








作者|邴立东、程丽颖、付子豪、张琰等
单位|阿里巴巴达摩院、香港中文大学等
摘要
基于结构化数据生成文本(data-to-text)的任务旨在生成人类可读的文本来直观地描述给定的结构化数据。然而,目前主流任务设定所基于的数据集有较好的对齐 (well-aligned)关系,即输入(i.e. 结构化数据)和输出(i.e. 文本)具有相同或很接近的信息量,比如 WebNLG 当中的输入 triple set 和输出文本所描述的知识完全匹配。但是,这样的训练数据制作困难且成本很高,现有的数据集只限于少数几个特定的领域,基于此训练的模型在现实应用中存在较大的局限性。
因此,我们提出了基于部分对齐(partially-aligned)样本的文本生成任务。部分对齐数据的优势在于获取门槛低,可以用自动或半自动方式构造,因而更容易拓展到更多的领域。我们考虑了两个对偶的部分对齐场景,即输入数据多于文本描述和文本描述多于输入数据。
对于数据多于文本的情况,我们发布了 ENT-DESC 数据集 [1],并且针对数据中存在冗余信息的问题,我们提出了多图卷积神经网络 (Multi-Graph Convolutional Network)模型来抽取重要信息,生成更为凝练的文本描述。
对于文本多于数据的情况,我们发布了 WITA 数据集 [2],并且针对训练样本中文本的多余信息,提出了远程监督生成(Distant Supervision Generation)框架,以确保基于非严格对齐样本训练的模型,在应用中能够如实地生成给定数据的描述。
基础模型层面,本文将介绍我们提出的轻量、动态图卷积网络 (Lightweight, Dynamic Graph Convolutional Networks),简称 LDGCN [3],可以有效的融合图结构中来自不同阶节点的信息,进而学习更优的图表示,并提升下游文本生成的效果。
参考文献
[1] ENT-DESC: Entity Description Generation by Exploring Knowledge Graph. Liying Cheng, Dekun Wu, Lidong Bing, Yan Zhang, Zhanming Jie, Wei Lu, Luo Si. EMNLP, 2020.
[2] Partially-Aligned Data-to-Text Generation with Distant Supervision. Zihao Fu, Bei Shi, Wai Lam, Lidong Bing, Zhiyuan Liu. EMNLP, 2020.
[3] Lightweight, Dynamic Graph Convolutional Networks for AMR-to-Text Generation. Yan Zhang, Zhijiang Guo, Zhiyang Teng, Wei Lu, Shay B. Cohen, Zuozhu Liu, Lidong Bing. EMNLP, 2020.

非严格对齐的文本生成:输入数据多于文本描述

论文标题:
ENT-DESC: Entity Description Generation by Exploring Knowledge Graph
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.90.pdf
数据代码连接:
https://github.com/LiyingCheng95/EntityDescriptionGeneration
1.1 任务设置
本篇论文的基本出发点是提出一个实用的主题化文本生成任务设定,而这个设定下构造的数据集具有输入数据多于生成文本的特点。现有结构化数据到文本生成的任务要求输出的信息在输入的结构化数据中有很充分的体现,比如 WebNLG 数据集 [1] 等。
这样的任务设定和数据准备在实际应用中均有一定的局限性。而本篇论文所提出的主题化实体描述生成,是在给定一个主实体(main entity)的前提下,通过利用该实体的多个附属主题实体(topic-related entity),对生成的主实体描述进行一定的导向和限制,使其符合某一主题。

上图例子中,红色框内是输入的主实体(Bruno Mars)和多个附属主题实体(funk, rock, R&B 等),目标是生成符合这一特定主题的文本描述,如蓝色方框所示,来介绍 Bruno Mars 其人以及其音乐风格等。为了使生成的描述符合现实世界的知识,我们依据输入实体,有选择性地利用知识图谱中关于这些实体的知识,如绿色方框所示,辅助生成该实体的主题化描述。本任务相较于现有的生成任务更具有实用性和挑战性。
1.2 ENT-DESC数据集
基于这样的任务设定,本篇论文提出了一个新的数据集 ENT-DESC。此数据集采用了较为普遍和常规的维基百科数据集和 WikiData 知识图谱。
首先,我们用 Nayuki 的工具(https://www.nayuki.io/page/computing-wikipedias-internal-pageranks)去给超过 990 万维基百科页面计算 PageRank。然后我们根据 PageRank 排名,选用了来自于四种主要领域的 11 万主实体名词,以及维基百科第一段文本中带有超链接的名词作为附属主题实体。
我们即用每个维基百科页面的第一段文本作为输出。另外我们利用已有知识图谱 Wikidata,选取了主实体的相邻实体,以及主实体和附属主题实体间的 1 跳和 2 跳路径。据我们所知,ENT-DESC 是现有知识图谱生成文本的类似数据集中规模最大的。其与部分现有数据集的比较如下图所示。

此数据集的一大特性为输入中包含输出内容以外的信息,因此要求模型可以有效选取输入中更为有用的信息去做生成。有关 ENT-DESC 数据集以及其更详细的准备和处理步骤可参阅:
https://github.com/LiyingCheng95/EntityDescriptionGeneration/tree/master/sockeye/data/ENT-DESC%20dataset
1.3 MGCN模型
在模型层面,现有序列到序列的文本生成模型不能够很好地利用图的结构与信息,而图到序列模型 [2] 将图中实体间的关系变为实体的参数,此类模型遇到信息丢失和参数过多的问题。有论文提出了 Levi 图转换方法 [3],即将原始图中的关系转化成点,以用于解决前面提到的问题。但是 Levi 图转化仍然有它自己的缺陷。
在 Levi 图中,我们不能很好的区分哪些点是原始图中的实体或关系,并且实体间的直接联系在 Levi 图中被忽略。另外,不同类型的边被融合在 Levi 图中一起学习,不能很好地区分不同类型边的不同重要性。
为了解决现有模型在本篇论文提出的知识图谱驱动实体文本描述生成的任务上的缺陷,本篇论文采用了编码-解码架构(encoder-decoder),提出了一种基于多图卷积神经网络(Multi-Graph Convolutional Network)的文本生成模型。
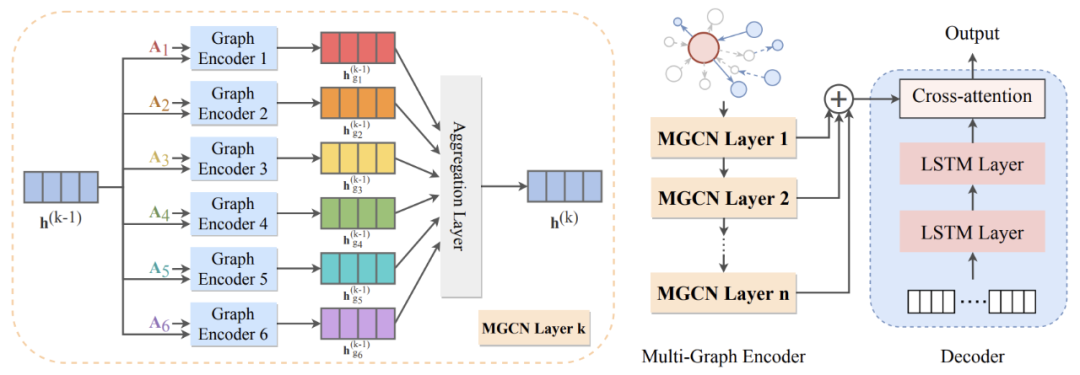
在多图编码器(Multi-Graph Encoder)中,不同于传统的图编码器,我们叠加了多层多图卷积神经网络。每层多图卷积神经网络的结构如左图所示。我们先将输入图嵌入转化为 6 个不同图的邻接矩阵,分别放入 6 个图编码器,以此得到 6 个包含不同类型信息的图嵌入。继而将这些图嵌入进行聚合运算,得到下一层的图嵌入。
解码器(decoder)是一个基于标准的长短时记忆网络(LSTM)的文本生成模型。本篇论文中的解码器对于在编码过程中学习到的隐藏子图的特征与结构信息进行解码,并生成相应的描述文本。此模型结构有效避免了信息丢失和参数过多的问题,有选择性地捕捉了多图中的重要信息并进行了有效聚合。
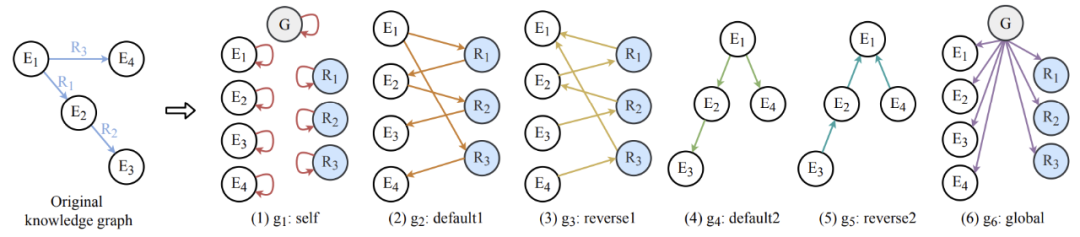
上图展示了多图转化的过程。类似于 Levi 图转化的过程,我们将原始图中的边转化为点。
(1)在 g1:self 图中,我们给所有的点加一条自循环的边。(2)在 g2:default1 图中,我们把点和边按原始图中的默认顺序进行连接。(3)在 g3:reverse1 中,我们将 g2 中的边进行反向连接。(4)在 g4:default2 中,我们将点和点之间按默认顺序连接。(5)类似地,在 g5:reverse2 中,我们将点和点之间的边反向相连。(6)最后,我们额外加了全局点(gnode),并把它与图中其他所有点按图中方向相连。
它的创新之处在于将原始图中的点到点、点到边的正向与反向信息明确地表示在不同图中,这样简单明了的转化过程对多图卷积神经网络中的学习起到了巨大的帮助作用。
1.4 主要实验结果
我们在本篇论文所提出的 ENT-DESC 数据集和 WebNLG 数据集上均实验了提出的模型。下图是我们在 ENT-DESC 数据集上的主要实验结果。
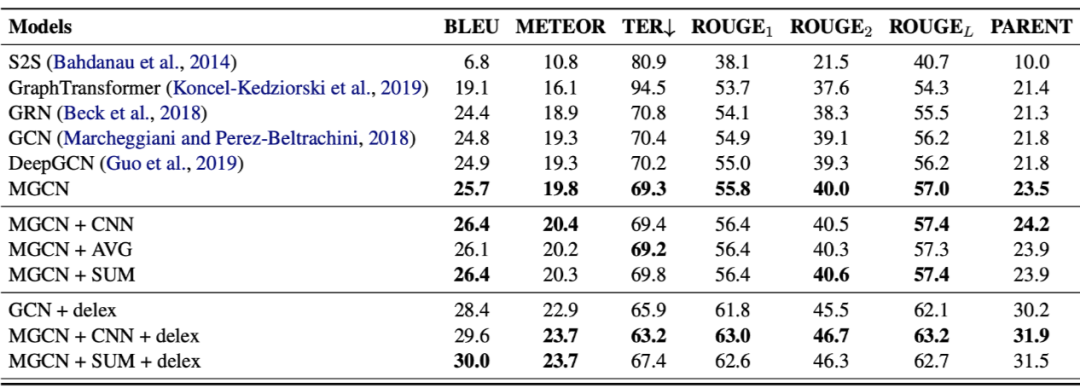
我们与序列到序列生成模型及多种图到序列生成模型在多种评测标准上均做了比较。从表格和图中,我们可以观察到,现有图到序列模型可以达到 BLEU 值 24.8,现有深层图到序列模型 [4] 的 BLEU 值为 24.9。而我们的多图神经网络结构在 6 层时可以达到 25.7 的 BLEU 值,加上聚合运算后可以达到 26.4。
由此可见,我们提出的多图卷机神经网络的模型有效地捕捉了知识图谱中的重要信息并进行了有效聚合。我们进一步对数据进行了归一化处理(delexicalization),实验结果均有更进一步的提升。
另外,此模型在 ENT-DESC 数据集以及现有数据集上(如:WebNLG)相对于多个基准模型在多个评测标准上均显示明显提升,同时其可被扩展应用于其他图相关的自然语言处理研究中。

上图展示了知识驱动文本生成的例子。红色高亮文本是主要实体,蓝色高亮文本是附属主题实体。与维基百科的参考文本相比,我们提出的多图卷积神经网络与聚合运算能够准确捕捉到主要实体以及大部分附属主题实体。而传统的图到序列生成模型未能识别出主要实体。这进一步体现了传统图到序列模型会造成信息丢失的情况,同时也体现了多图卷积神经网络对于提取重要信息的有效性。
参考文献
[1] Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The webnlg challenge: Generating text from rdf data. In Proceedings of INLG.
[2] Diego Marcheggiani and Ivan Titov. 2017. Encoding sentences with graph convolutional networks for semantic role labeling. In Proceedings of EMNLP.
[3] Daniel Beck, Gholamreza Haffari, and Trevor Cohn. 2018. Graph-to-sequence learning using gated graph neural networks. In Proceedings of ACL.
[4] Zhijiang Guo, Yan Zhang, Zhiyang Teng, and Wei Lu. 2019. Densely connected graph convolutional networks for graph-to-sequence learning. TACL.

非严格对齐的文本生成:文本描述多于输入数据

论文标题:
Partially-Aligned Data-to-Text Generation with Distant Supervision
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.738.pdf
数据代码链接:
https://github.com/fuzihaofzh/distant_supervision_nlg
2.1 简介
在基于结构化数据生成文本(data-to-text)[1,2] 任务中,现有的模型要求训练的数据和文本是严格对齐的(well-aligned),导致可以用于训练的数据非常稀少且标注代价高昂,因此,现有的经典生成任务只限于少数几个特定的领域。
本文旨在探索使用部分对齐(partially-aligned)的数据来解决数据稀缺的问题。部分对齐的数据可以自动爬取、标注,从而能将文本生成任务推广到更多的数据稀缺的领域。但是,直接使用此类数据来训练现有的模型会导致过度生成的问题(over-generation),即在生成的句子中添加与输入无关的内容。
为了使模型能够利用这样的数据集来训练,我们将传统的生成任务扩展为“部分对齐的数据到文本生成的任务”(partially-aligned data-to-text generation task),因为它利用自动标注的部分对齐数据进行训练,因此可以很好地被应用到数据稀缺领域。
为了解决这一任务,我们提出了一种新的远程监督(distant supervision)训练框架,通过估计输入数据对每个目标词的支持度,来自动调节相应的损失权重,从而控制过度生成的问题。我们通过从 Wikipedia 中抽取句子并自动提取相应的知识图谱三元组的方式制作了部分对齐的 WITA 数据集。
实验结果表明,相较于以往的模型,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









