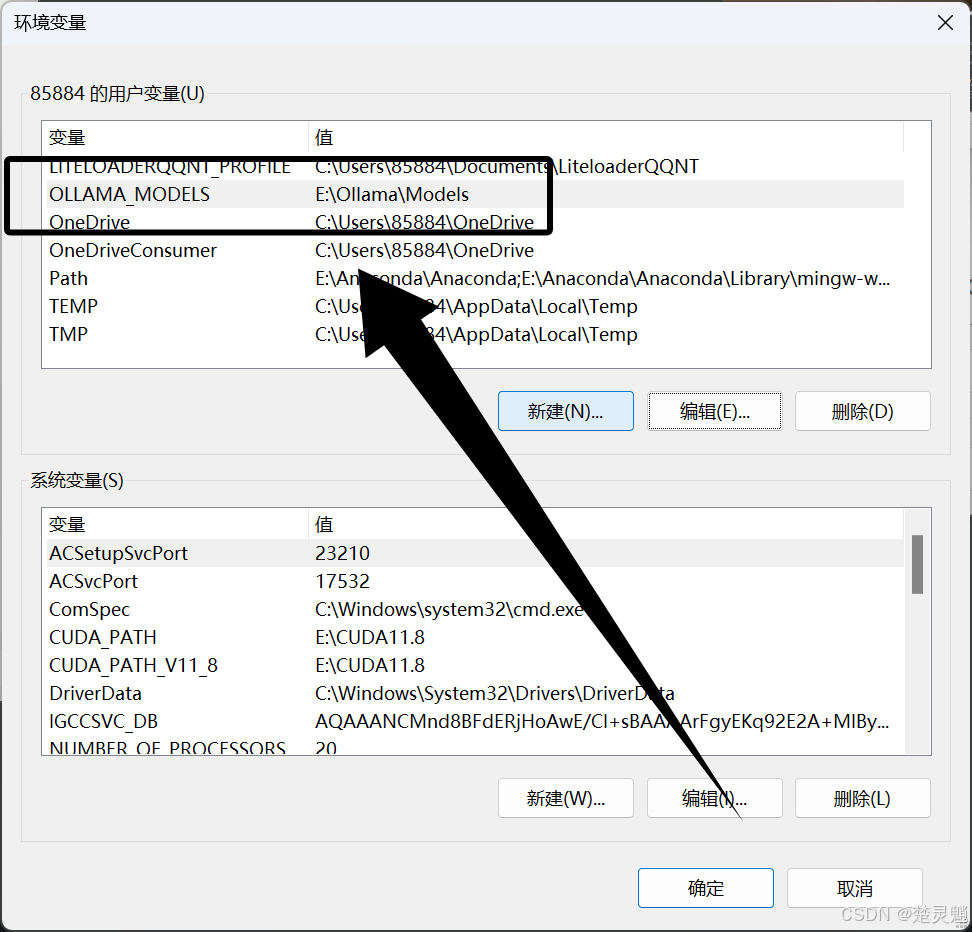
下面我们还要修改一下ollama路径的环境变量,这里我们双击“path”:
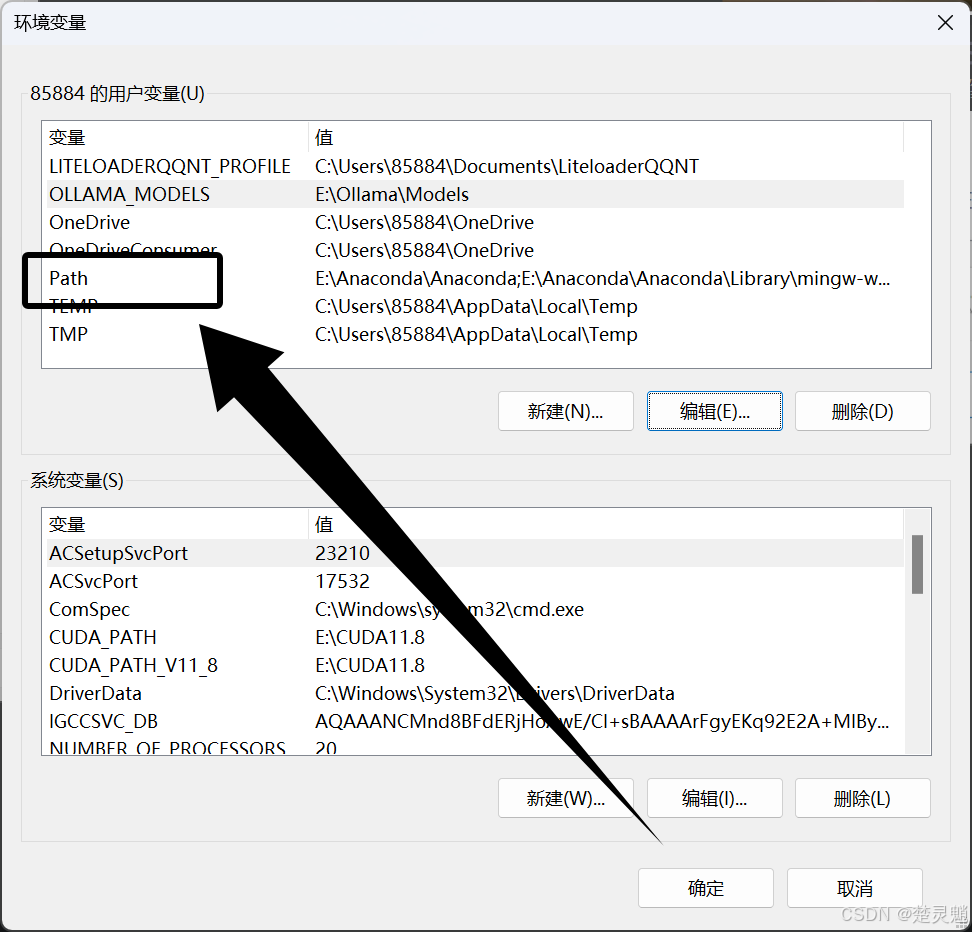
这里就可以看到一个与Ollama相关的路径:
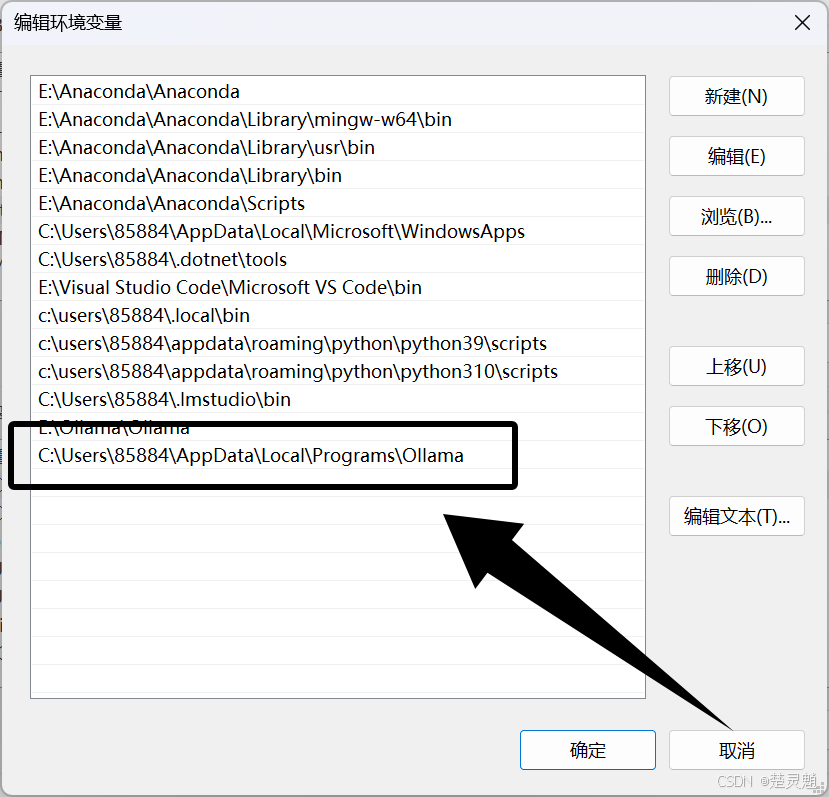
我们将这个路径改为现在Ollama所在的路径即可,注意这里的路径一定是有Ollama.exe文件所在的路径,如下图:
修改好以后,如图所示:
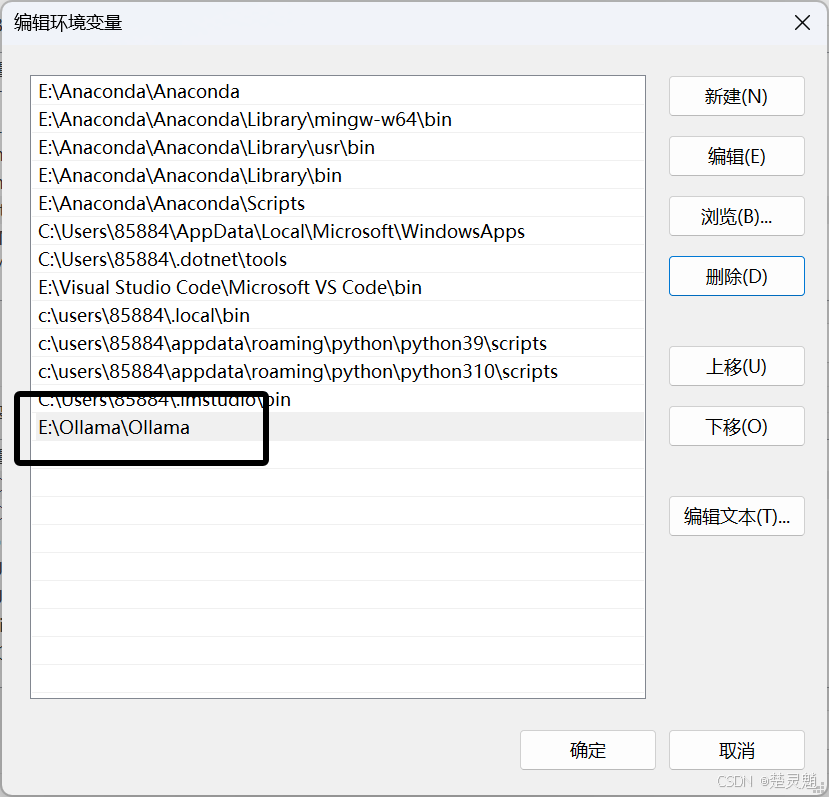
这里我们对每一个窗口都点击确定,一路确定下来即可。
完成环境变量的修改以后,建议大家重新登录用户,或者重启一次电脑确保环境变量的加载。
完成上面的步骤以后,我们打开终端,在终端中输入下面的命令查看上面的步骤是否成功:
ollama如果成功的话,就会出现下面的输出:
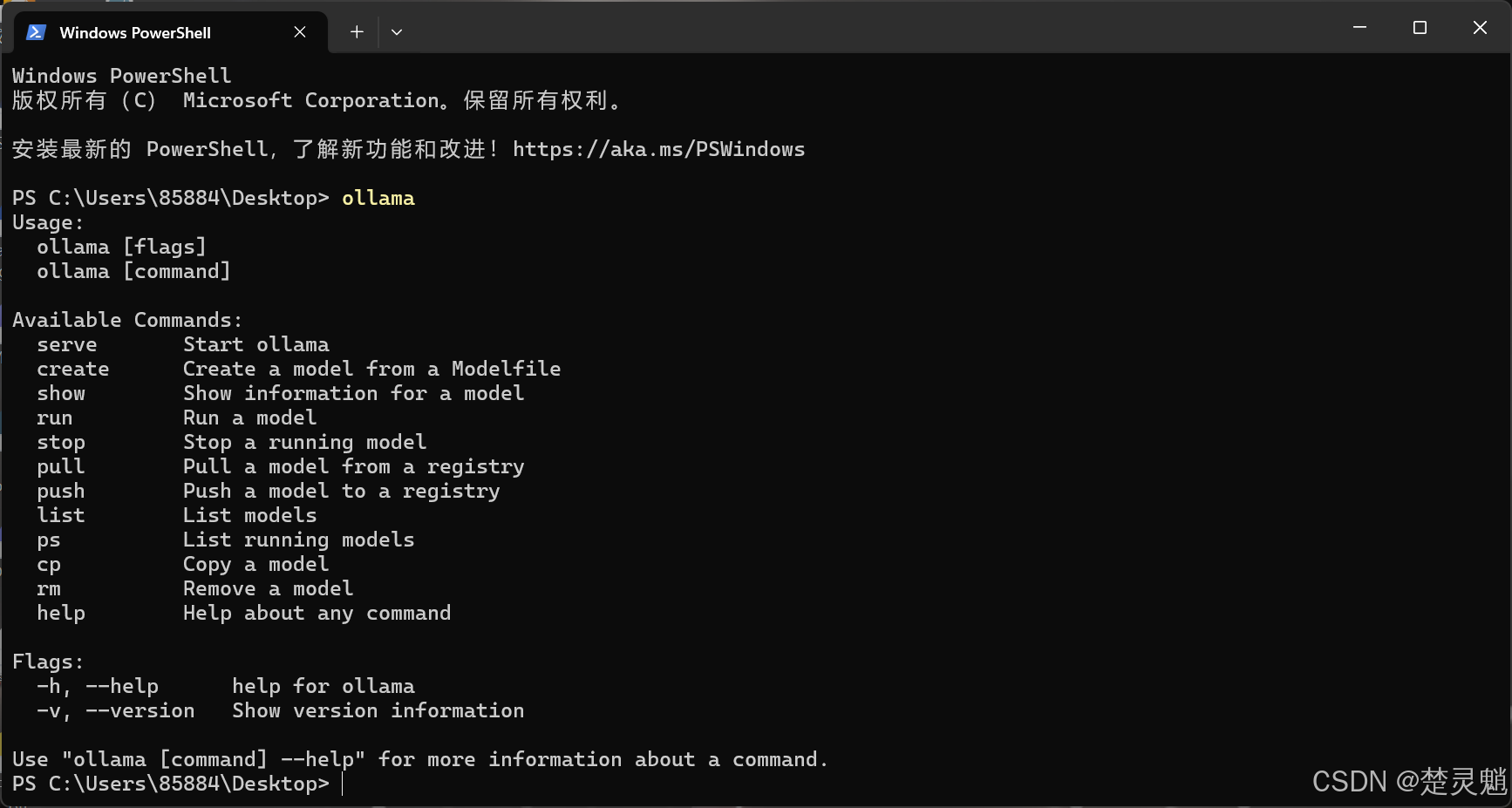
如果你被提示命令找不到,先检查被修改过的环境变量是否正确,然后可以尝试重启或者重新登录用户,重开一个终端等办法确保环境变量被正确加载。
至此,我们ollama的安装就完成了。
四、使用框架运行DeepSeek
1.模型的下载
现在,就来教大家如何使用我们已经安装好的框架来运行DeepSeek模型。既然这里我们需要运行模型,那么就需要下载一个模型。模型下载的话,推荐大家前往HF Mirror这是一个Hugging Face的模型镜像站,在国内可以直接访问,大家可以直接点击下方的链接前往 :
HF Mirror官网:HF-Mirror
进入以后,就能看到以下界面了:
往下滑,我们就能看到非常多的模型:
这里我们可以点击“更多”查看所有模型:
随后我们就能看到非常多的模型了:
我们直接在顶部的搜索框中搜索“deepseek”:
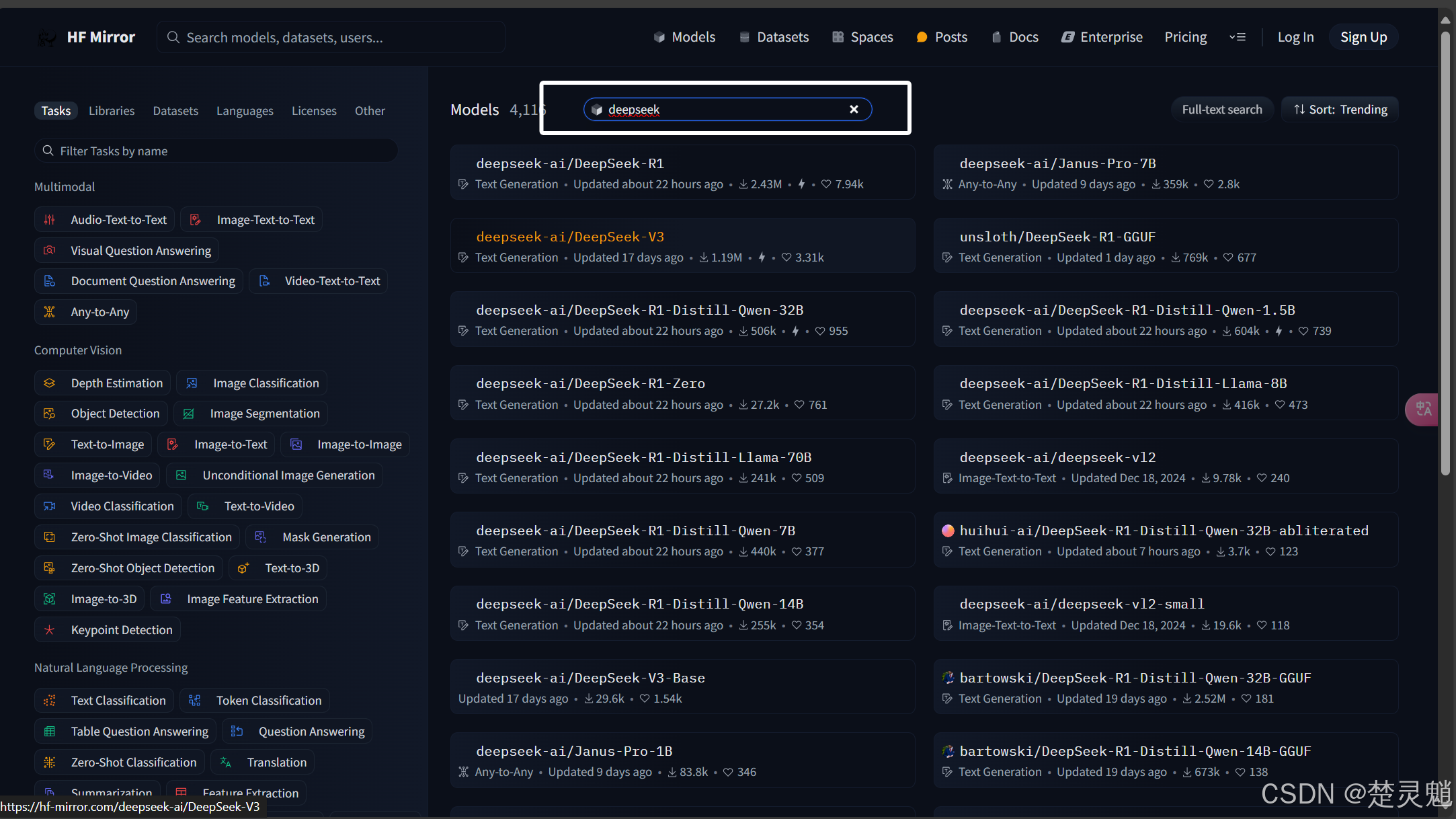
大家可能发现了,我们搜索出来的模型有些奇怪,比如我们单拿出一个模型的名字来说,就拿“DeepSeek-R1-Distill-Llama-8B-GGUF”这个名字来说,大家可能有疑问,为什么这个模型前面是DeepSeek-R1后面又是Llama,这到底是个什么模型,其实秘密就藏在两个模型之间的“Distill”字段中,Distill指的是知识蒸馏,是一种模型压缩技术,它可以使一个小模型来模仿一个大模型的行为从而将大模型的知识蒸馏到小模型中,当然这里说的小,就是指的参数的小。比如这里的llama模型就是小模型。然后就是这个模型最后的GGUF,这是一种特殊的模型存储格式,并且我们的Ollama与LM Studio都只能运行GGUF格式的模型,至于如何将其它格式的模型转换为GGUF我们后面教程再讲。
这里我们进入一个模型的主页就能看到以下界面:
下面我们可以点击“Files and Version”:
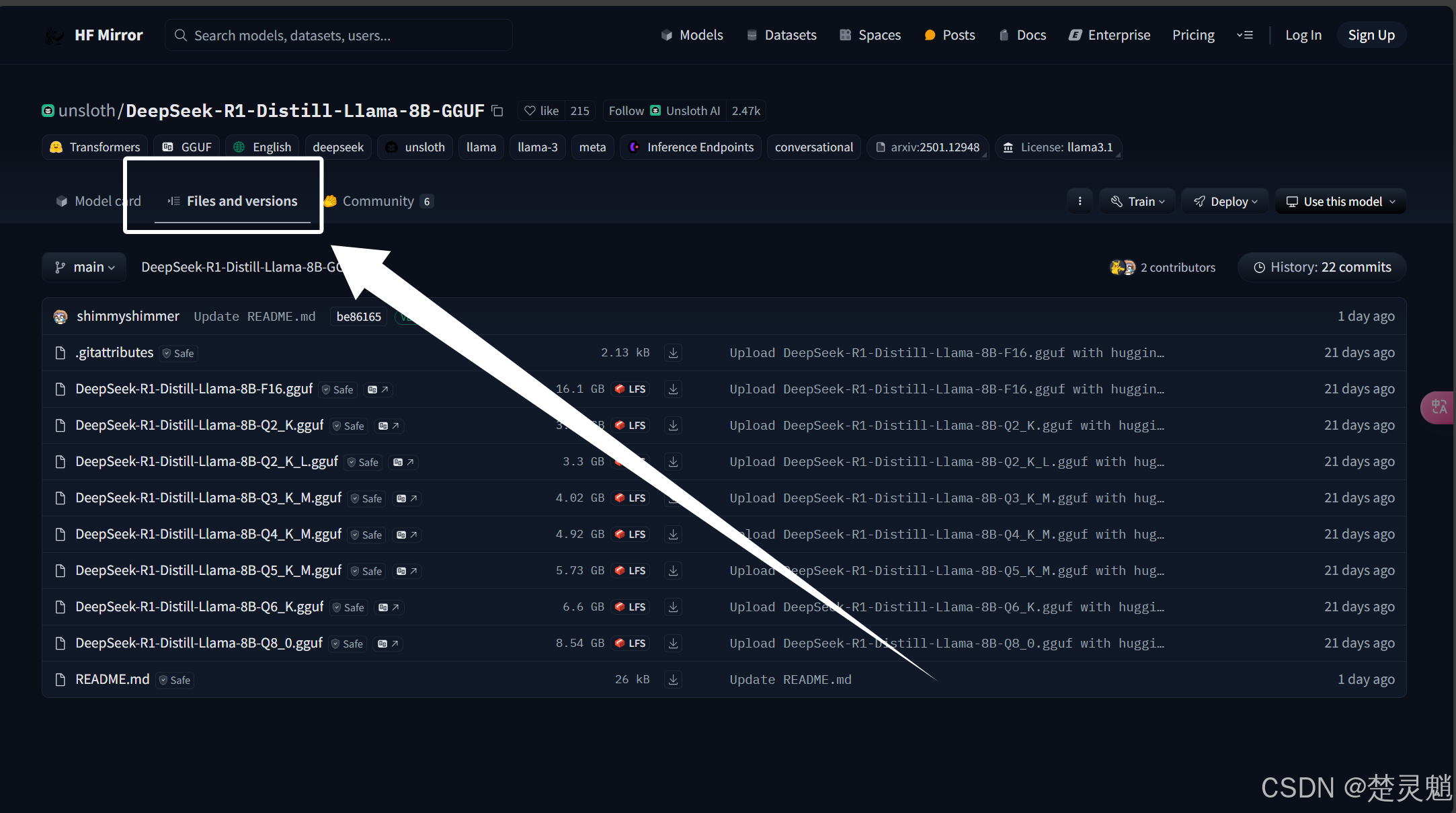
进来以后,就能看到非常多的模型了。大家可能会好奇,这些模型后面的Q2,Q3,Q4是什么意思,这其实是指的模型的量化技术,表示2bit,3bit,4bit量化。量化过的模型运行时占用的显存会减少,并且对设备的负载也会降低。大家可以通过模型的体积来选择模型。假如我有4GB显存,那我就选择大小在4GB以下的模型,当然,这只是粗略的估计,可能随着一些参数的变化并不准确。大家可以去查看一些博主做好的对照表。
这里我们点击一个模型进入下载界面:
进入下载界面以后点击“download”:
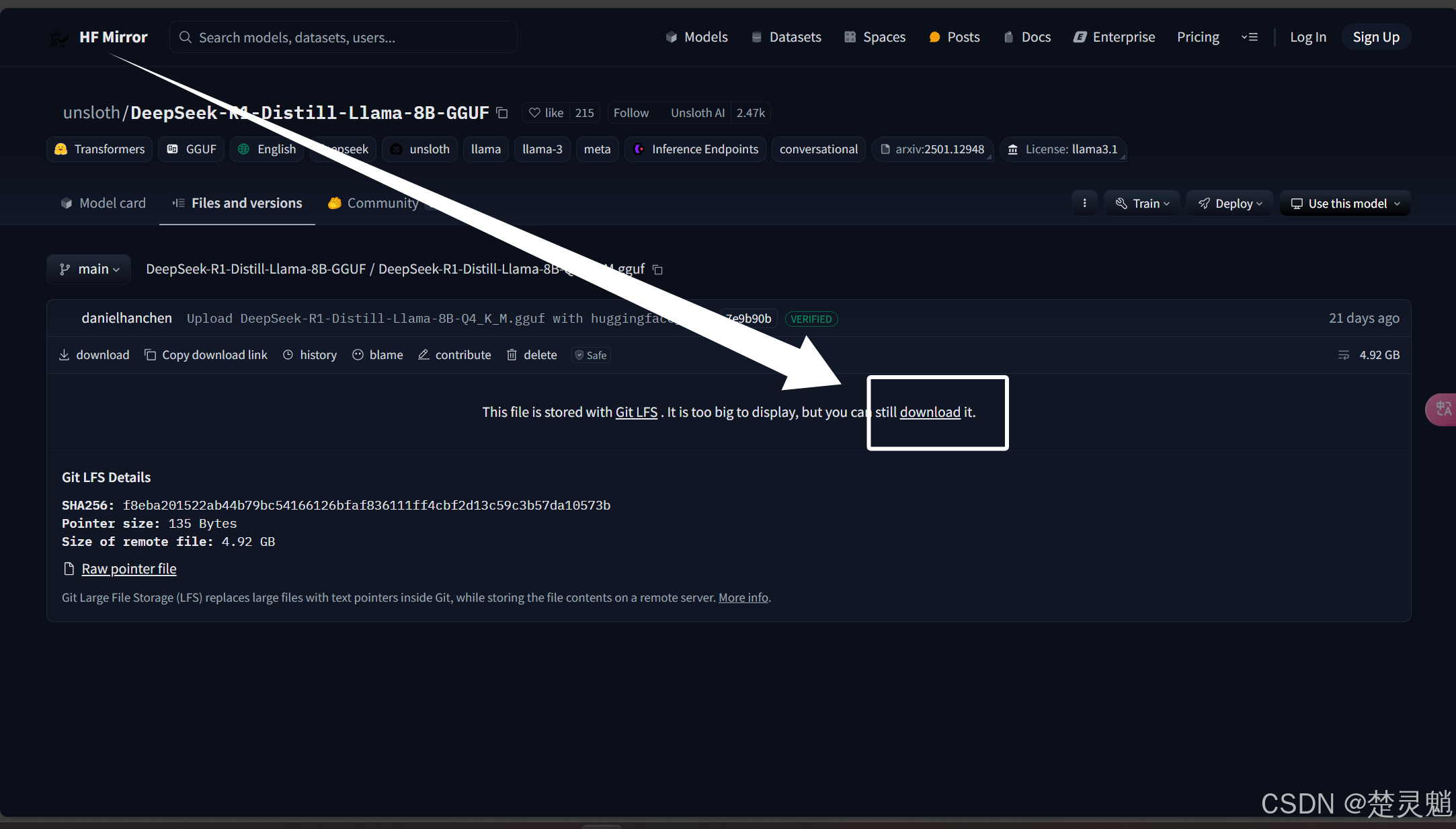
随后浏览器就会开始下载了:
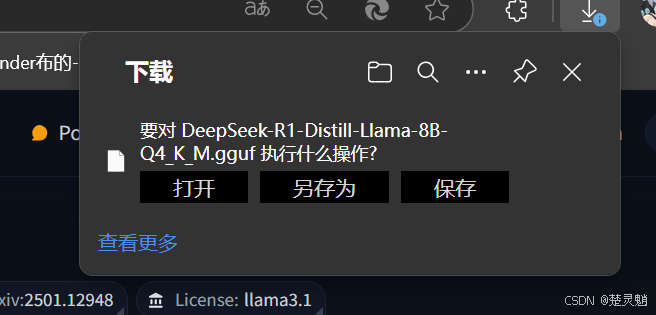
这里的模型比较大,下载也比较久,大家可以借助一些下载工具进行下载。
这里我已经下载好了一些模型,下面会为大家演示如何使用前面已经安装好的框架来运行一个GGUF格式的模型。大家也可以根据自己的硬件情况来选择模型。
2.LM Studio运行GGUF格式模型
下面我就使用我已经下载好的模型进行演示,这里我使用的是我已经下载好的“DeepSeek-R1-Distill-Llama-8B-Q2_K.gguf”模型: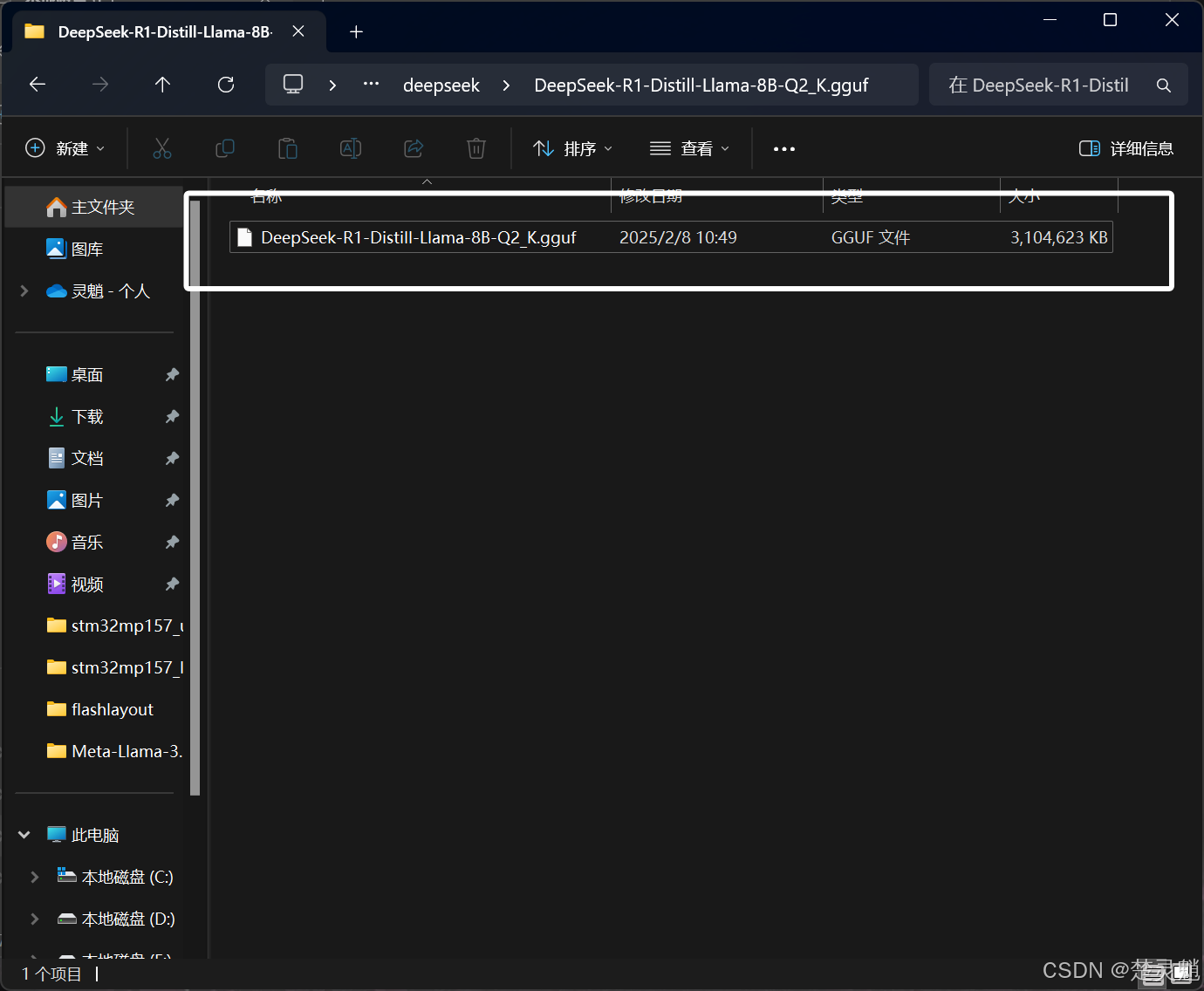
这里我们先将模型放到指定的路径,如果你是小白,我不建议你修改这些操作,后面的步骤很重要。我们在LM Studio安装的文件夹中新建一个名为“Models”的目录:
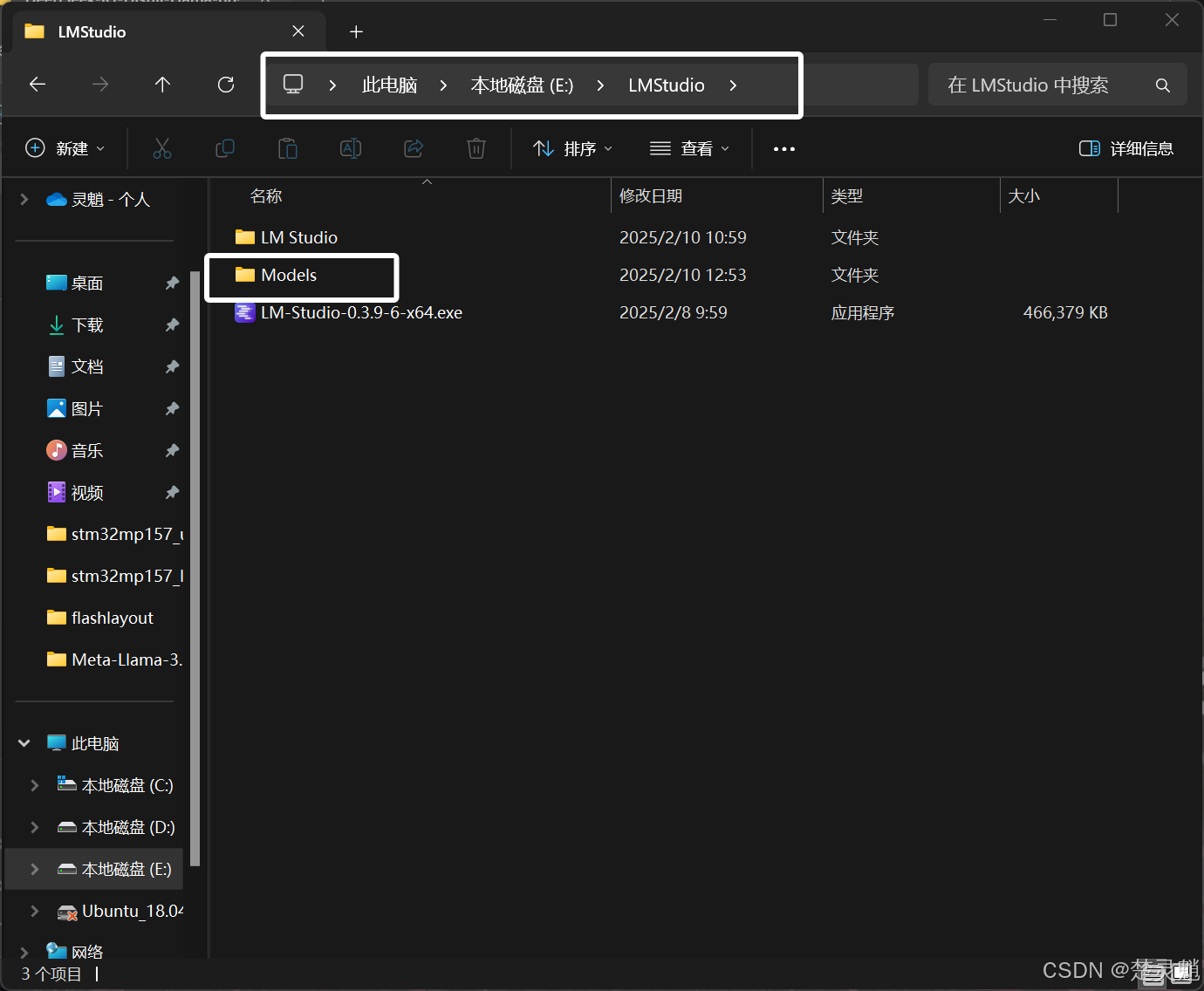
然后在这个“Models”目录中新建一个名为“DeepSeek”的目录,表示用于存放DeepSeek的模型:
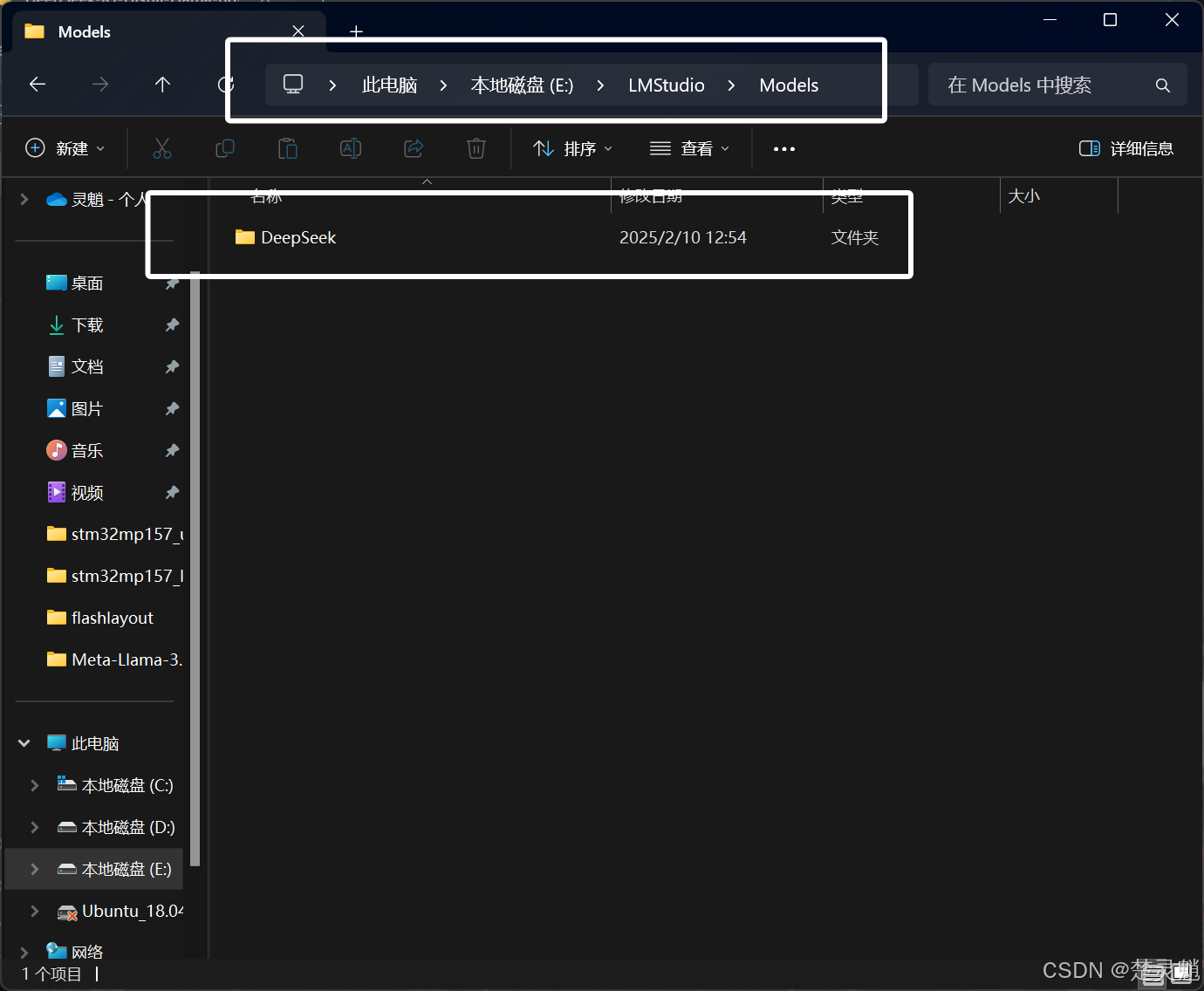
然后我们在这个DeepSeek的目录中新建一个我们模型名字的文件夹,假如我的模型叫“DeepSeek-R1-Distill-Llama-8B-Q2_K.gguf”那我新建文件夹的名字为“DeepSeek-R1-Distill-Llama-8B-Q2_K”: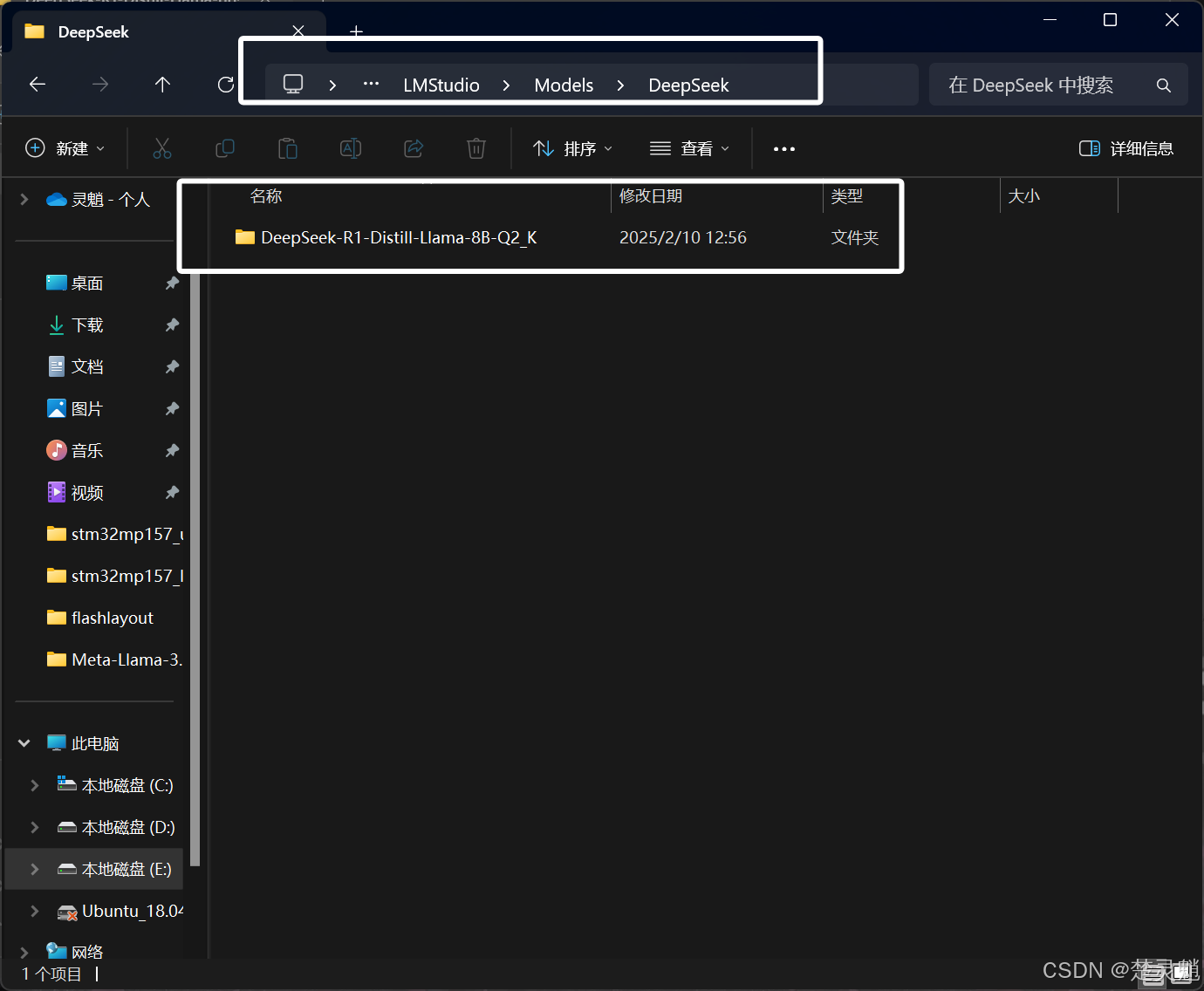
最后,我们需要将我们下载模型复制到这个以模型名来命名的文件夹中:

这样,我们的模型路径就已经处理好了,然后我们启动LM Studio:
这里我们可以点击右下角的设置将LM Studio的语言修改为中文:
然后我们点击左边文件夹的图标:
这里我们需要选择一下模型目录,模型目录我们直接选择到Models目录就可以了,注意,这里只需要选择到Models目录:
模型目录选择正确以后,我们刚刚的模型就可以被看到了:
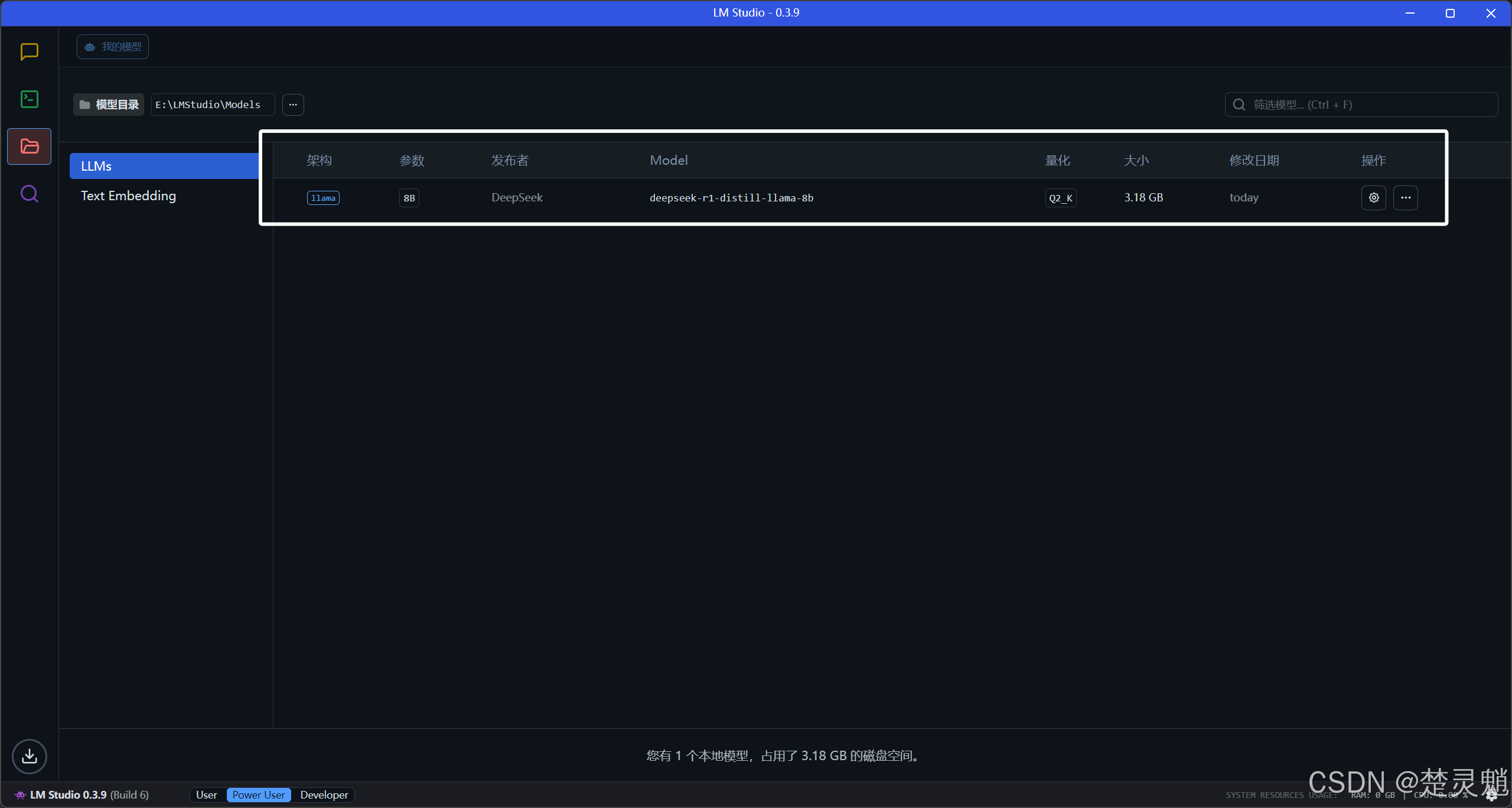
如果你这里的模型没有出现,那就需要看看模型的路径是不是放对了,这里的选择是不是正确的。
模型正确加载以后,我们点击“聊天”:
如果你和我一样这里没有聊天的话可以点击中间的按钮新建一个聊天:
然后我们点击上面框加载模型:
这里直接点击要加载的模型即可:
如果你是小白,那么这些参数不要动,随后点击“加载模型”:
要等进度条走完,模型才算加载完了:
然后,我们就可以在下面与模型进行对话了:
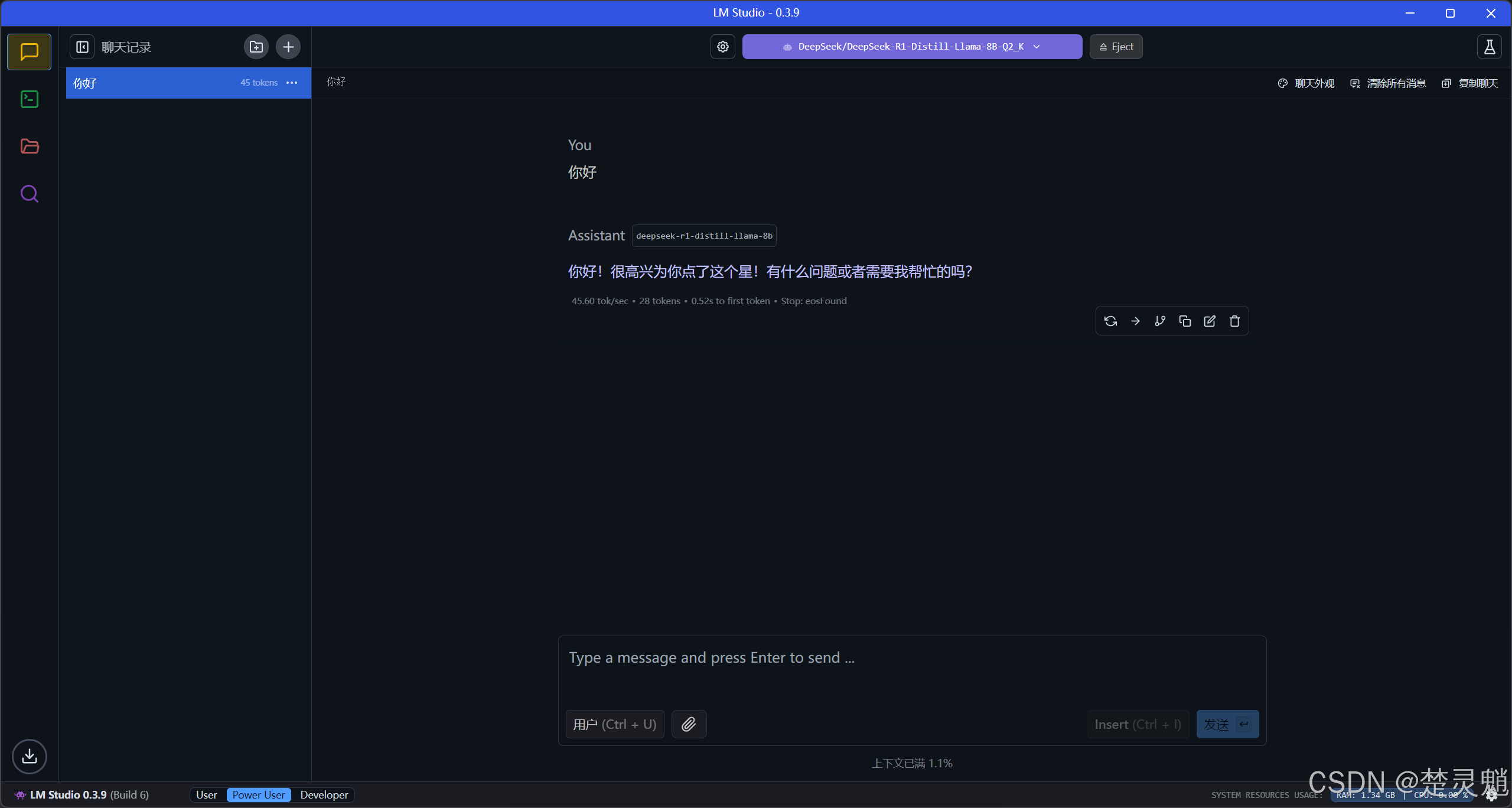
至此,我们使用LM Studio运行GGUF格式的模型就已经完成了。
3.Ollama直接运行DeepSeek模型
Ollama有自己的模型仓库,我们可以直接使用Ollama的相关命令直接拉取DeepSeek模型,我们直接在终端中输入下面的命令来拉取DeepSeek模型:
ollama pull deepseek-r1:7b输入命令以后,就开始了模型的拉取:
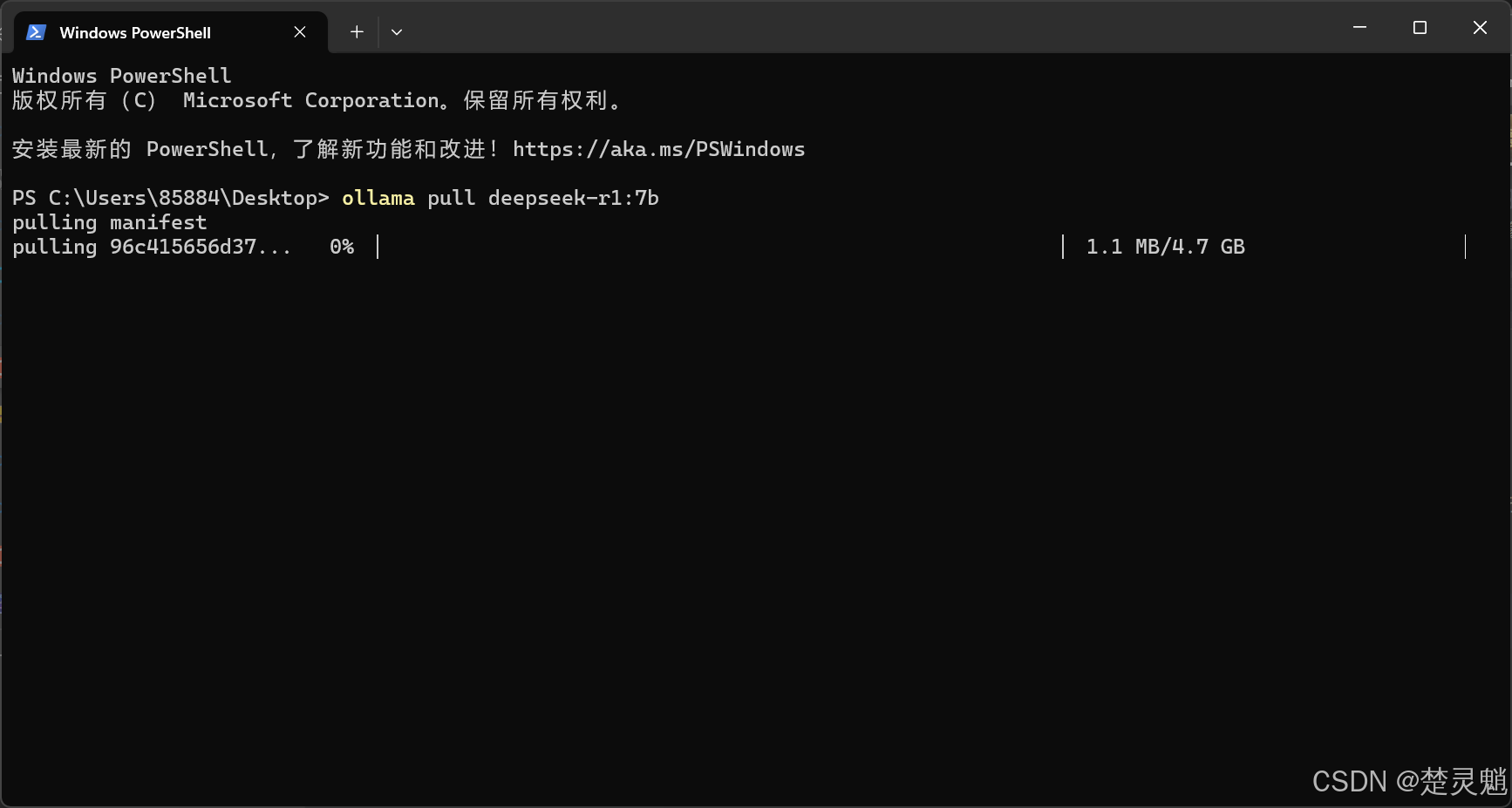
当然,如果你这里被提示拉取失败或者是网络错误,也不用担心,Ollama可以直接运行GGUF格式的模型,请跳转到“四.4”。
这里模型下载到后面可能会很慢,大家如果觉得实在是太慢了可以按“Ctrl+C”结束掉,再下载,它会在截断的地方继续下载,并且速度会有相应的提升。
模型下载完以后,如图所示:
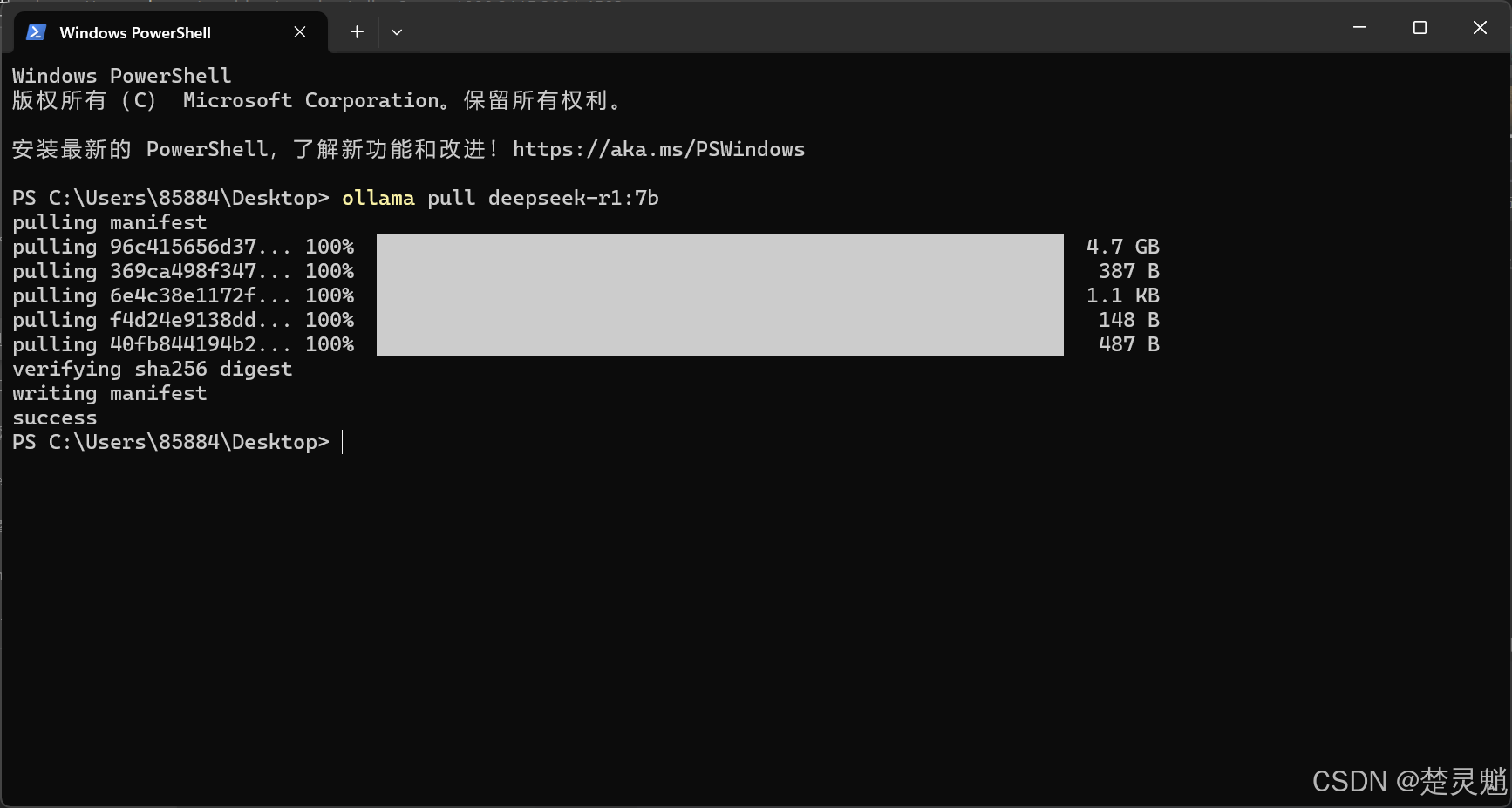
我们可以使用下面的命令来查看我们已经下载的模型:
ollama list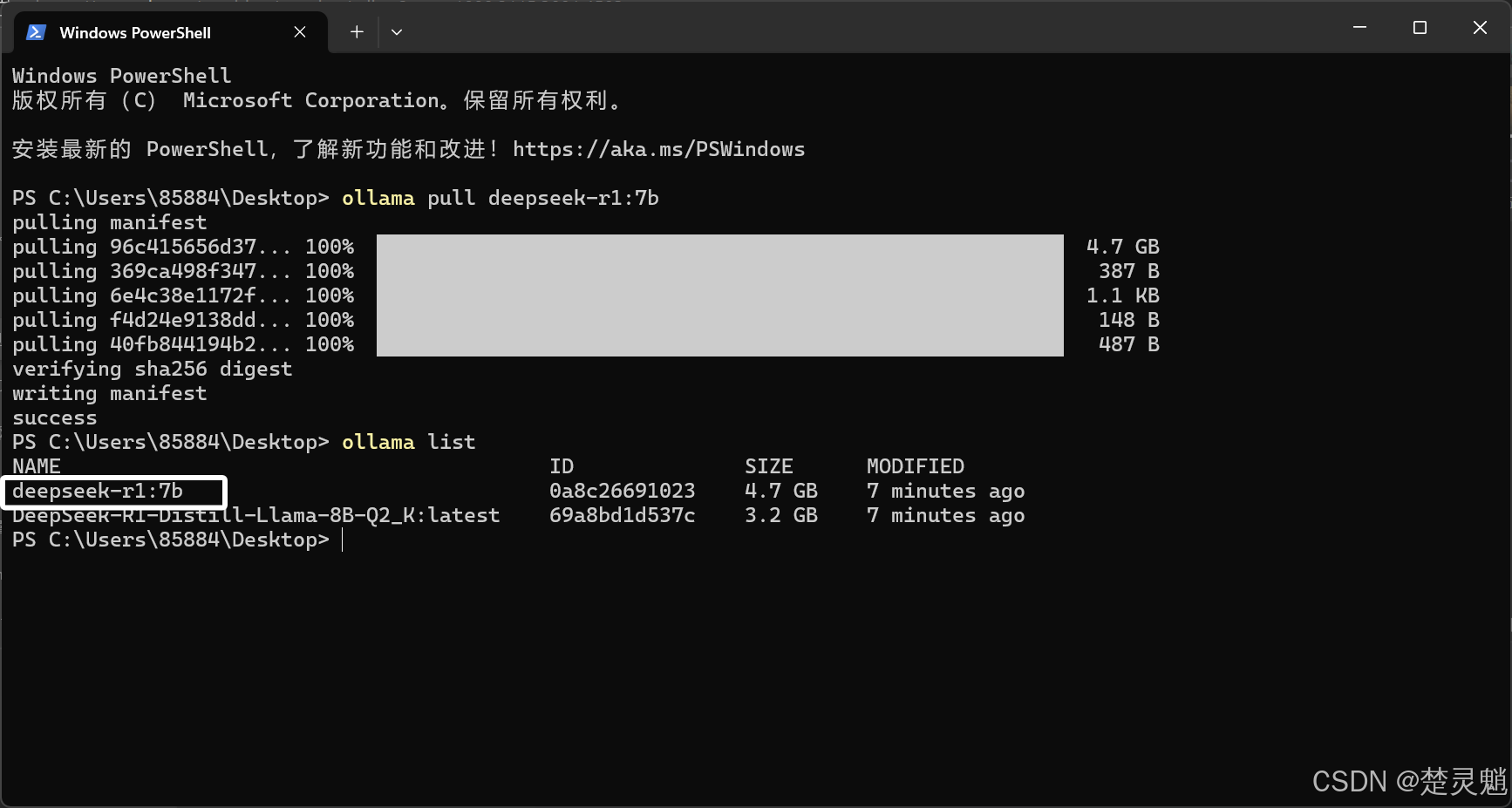
还记得一开始我们设置的环境变量吗?这些模型就被下载到了我们所设置的环境变量所对应的路径中:
当然,这都是用哈希值命名的,看起来非常奇怪,我们也不用去看。
我们可以使用下面的命令来运行我们已经下载好的模型:
ollama run deepseek-r1:7b这里的deepseek-r1:7b是模型的名字,也可以替换成别的。
模型运行以后,就可以直接对话了:
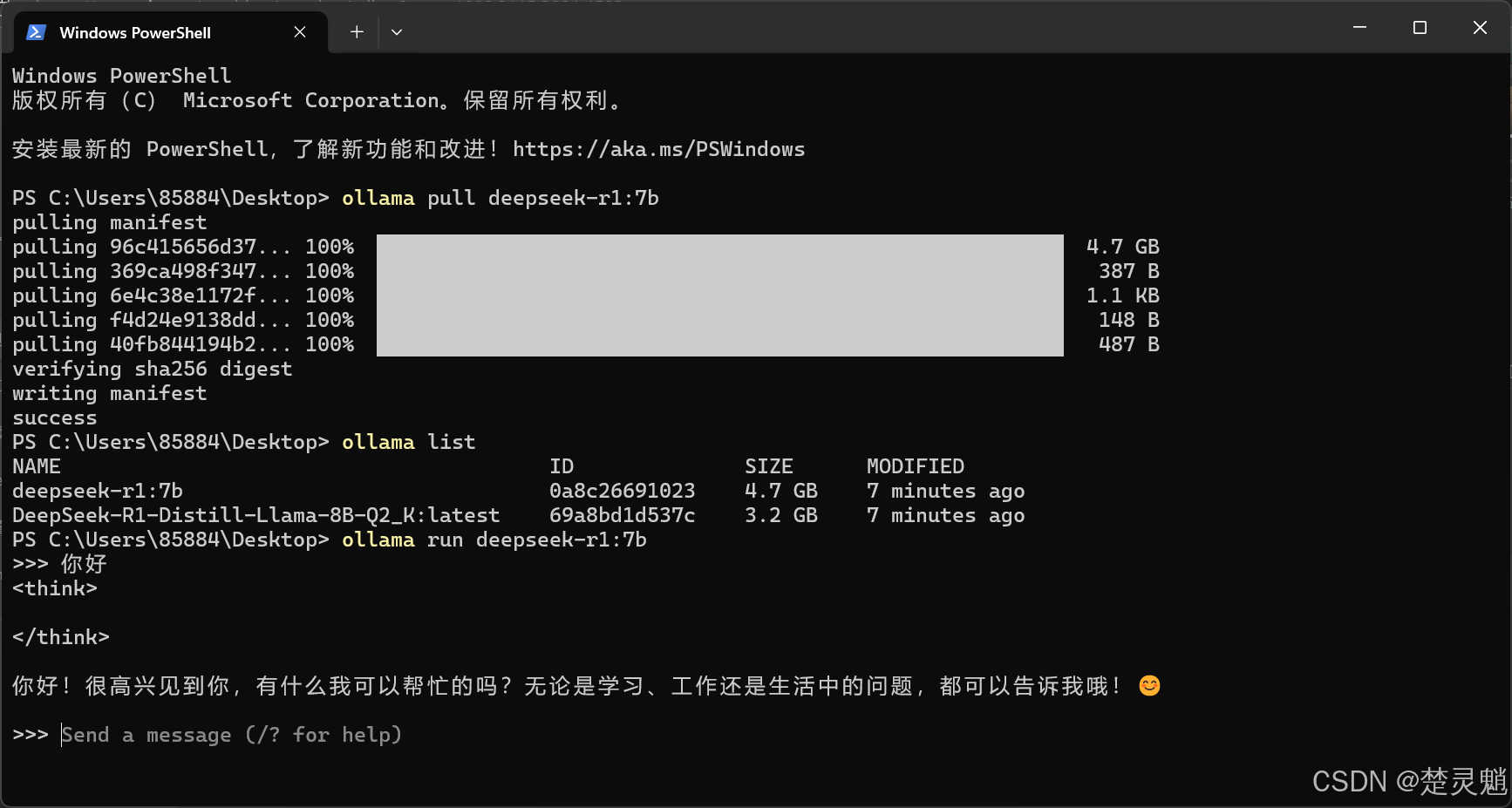
当然我们使用ollama pull下载的都是ollama仓库的模型,有些模型并没有在ollama的仓库中,我们又要怎样使用ollama运行呢?那么大家就可以看下面的“Ollama运行GGUF格式模型”教程。
至此,我们使用Ollama直接运行DeepSeek模型就已经完成了。
4.Ollama运行GGUF格式模型
这里同样需要我们已经下载好一个GGUF格式的模型,如图:
然后,我们需要在这个有模型的文件夹下新建一个文本文件,将其命名为“Modelfile”,注意,这里是没有后缀名的:
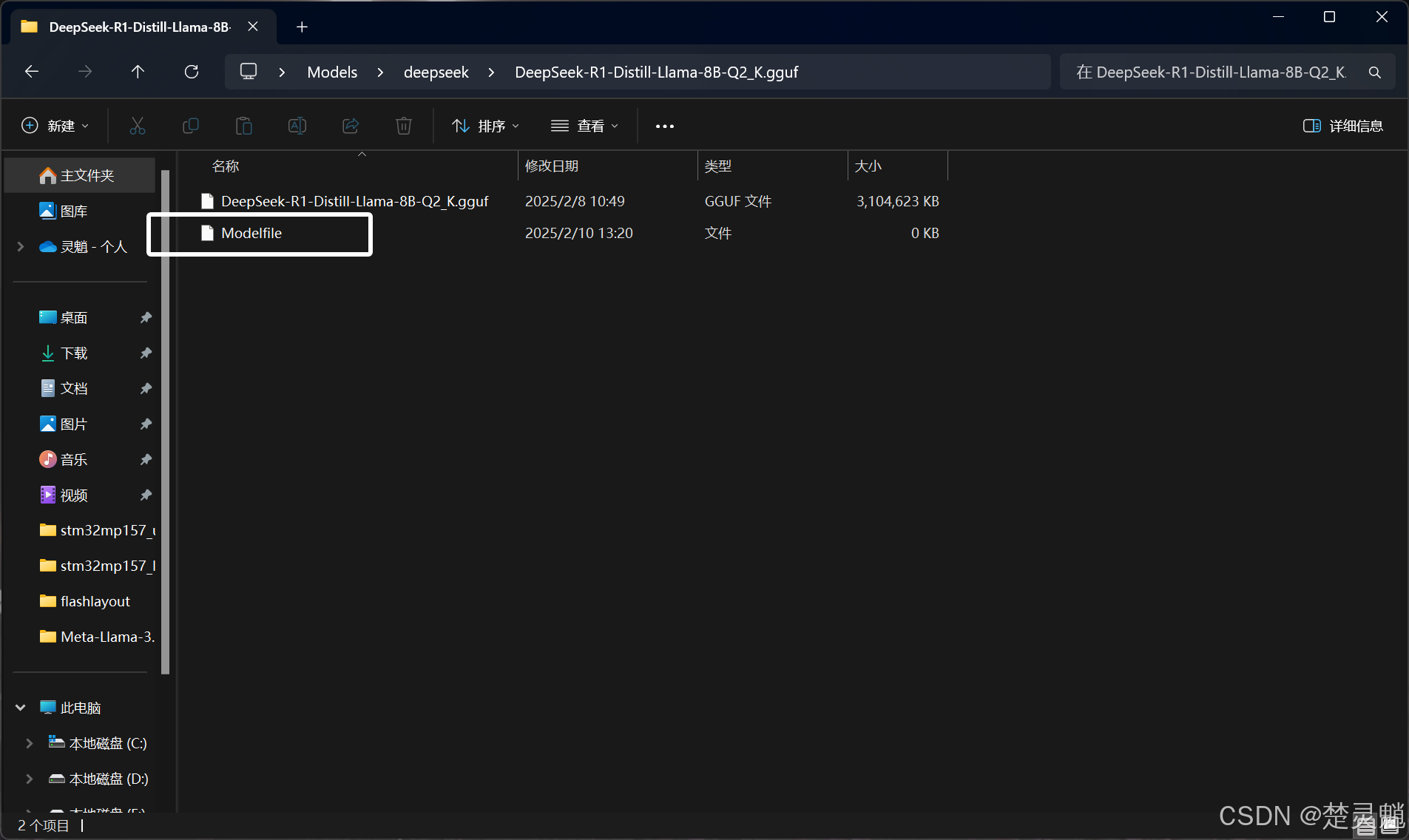
然后我们需要用记事本打开这个文件,将下方的代码复制到其中:
FROM ./DeepSeek-R1-Distill-Llama-8B-Q2_K.gguf注意,这里的“./”后面是你的模型名字,也就是刚才准备的模型的名字。我这里叫“DeepSeek-R1-Distill-Llama-8B-Q2_K.gguf”你的可能不一定是这个,请自己修改。修改好文件以后,保存并退出即可。
然后就在我们创建了“Modelfile”的文件夹内,打开终端执行下面的命令:
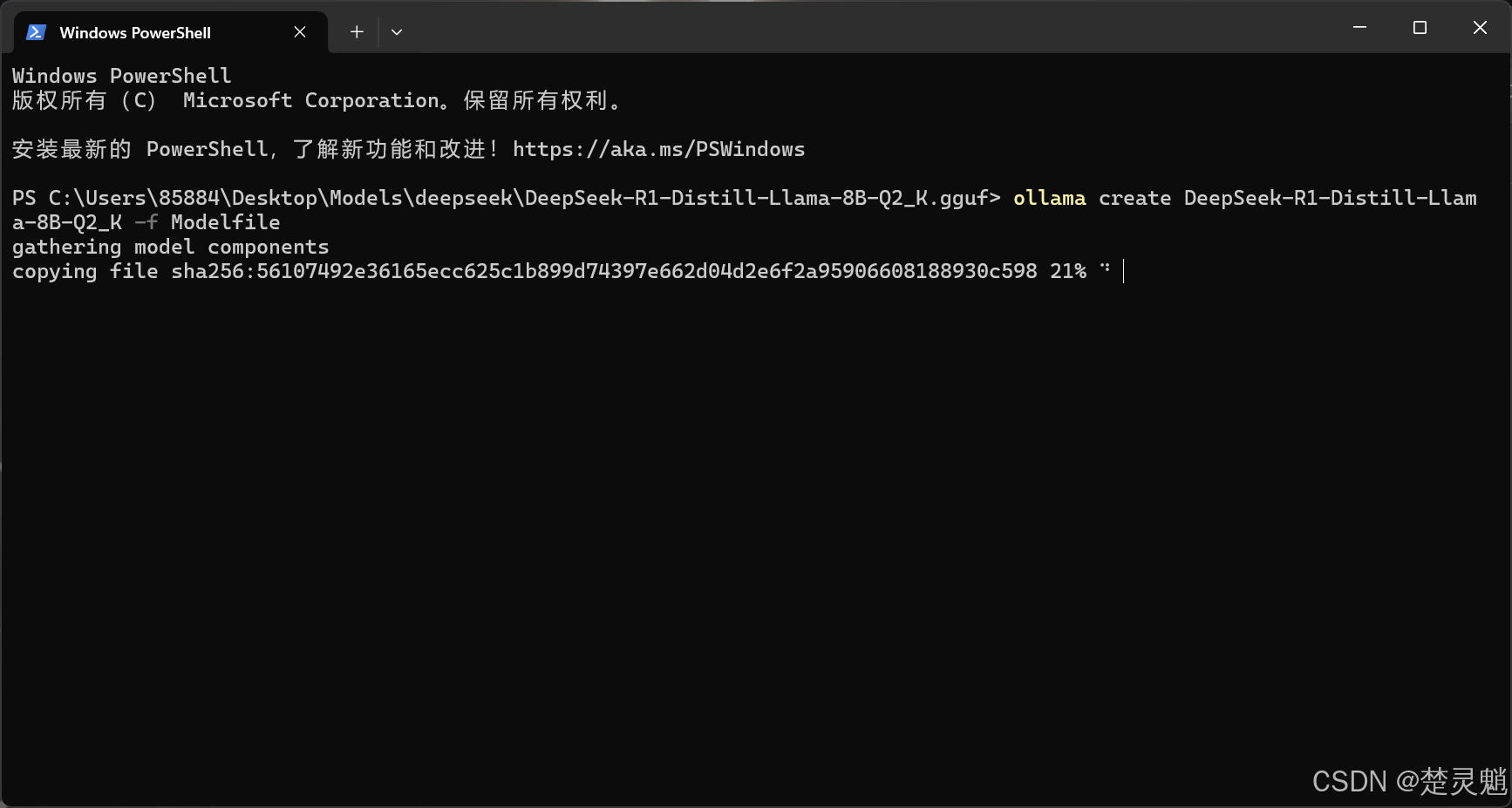
ollama create DeepSeek-R1-Distill-Llama-8B-Q2_K -f Modelfile注意,这里“create”后面的名字也有讲究,这后面表示的是模型导入到Ollama后的名字,大家可以自己定义。
命令执行以后,Ollama就会开始导入模型了:
模型导入以后,我们就可以使用下面的命令来查看我们的模型:
ollama list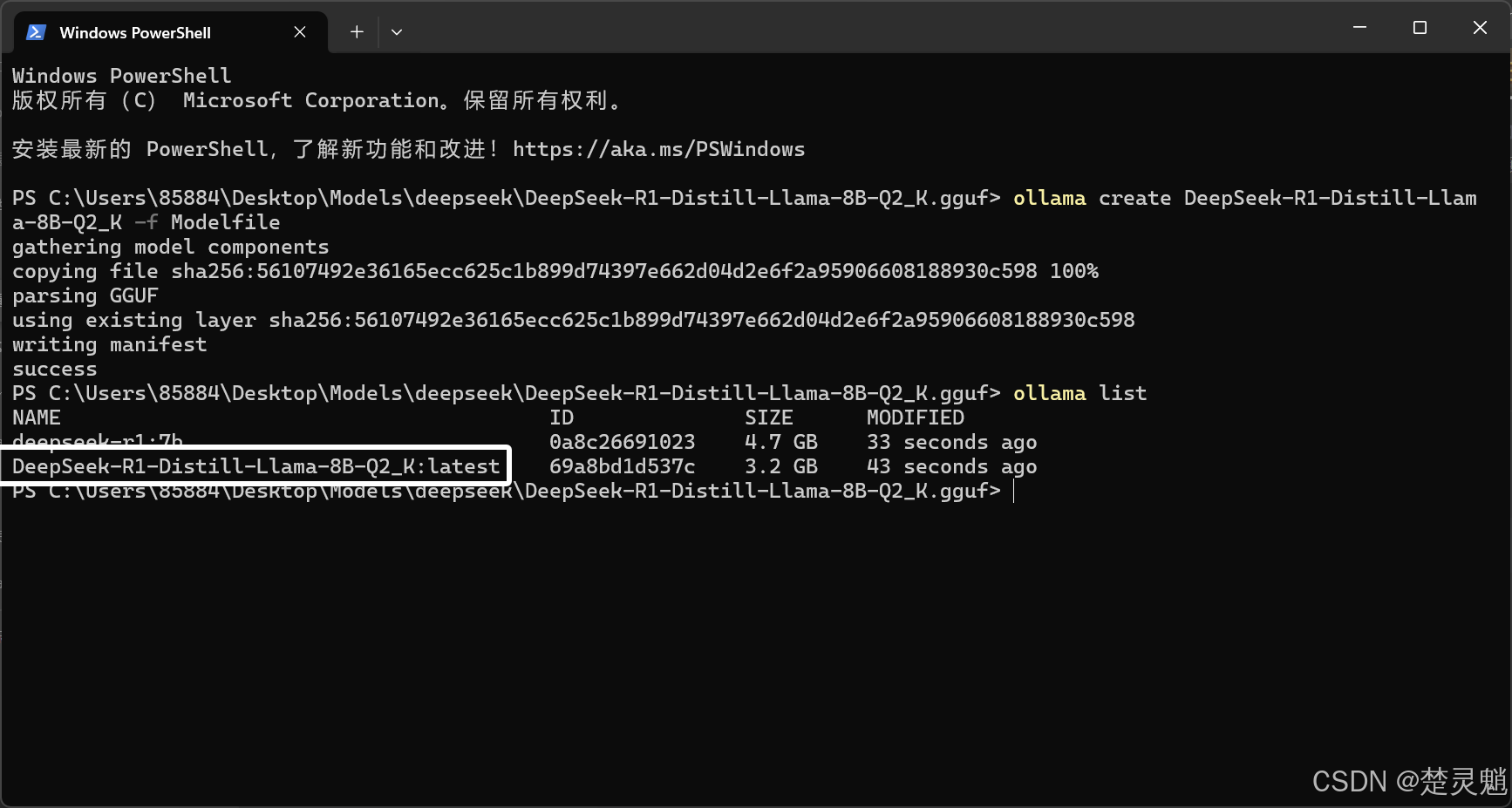
我们可以使用下面的命令来运行这个模型:
ollama run DeepSeek-R1-Distill-Llama-8B-Q2_K:latest注意,这里的“DeepSeek-R1-Distill-Llama-8B-Q2_K:latest”仍然是我的模型名字,大家需要将其替换为自己的。
模型运行以后,就可以开始对话了:
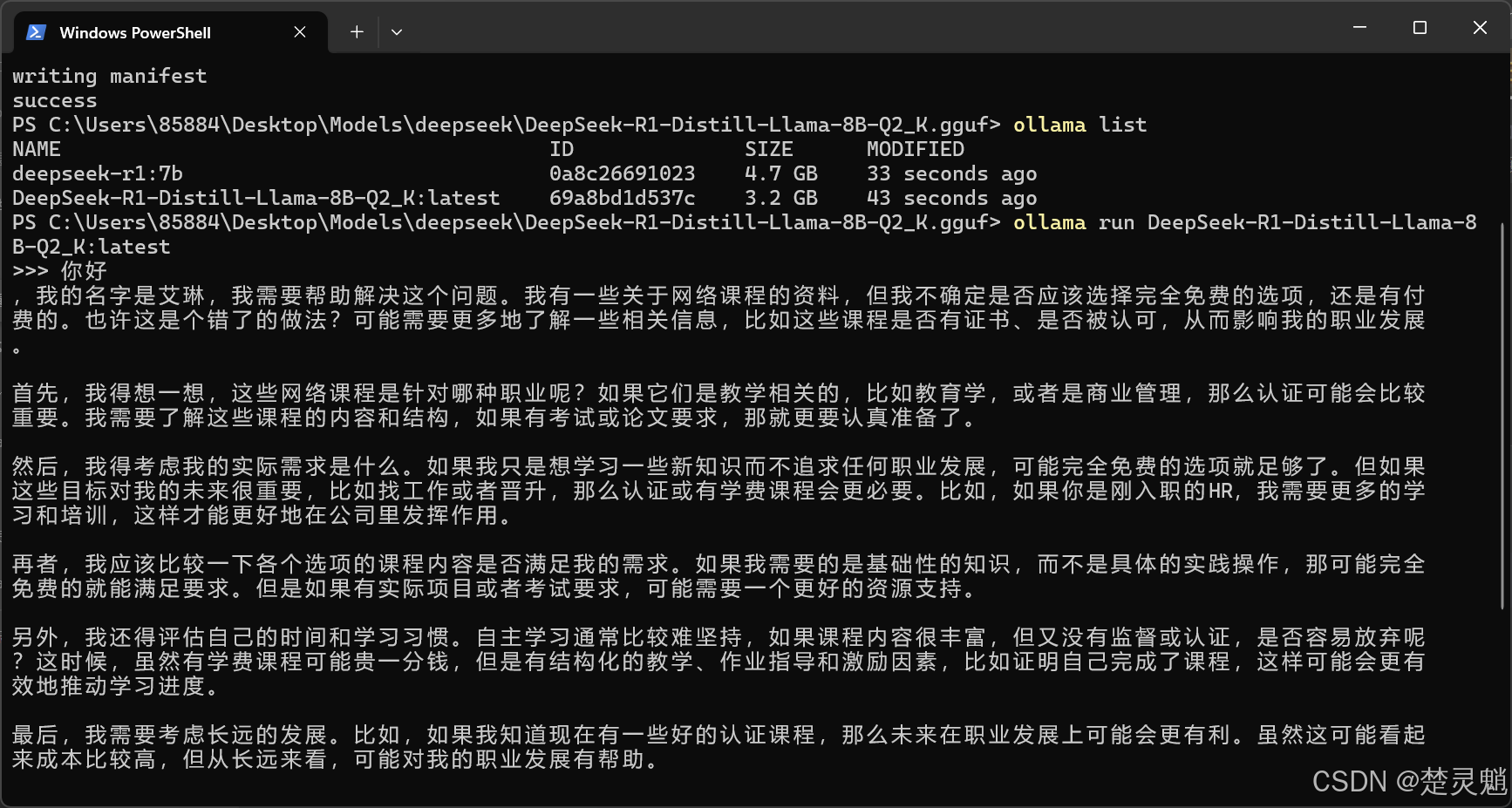
当然,模型胡言乱语也是常有的事,通过提高精度或者使用API时修改参数,可以相应缓解。
不止是DeepSeek,其它的GGUF格式的模型都可以使用上面的方法来让Ollama运行它,至于别的模型就让大家自己到HF Mirror中去探索吧!
至此,我们使用Ollama部署GGUF格式的模型就已经完成了。
五、模型API的调用
前面我们已经使用LM Studio和Ollama在本地部署了DeepSeek模型,那么总不能一直在应用或者终端中与模型对话吧,我们需要调用模型的API时,又要怎么做呢,下面就让我来为大家演示一下模型API的调用。这里我们使用python调用API,请确保你有一定的python基础。
1.LM Studio API的调用
这里我们还是先进入LM Studio中:
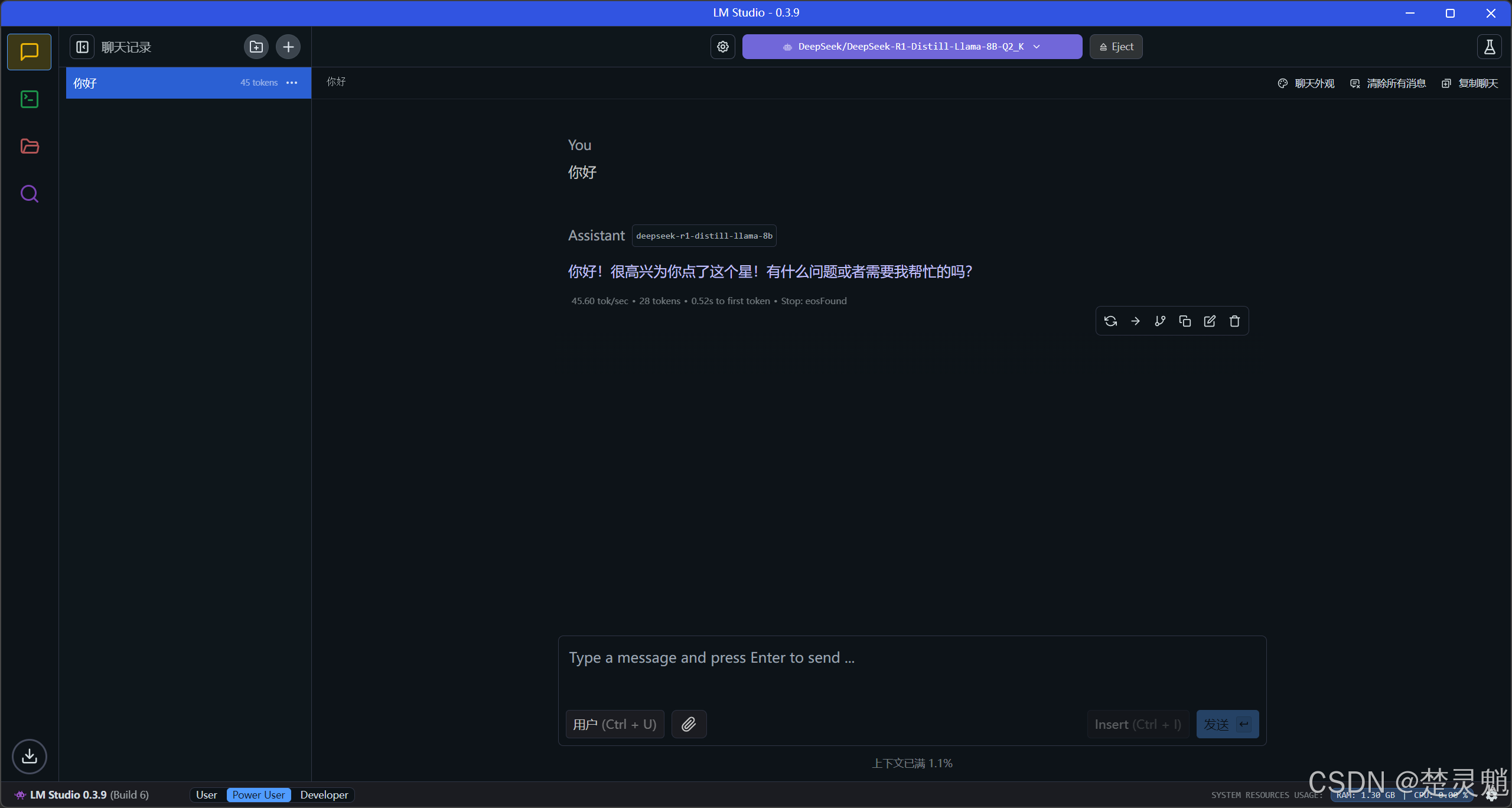
我们点击左边的开发者选项按钮:
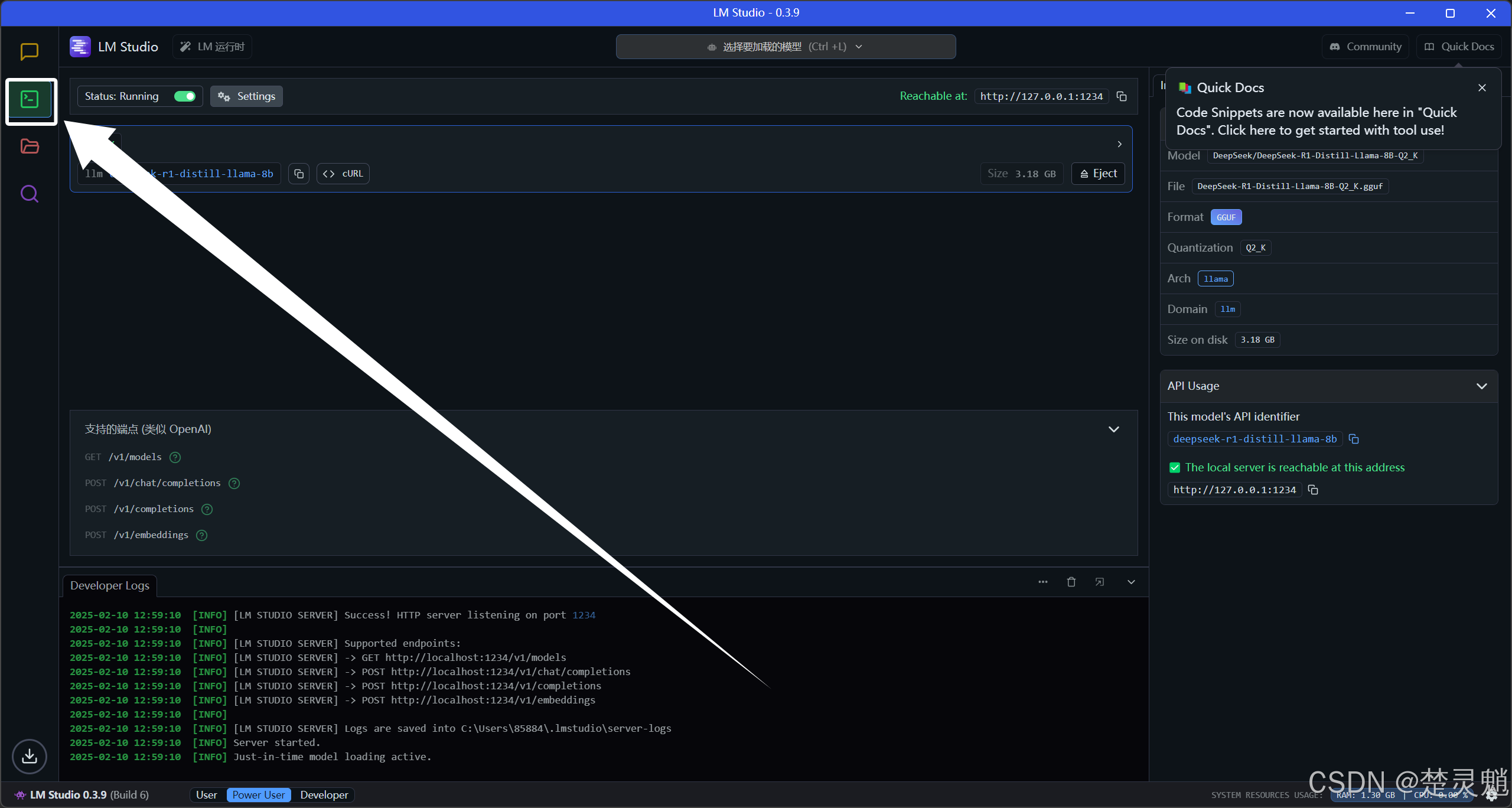
然后我们把如图所示的运行按钮打开:
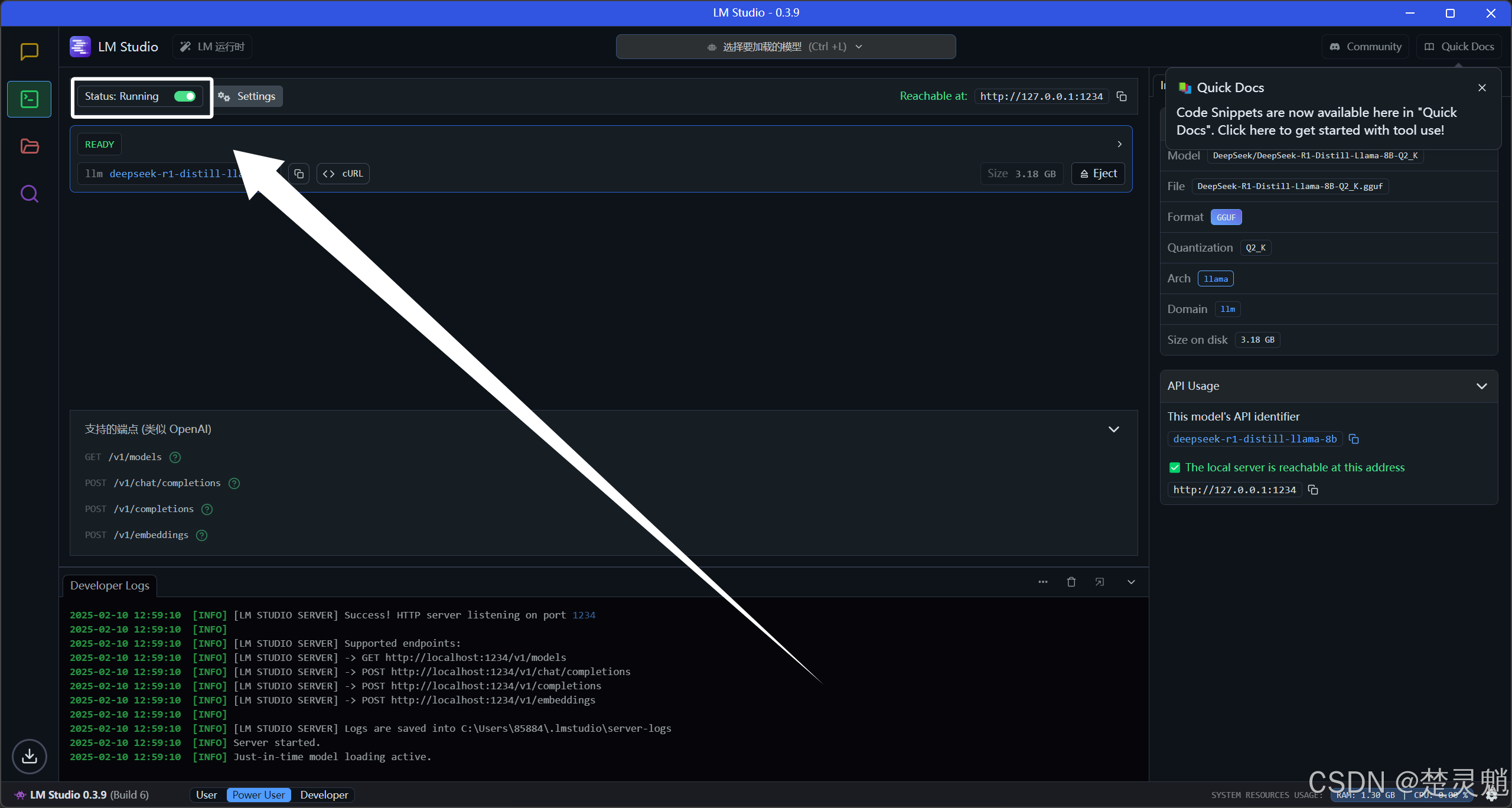
我们可以在这个页面看到调用的接口和端点:
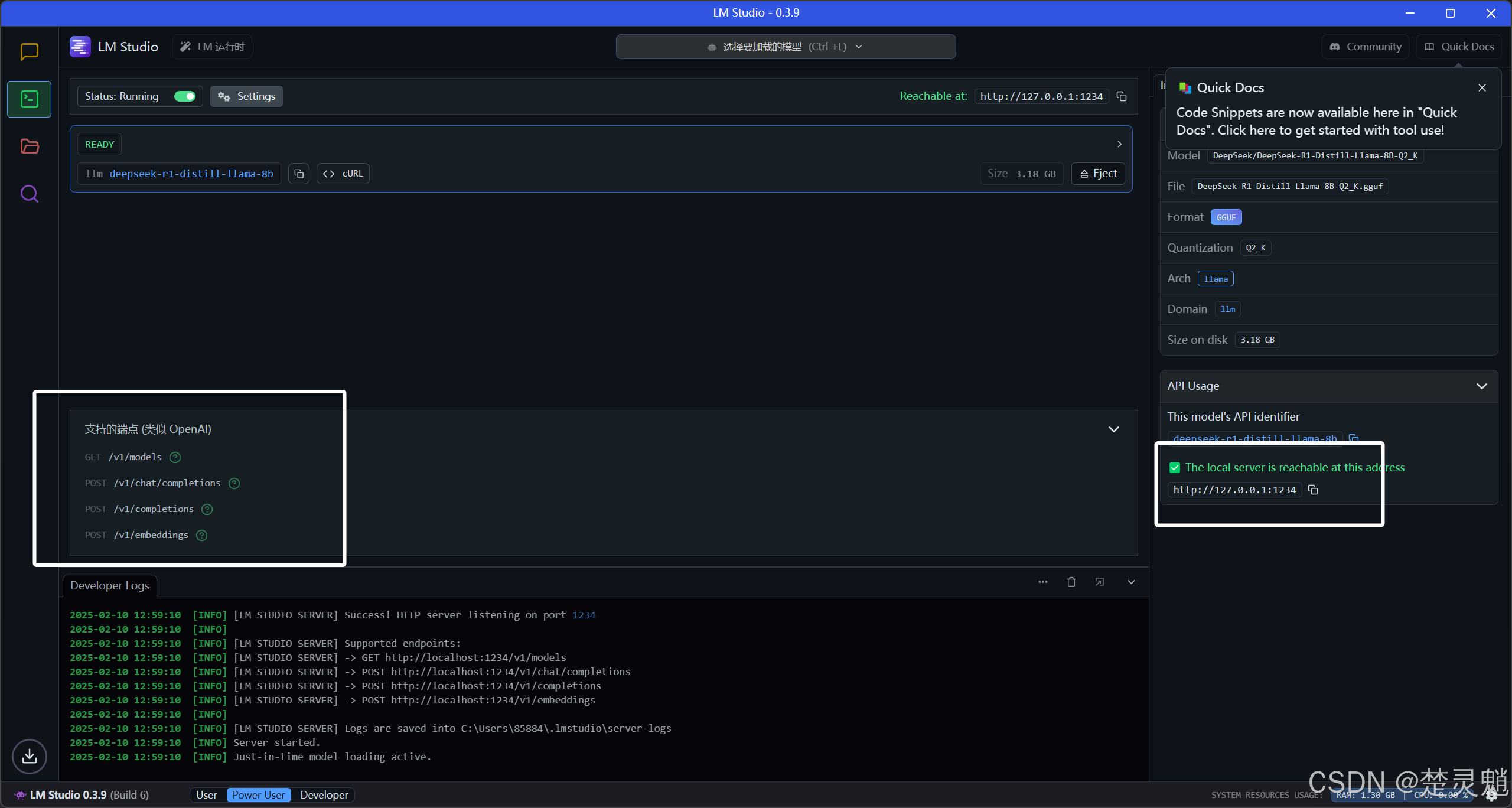
LM Studio是直接支持类Openai的调用方式的,这里大家先使用下面的命令安装openai的SDK:
pip install openai我这里使用虚拟环境,已经装好了相关的库:
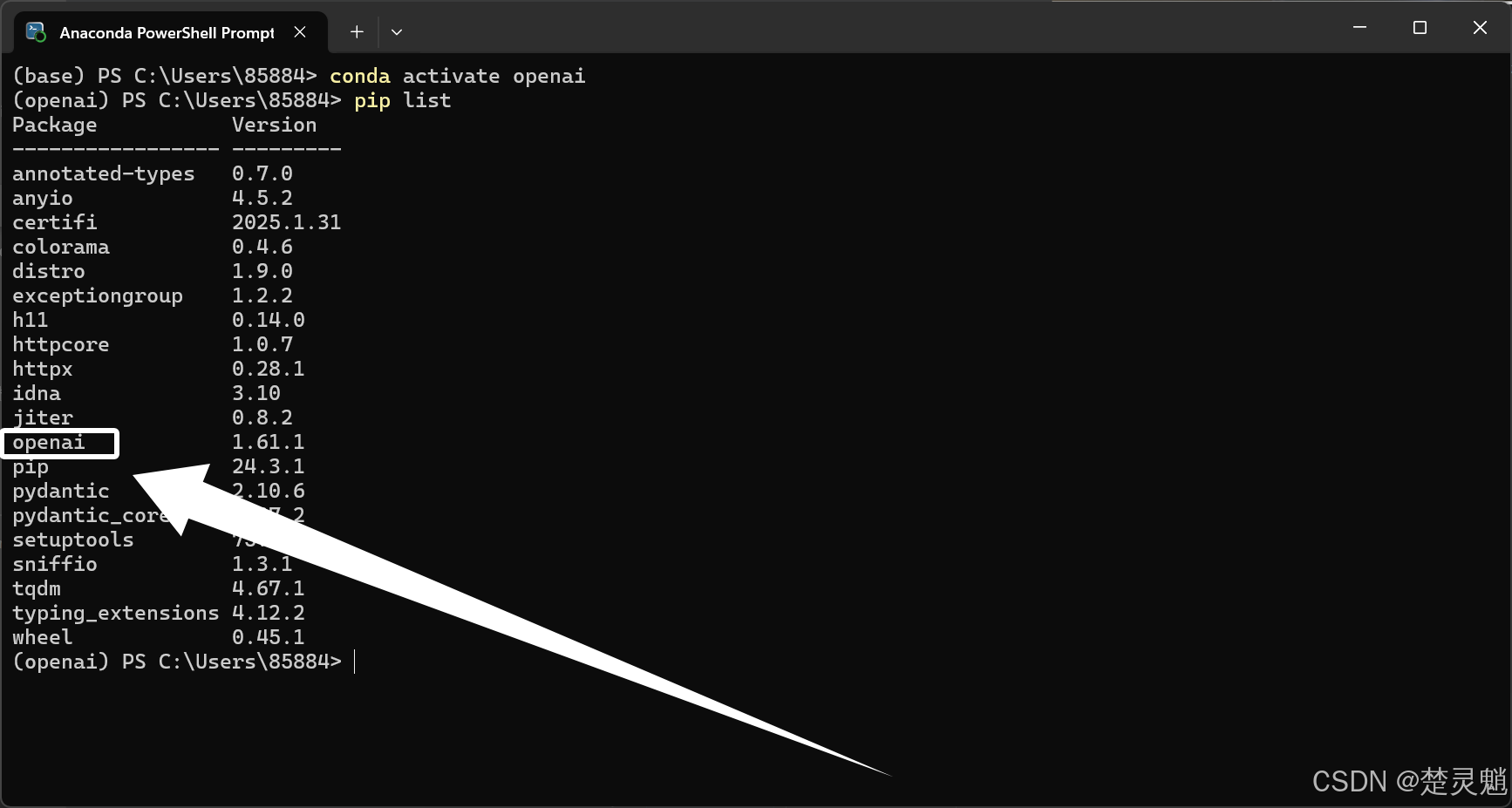
然后我们新建一个.py的文件,注意这里py文件的名字不要叫“openai.py”注意是不要,在这个py文件中输入下面的代码:
from openai import OpenAI
def GetOpenai():
# 初始化客户端
client = OpenAI(base_url="http://127.0.0.1:1234/v1", api_key="lm-studio")
# 调用API生成对话
completion = client.chat.completions.create(
model="deepseek-r1-distill-llama-8b", # 使用的模型
messages=[
#{"role": "system", "content": "你是一个专业的助手,回答问题时必须准确,且不能胡言乱语。"}, # 系统提示
{"role": "user", "content": "你好,你叫什么名字"} # 用户输入
],
temperature=0.7, # 控制输出的随机性,值越低输出越确定
top_p=0.9, # 控制输出的多样性,值越低输出越集中
max_tokens=512, # 控制生成的最大token数量
frequency_penalty=0.5, # 减少重复内容的生成
presence_penalty=0.5 # 鼓励模型引入新内容
)
# 打印生成的回复
print(completion.choices[0].message.content)
if __name__ == '__main__':
GetOpenai()这里的url和api_key都是固定了,需要注意的是“model”处,这里要写自己模型的名称。不然调用就会报错。LM Studio也支持同时启动多个模型的API,调用不同模型只需要改模型的名字即可。
运行这个py文件,就能看到模型的回复了:

至此,我们LM Studio的模型API调用就完成了。
2.Ollama API的调用
对于Ollama的API我们不用进行别的特殊操作,只要保证Ollama在运行就行,怎么看在没在运行呢?我们可以直接看任务栏嘛:
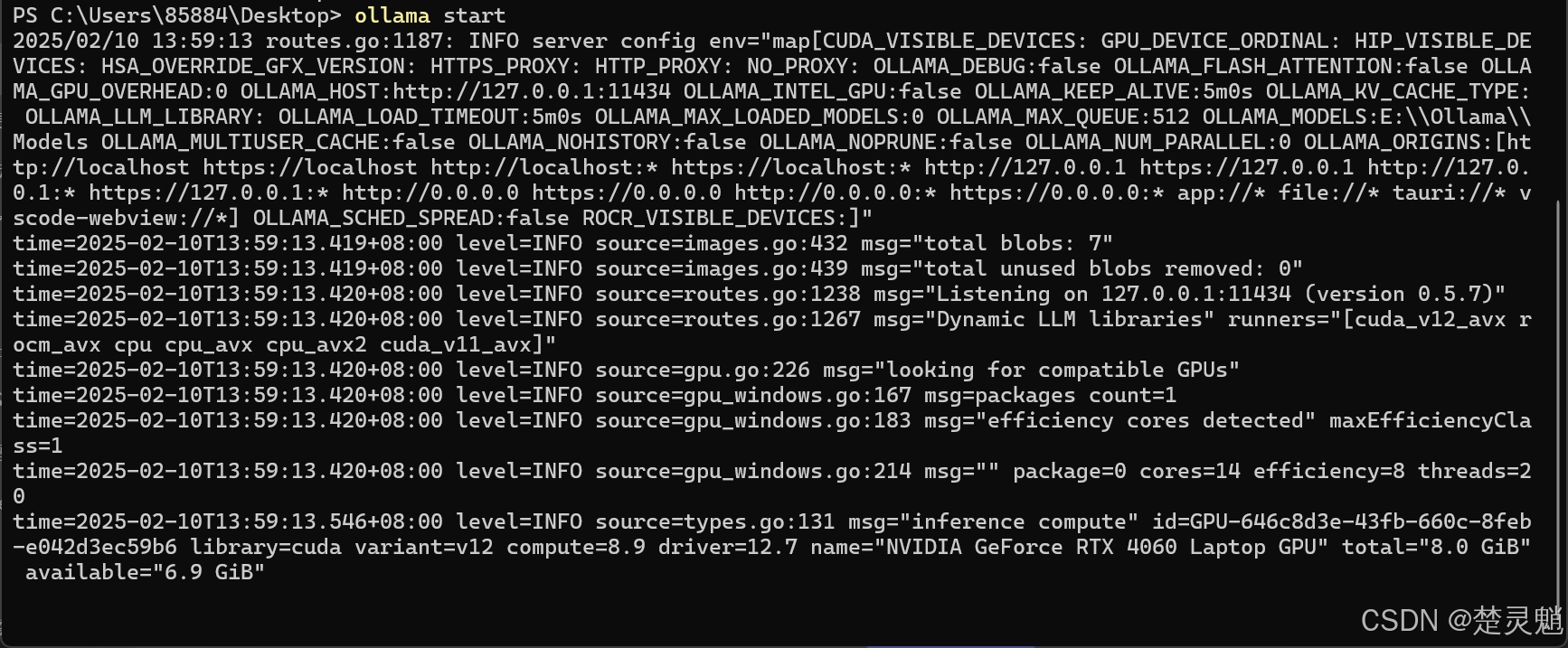
如果你的Ollama没有在运行,直接在终端中输入下面的命令就可以启动Ollama:
ollama start这样我们的ollama就启动了,这个窗口保持不动就行:
Ollama也支持类Openai的调用,这里我们直接延用上面LM Studio的代码,只需要修改些许部分:
from openai import OpenAI
def GetOpenai():
# 初始化客户端
client = OpenAI(base_url="http://127.0.0.1:11434/v1", api_key="lm-studio")
# 调用API生成对话
completion = client.chat.completions.create(
model="deepseek-r1:7b", # 使用的模型
messages=[
#{"role": "system", "content": "你是一个专业的助手,回答问题时必须准确,且不能胡言乱语。"}, # 系统提示
{"role": "user", "content": "你好,你叫什么名字"} # 用户输入
],
temperature=0.7, # 控制输出的随机性,值越低输出越确定
top_p=0.9, # 控制输出的多样性,值越低输出越集中
max_tokens=512, # 控制生成的最大token数量
frequency_penalty=0.5, # 减少重复内容的生成
presence_penalty=0.5 # 鼓励模型引入新内容
)
# 打印生成的回复
print(completion.choices[0].message.content)
if __name__ == '__main__':
GetOpenai()这里我们只修改了url将其修改为了Ollama的接口,还修改了模型,这里修改为了Ollama中已经有的模型名称。
我们运行py文件,可以看到API被正常调用:

并且ollama的运行框中也抛出了日志:
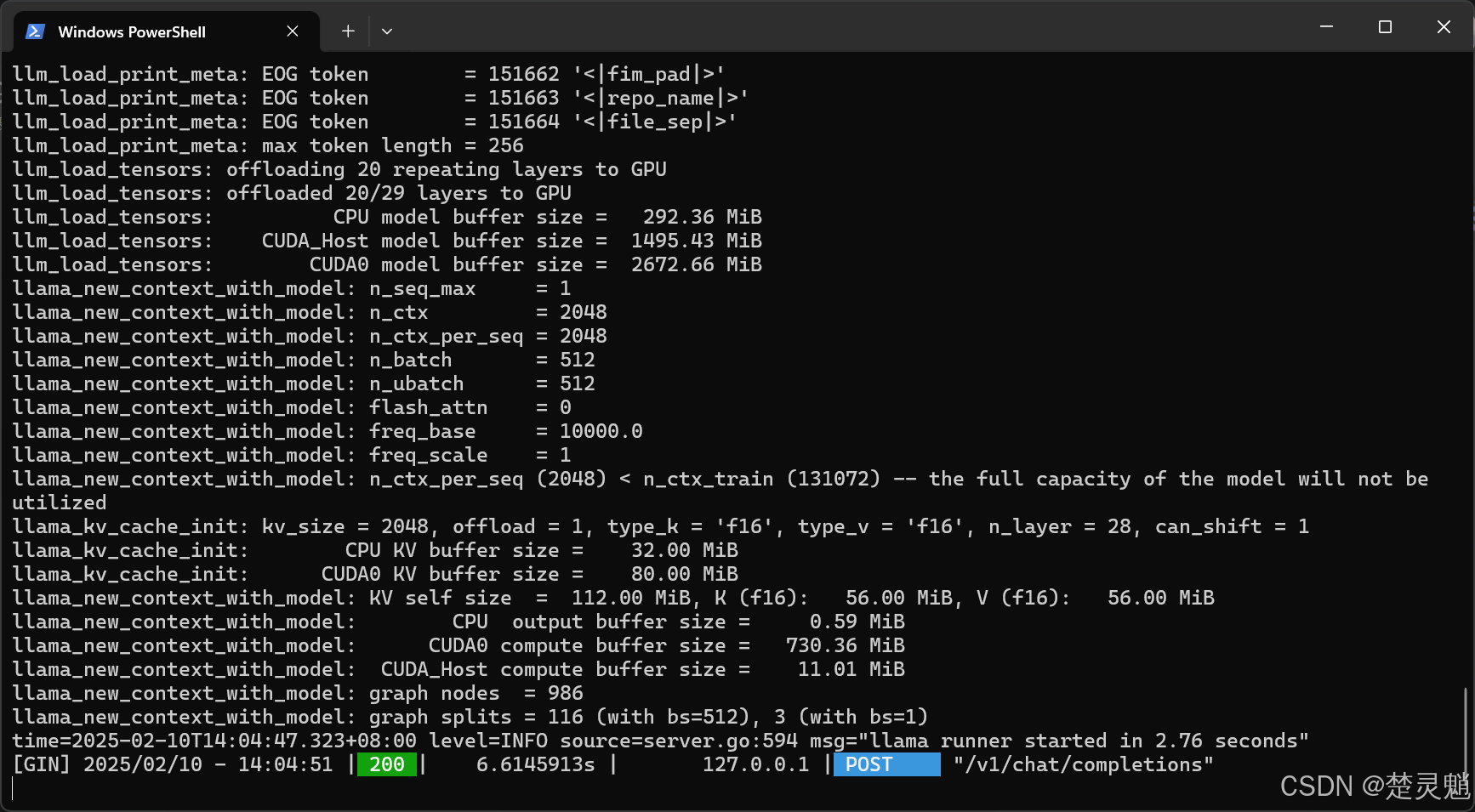
至此,我们调用Ollama的API就已经完成了。
六、结语
中国AI的崛起让我由衷的感到高兴,但也引发了我的一些担心,但当我部署完DeepSeek以后,就已经释怀了。尽管DeepSeek如此强大,但它依然是工具,服务于人类的工具,我也并不担心在短时间内我会被这样的工具取代,毕竟,在某种意义上,我已经懂得如何驾驭它了......

















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









