







©作者 | 香侬科技
来源 | 香侬科技
近日,深度学习国际顶级会议ICLR 2022向作者公布了论文录用结果。香侬科技3篇论文被大会收录,研究内容覆盖通用自然语义理解、NLP神经网络模型安全性、自动机器学习(autoML)。其中与浙江大学、新加坡南洋理工大学等单位合作提出的基于图神经网络的语义理解模型GNN-LM获得了单项评审满分(10分),以下为该文章具体介绍:

论文标题:
GNN-LM: Language Modeling based on Global Contexts via GNN
作者:
Yuxian Meng, Shi Zong, Xiaoya Li, Xiaofei Sun, Tianwei Zhang, Fei Wu, Jiwei Li
论文链接:
https://arxiv.org/abs/2110.08743
接收会议:
ICLR 2022
代码链接:
https://github.com/ShannonAI/GNN-LM
概述
如今大多数NLP模型可以认为是遵循闭卷考试模型:在标注数据集上,模型训练N个epoch, 可以比作学生看了N遍书,然后把他们“背”下来。在测试的时候,学生需要把书合上,不允许再去参考训练数据。 这种闭卷考试策略有两个局限性:一是基于记忆的很难记住训练集中长尾的例子,二是记忆整个训练数据所需的存储空间过大。
本文提出了一个全新的语义理解模式,将闭卷考试转化为开卷考试的语义理解模式:在测试的时候,模型允许参考训练数据。这样就将之前的“背”,转变成了“抄”,模型可以直接使用训练集中相关的例子来协助决策,这样问题的难度就大大降低了。以语言模型来举例,例如,给定前文“J.K.罗琳最知名的作品是”来预测后面的词“哈利波特”,如果语言模型可以引用训练集中相关的上下文“J.K.罗琳撰写了哈利波特系列书籍”,那么它就会更容易将下一个token预测为“哈利”,就像是有参考书的开卷考试比闭卷考试要更简单一样。
基于这一认识,本文提出了基于图神经网络的语义理解模型的GNN-LM,它将传统的NLP的闭卷模式,转变为开卷模式:在推理过程中允许参考训练数据。模型首先以输入的样例为query,首先在训练数据中通过K近邻(KNN)寻找相似的样例为邻居。找到了相似的邻居之后,我们需要考虑不同的邻居不同的影响,有的影响更大,有的影响更小。为了自动学习这些不同的影响,我们通过图神经网络GNN建立输入样例与邻居的关系。换言之,输入样例的表征基于输入样例与邻居通过GNN得到。如下图所示,我们想预测 “The movie is”后面即将出现的词,我们用“The movie is”作为query, 找到数据中相似的邻居,其中包括“This movie is great”, “Those movies are bad” 以及 “The movie is what I like”。我们将这四句话建立起一个图结构:“The movie is” 中的 “movie” 与其他近邻中的 “movie”建立边,“is” 与其他近邻中的 “is”建立边。然后通过GNN得到表征。参考这些相似的例子,得到预测结果。
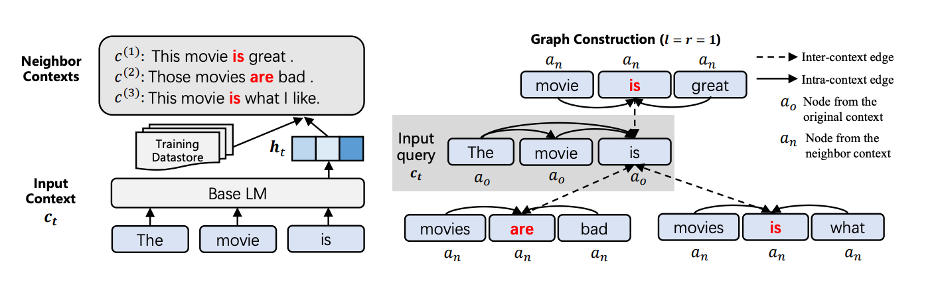
实验表明,该方法提出的GNN-LM框架使基础LM有了显著的性能提升,在三个广泛使用的语言模型数据集性能达到SOTA结果。
GNN-LM
首先使用基础LM对输入的上文 进行编码,得到其表示 ,然后使用自注意力增强图神经网络在检索到的上下文和输入的上文之间进行消息传递,从而更新上文的表示,再结合LM计算得到的概率 和检索到的上下文提供的额外概率,来估计 。
构建有向异质图
GNN-LM框架的第一步是通过计算余弦相似度,检索 个和输入上文的表示 最相近的上下文作为邻居 ,使用这些邻居上下文的前 个token构建为有向异质图 ,其中节点是token,分为 两种, 是输入 中的token,而 来自检索到的相似上下文。边同样也分为两种: , 是连接同一条上下文内的token,而 连接不同的上下文的token,也就是 和 之间的边。将节点对应的token 向上下文两侧进行扩充得到 ,使用 作为节点初始表示。
使用GNN传递信息
使用自注意力增强的图神经网络(GNNs)根据构造的图来聚合和过滤token信息:
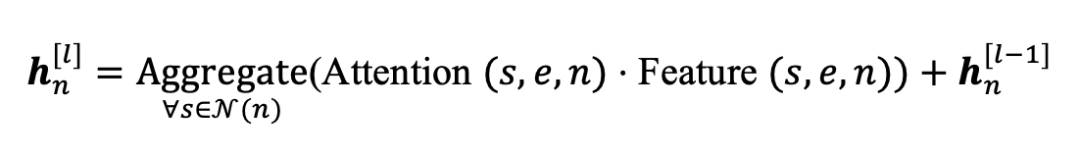
其中 代表目标节点 对源节点 在关系 下的重要程度, 是邻居 对节点 将要传递的消息。
·Attention
像Transformer一样,对于每条边 ,将目标节点 的表示映射到query向量 ,源节点 的表示映射到key向量 ,然后使用缩放点积计算注意力权重,并在所有相同类型的边上进行归一化:
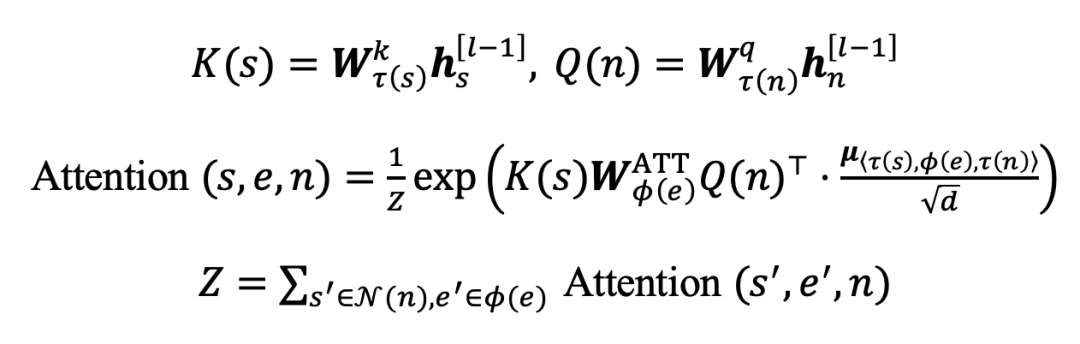
·Feature
Single-head的特征定义为:
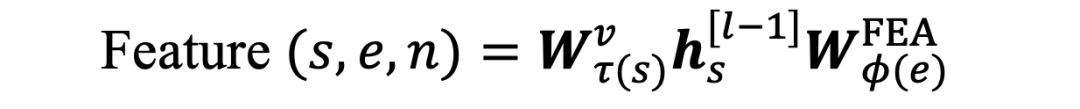
·Aggregate
使用注意力权重对特征进行加权聚合,并映射到 维空间:
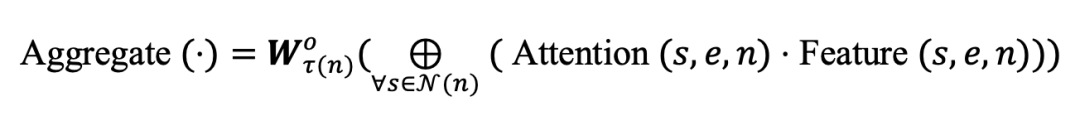
结合基于kNN的预测概率
结合kNN-LM()提出的概率线性插值方法增强GNN-LM的性能,对输入上下文 ,使用其k近邻 的概率对LM计算出的概率进行直接扩充:
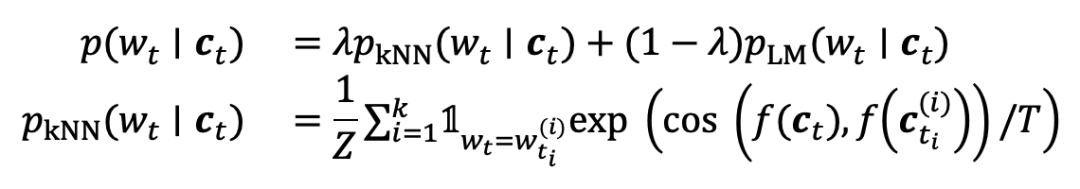
这一部分更详细的介绍可以参考账号之前的文章:
https://zhuanlan.zhihu.com/p/90890672
实验
我们在三个广泛使用的单词级、字级和字符级语言模型数据集上进行了实验:WikiText-103、One Billion Word和Enwik8。下图为主要实验结果,我们有如下观察:
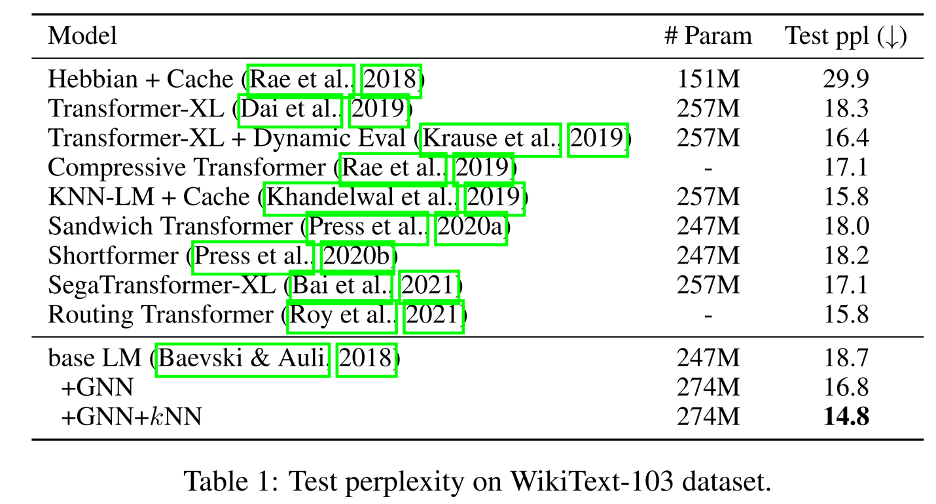
在WikiText-103数据集上,GNN-LM将基础LM的困惑度从18.7降低到16.8,这证明了GNN-LM体系结构的有效性,并且GNN和kNN的结合进一步将性能提升到14.8。
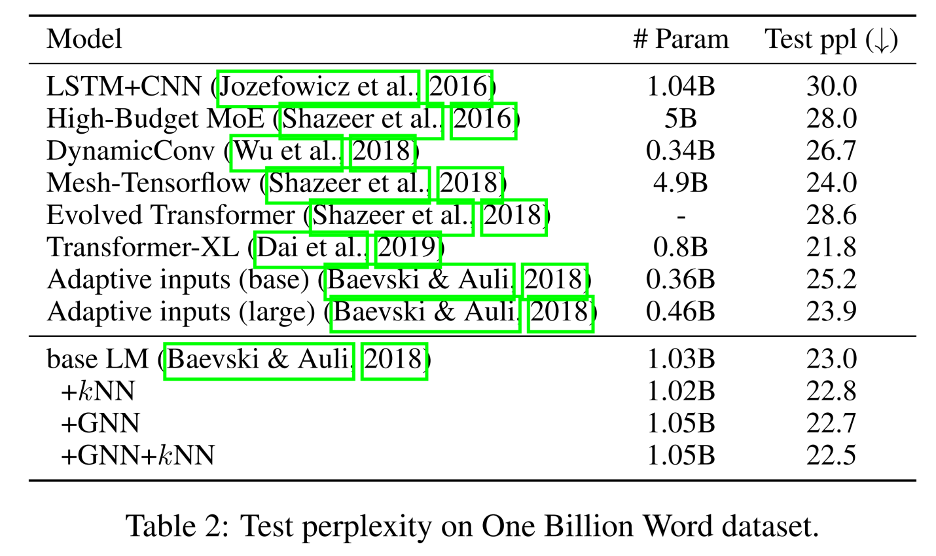
在One Billion Word上,GNN-LM仅增加了27M参数就帮助基础 LM减少了0.5的困惑度。作为对比,Baevski&Auli(2018)使用了560M额外参数,将困惑从23.9减少到23.0。
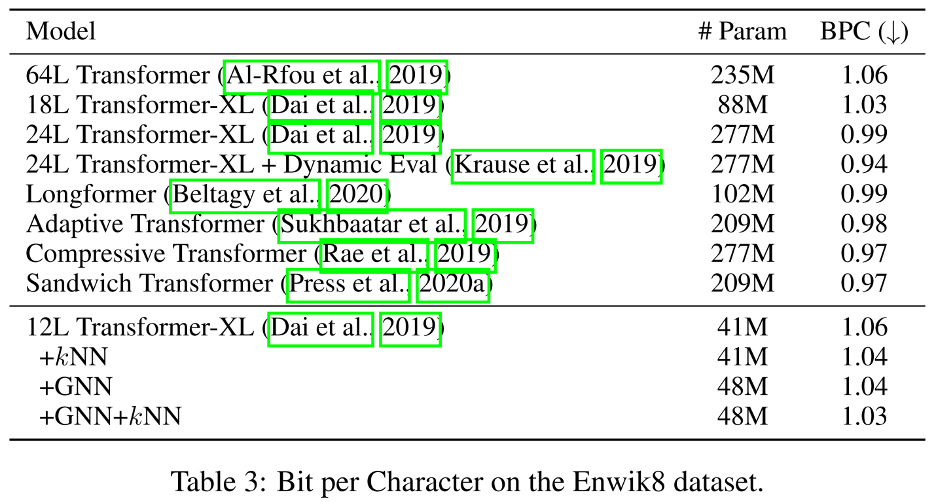
在Enwik8上,GNN-NN-LM比基础LM快0.03BPC,且仅使用48M参数即可实现1.03 BPC,与使用88M参数的18L Transformer XL相当。
复杂度分析
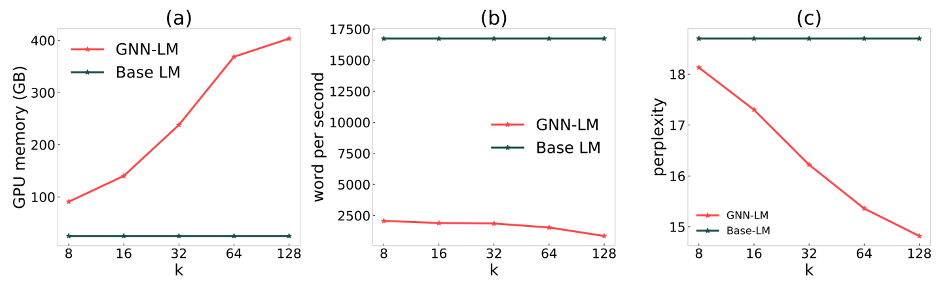
由于需要为反向传播维护每个节点的隐藏表示,训练GNN需要的内存大约是普通LM的两倍。我们提出了两种策略来缓解空间问题:首先在较小邻居数量的 上训练,再在 上微调;对于依赖关系较长的数据集(如WikiText-103),将上下文截取为较小的长度(128)。图(b)显示了WikiText-103中基础LM和GNN-LM在速度上的比较。我们观察到,GNN-LM的速度大约是基础LM的8到20倍。
消融实验
由上图(c)可见,每个token的邻居数量显著影响可以从训练集中检索多少信息。当k从8增加到128时,测试困惑度单调降低。
有向异质图的构造和概率计算都依赖于kNN的检索。我们使用召回度量来评估kNN检索的质量。当被选为邻居的上下文的下一个token与要预测的token相同时,视为召回。按照邻居召回率分为5堆,可以看到,当kNN检索的质量比较高时,GNN- LM比基础LM效果提升更明显。

示例研究

表中的示例显示了输入和相应提取的三个邻居上下文。这两个例子表明,提取的上下文在语义上与输入有很强的联系,因此利用邻居信息将有利于模型预测。
小结
本文提出了GNN-LM,将图神经网络与语言模型相结合,通过允许在整个训练语料库中引用相似的上下文,扩展了传统的语言模型。使用k近邻检索与输入的表示最相似的邻居,我们为每个输入构建了一个有向异构图,其中节点是来自输入上下文或检索到的邻居上下文的token,边表示token之间的连接。然后利用图神经网络从检索到的上下文中聚合信息,以解码下一个token。实验结果表明,GNN-LM在标准数据集中优于强基线,并且通过与kNN-LM结合,能够在WikiText-103上取得最优效果。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









