








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
位置编码是 Transformer 中很重要的一环,在《让研究人员绞尽脑汁的 Transformer 位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将 Transformer 的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多 NLP/CV 的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在 Softmax 之前的 Attention 矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得 Transformer 无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。

简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射
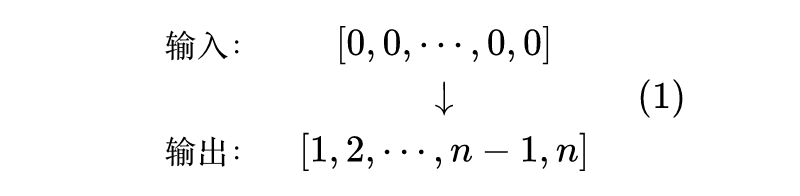
也就是说,输入 个 0,能有序地输出位置编号 。这个探针实验的思想很简单,即模型如果有能力做到这一点,说明识别位置是模型自身具备的能力,跟外部输入无关,这正是我们想要的。不难发现,绝对位置由于是直接施加在输入上的,所以它很容易能够完成探针测试。

无法胜任
然而,当笔者带着这个简单的探针实验去思考带有相对位置编码的 Transformer 模型时,却发现它们几乎都不能完成上述任务。
具体来说,除了《Self-Attention with Relative Position Representations》[1] 所提出的设计外,其余所有相对位置编码(包括笔者所提的 RoPE)都只修改了 Softmax 前的 Attention 矩阵,那么带有相对位置信息的 Attention 矩阵依然是一个概率矩阵(即每一行求和等于 1)。
另一方面,对于 Transformer
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









