







 本文从Dropout的角度分析了BERT的MLM任务预训练与微调的不一致性,并提出修正策略。同时探讨了何凯明的MAE模型,发现其在预训练和微调上具有一致性,暗示了一种防止过拟合的新方法。实验表明,修正MLM的Embedding并未显著提升性能,而DropToken作为一种正则化手段在防止过拟合方面表现参差不齐。
本文从Dropout的角度分析了BERT的MLM任务预训练与微调的不一致性,并提出修正策略。同时探讨了何凯明的MAE模型,发现其在预训练和微调上具有一致性,暗示了一种防止过拟合的新方法。实验表明,修正MLM的Embedding并未显著提升性能,而DropToken作为一种正则化手段在防止过拟合方面表现参差不齐。

©PaperWeekly 原创 · 作者 |苏剑林
单位 |追一科技
研究方向 |NLP、神经网络
大家都知道,BERT 的 MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了 [MASK] 而下游任务微调时没有 [MASK],是经常被吐槽的问题,很多工作都认为这是影响 BERT 微调性能的重要原因,并针对性地提出了很多改进,如 XL-NET [1]、ELECTRA [2]、MacBERT [3] 等。
本文我们将从 Dropout 的角度来分析 MLM 的这种不一致性,并且提出一种简单的操作来修正这种不一致性。同样的分析还可以用于何凯明最近提出的比较热门的 MAE(Masked Autoencoder)模型,结果是 MAE 相比 MLM 确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。

Dropout
首先,我们重温一下 Dropout。从数学上来看,Dropout 是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。

伯努利分布
伯努利分布(Bernoulli Distribution)算得上是最简单的概率分布了,它是一个二元分布,取值空间是 ,其中 取 1 的概率为 ,取 0 的概率为 ,记为
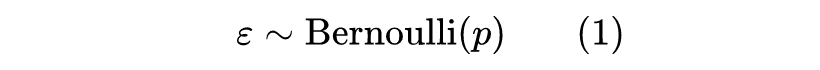
伯努利分布的一个有趣的性质是它的任意阶矩都为 ,即

所以我们知道它的均值为 ,以及方差为
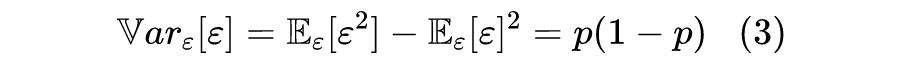

训练和预测
Dropout 在训练阶段,将会以 将某些值置零,而其余值则除以 ,所以 Dropout 事实上是引入了随机变量 ,使得模型从 变成 。其中 可以有多个分量,对应多个独立的伯努利分布,但大多数情况下其结果跟 是标量是没有本质区别,所以我们只需要针对 是标量时进行推导。
在《又是Dropout两次!这次它做到了有监督任务的SOTA》中我们证明过,如果损失函数是 MSE,那么训练完成后的最佳预测模型应该是
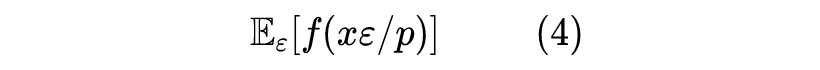
这意味着我们应该要不关闭 Dropout 地预测多次,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









