








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
不知道大家留意到一个细节没有,就是当前 NLP 主流的预训练模式都是在一个固定长度(比如 512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了 Base 版的 GAU 实验后才发现 GAU 的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......

模型回顾
在FLASH:可能是近来最有意思的高效Transformer设计中,我们介绍了“门控注意力单元 GAU”,它是一种融合了 GLU 和 Attention 的新设计。
除了效果,GAU 在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要 Softmax 归一化,可以换成简单的 除以序列长度:
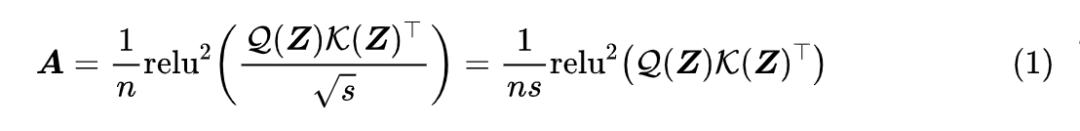
这个形式导致了一个有意思的问题:如果我们预训练的时候尽量将样本整理成同一长度(比如 512),那么在预训练阶段 n 几乎一直就是 512,也就是说 n 相当于一个常数,如果我们将它用于其他长度(比如 64、128)微调,那么这个 n 究竟要自动改为样本长度,还是保持为 512 呢?
直觉应该是等于样本长度更加自适应一些,但答案很反直觉:n 固定为 512 的微调效果比 n 取样本长度的效果要明显好!这就引人深思了......
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









