







©作者 | 孙秋实
学校 | 华东师范大学
研究方向 | 自然语言处理
自从 2020 年 CodeBERT 开了代码表征预训练模型(本文称之为 CodePTM)这个新坑后,在短短两年的时间内出现了若干个程序设计语言(Programming Language,称之为 PL,与 Natural Language,也就是 NL 对应)语言模型。它们的共同特点是大部分用于处理 PL(或 Source Code)时所采用的技术是从 NLP 中的 Transformer-based 模型迁移而来,但这些 CodePTMs 又各有特点,从训练的角度出发即不同的预训练/微调策略,从数据的角度出发,比如是否使用了代码的结构信息,即抽象语法树(Abstract Syntax Tree,本文将其简称为 AST)及其变体。
而从架构出发,这些 Code 预训练模型大致可以被分为以下这三类:
encoder-only:CuBERT、CodeBERT、GraphCodeBERT 等。
decoder-only:CodeGPT、GPT-C 等。
encoder-decoder:PLBART、CodeT5 等。
本文对各个 CodePTM 建模编程语言的思想进行回顾,并简要分析了一下它们的特色。对文中提到的所有 CodePTMs 的描述主要从背景、预训练策略、微调策略以及下游任务这几个角度出发进行分析,考虑到这些模型之间都存在一些共性以及文章篇幅原因,文中略去了一些通用的处理手段和细节,因此对各部分的分析讲解详略不一,不过都保留了建模编程语言最核心的思想。阅读前需要对 Transformer 有一定的了解。

CuBERT
Learning and Evaluating Contextual Embedding of Source Code. ICML 2020.
https://aclanthology.org/2020.findings-emnlp.139/
CuBERT,即 Code Understanding BERT,和后面提到的 CodeBERT 可被归为同一个时期的工作,虽是首个提出 Code 预训练模型的工作,但和 CodeBERT 相比,其影响力较小(在写这篇文章的时候 CuBERT 引用还没过百),具体原因个人认为是它仅对 Python 语言进行建模(CodeBERT 同时对 6 种编程语言建模),且它的下游任务和 CodeBERT 相比不太丰富,主要是以代码理解任务为主。
作者通过 GitHub 采集了 7.4M Python 语言编写的程序用于 CuBERT 的预训练,将基于 Transformer 类模型处理自然语言的手段迁移到了编程语言上,使用的模型架构和训练方式直接照搬了 BERT-Large(24 层 16 个注意力头),然后使用了一个处理过的 ETH Py150 [1] 数据集进行微调。与此同时,作者还训练了一组 Word2Vec embeddings、Bi-LSTM 模型和 Transformer 模型用于比较。
就任务而言,作者构建了一个(在当时全新的)Benchmark,其中包含了:
五个分类任务(具体细节和描述可参考原文附录)
Variable-Misuse Classification
Wrong Binary Operator
Swapped Operand
Function-Docstring Mismatch
Exception Type
一个定位+修复任务(Variable-Misuse Localization and Repair),也是本文唯一一个非分类任务
就这几个下游任务而言,可以看到 CuBERT 主要还是在做代码理解领域的判别式任务,与后续出现的 CodeXGLUE Benchmark 比其在任务的数量和类型上都有局限性,也导致了这个 Benchmark 没有被广泛使用。而且,由于它仅采用了 Python 语言,和后面出现的各种 CodePTMs 比局限性也比较大,因此仅做简单的科普。

CodeBERT
CodeBERT: A Pre-Trained Model for Programming and Natural Languages. Findings of EMNLP 2020.
https://aclanthology.org/2020.findings-emnlp.139.pdf
相比前面提到同期工作的 CuBERT,CodeBERT 的影响力比它大很多。一方面是因为它是多语言(multi-programming-lingual)模型,纳入了 6 个编程语言,另一方面是它和 MSRA 自己的 CodeXGLUE Benchmark 配套后在各个下游任务上被广泛使用。
除了预训练阶段的任务有变化外,CodeBERT 的其他方面与自然语言中的 BERT 模型训练基本无异(其本质上的一个 RoBERTa),CodeBERT 使用了 bimodal data(即 PL-NL Pairs)进行了预训练,预训练数据的来源为 CodeSearchNet 数据集 [2],其中有 Python, Java, JavaScript, PHP, Ruby 和 Go 这六种编程语言的 2.1M bimodal data 和 6.4M unimodal codes(也就是没有对应 comments 的纯代码),这些数据的来源都是 GitHub 中的开源仓库,并且后续的很多工作也在预训练阶段用了 CodeSearchNet 数据集。
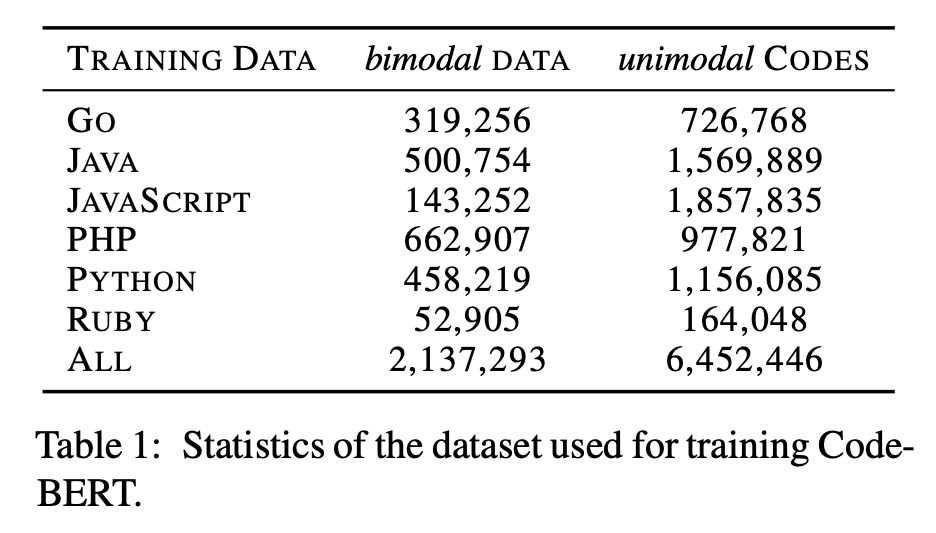
▲ 表中为CodeSearchNet的数据概览
CodeBERT 的输入形式为:
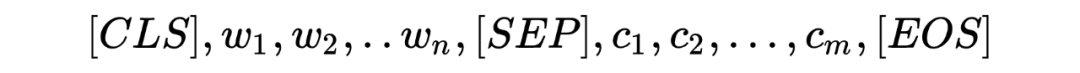
第一段为自然语言文本,第二段为代码,训练的数据可分为两种,即 bimodal data,即 NL-PL Pairs 和 unimodal data,也就是纯代码。

▲ bimodal data
CodeBERT 在预训练阶段的任务有以下两个:
Masked Language Modeling(MLM),算是 Transformer 类模型的预训练中最老生常谈的任务了,作者将其应用于基于 bimodal data 的训练。
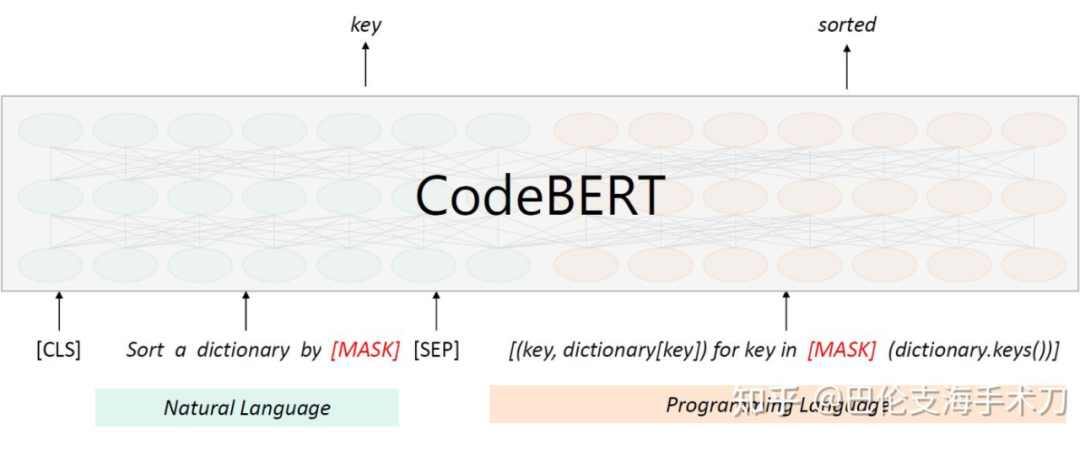
▲ Masked Language Modeling
Replaced Token Detection(RTD),迁移自 ELECTRA,既可以利用 bimodal data 进行训练,还可以进一步利用 unimodal data(比如是没有对应自然语言文本的 code),具体细节可以参考 ELECTRA 原文。
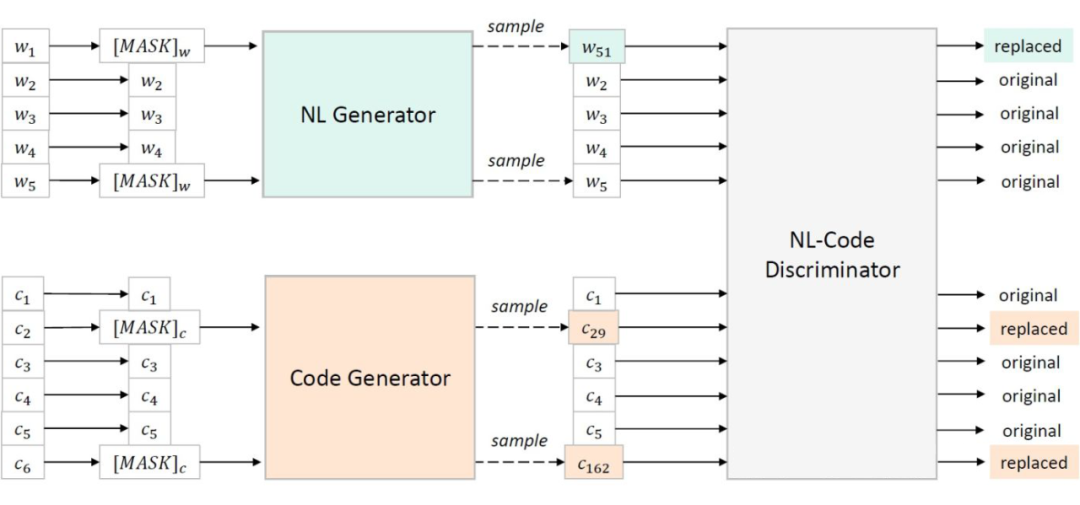
▲ Replaced Token Detection
实验部分做了 Natural Language Code Search,个人认为文中没有添加更多下游任务是受到 EMNLP 的篇幅限制,使用 CodeBERT 可以在多个下游任务,如 Clone detection(克隆检测)、Defect detection(缺陷检测)、Code summarization 等上得到出色的结果,具体可参考 CodeXGLUE [3],如下图所示:
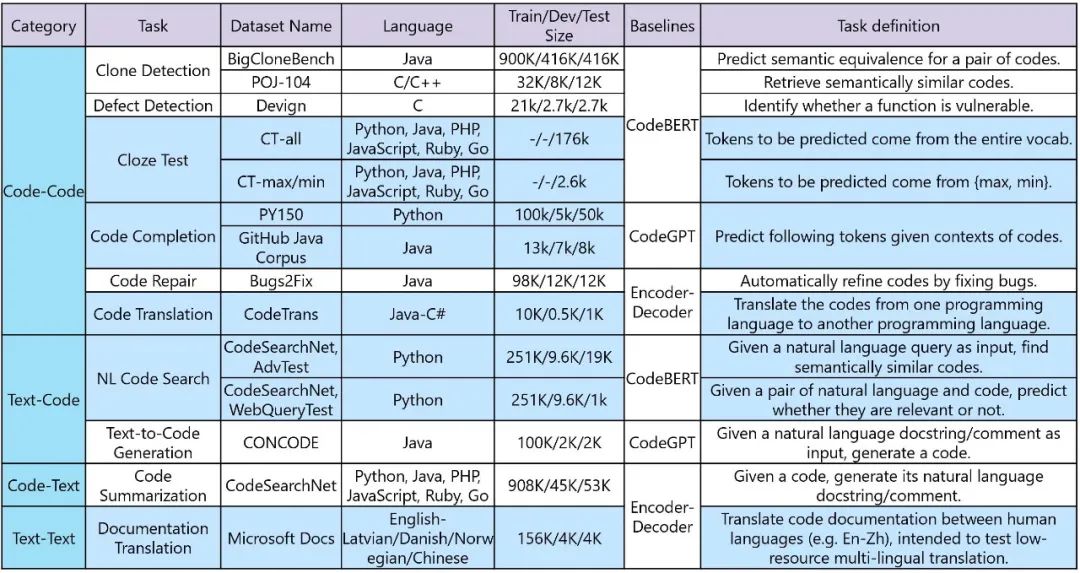
▲ CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
从 CodeBERT 开始,后续的 CodePTMs 就全部继承了对多个 PL 的支持,不过 CodeBERT 完全使用了建模自然语言的手段来为 Code(或是说 NL-PL Pairs)做预训练,忽视了代码的一个很大的特性,那就是结构信息,具体而言就是在编译器进行语法分析阶段生成的抽象语法树(Abstract Syntax Tree,本文称之为AST),紧跟着 CodeBERT 的 GraphCodeBERT 立刻填上了这个坑。

GraphCodeBERT
GraphCodeBERT: Pre-training Code Representations with Data Flow. ICLR 2021.
https://openreview.net/forum?id=jLoC4ez43PZ
看名字就知道这是 CodeBERT 的后续工作,主要想法就是为 CodeBERT 添加代码的语法信息,使 CodePTM 可以显式学习代码的结构信息。
GraphCodeBERT 基于数据流学习代码的表征,如下图所示
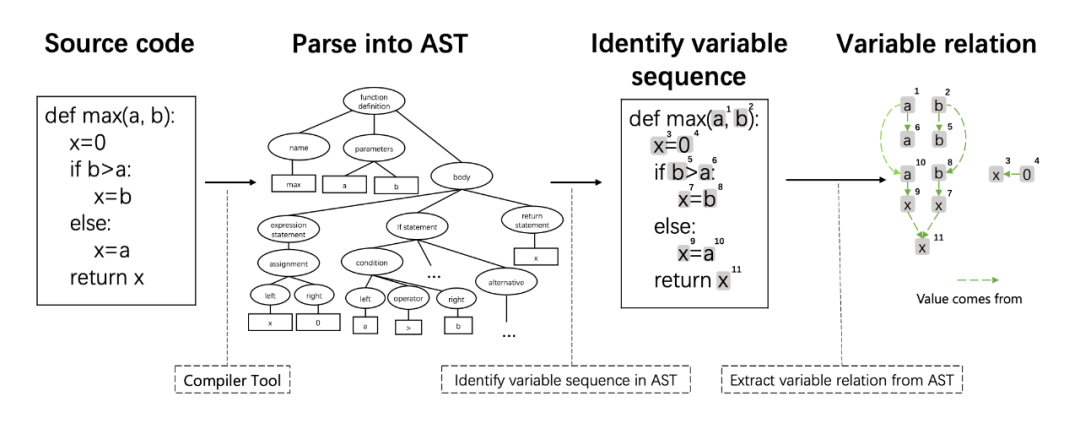
▲ GraphCodeBERT所使用的数据流
数据流的获得分为以下几个步骤:
通过语法分析工具获得 AST,原文中使用的工具是 tree-sitter。
从 AST 中提出变量,构成一个由变量组成的序列。
从 AST 中抽取变量之间的依赖关系,文中称之为“value comes from”,构造数据流图。
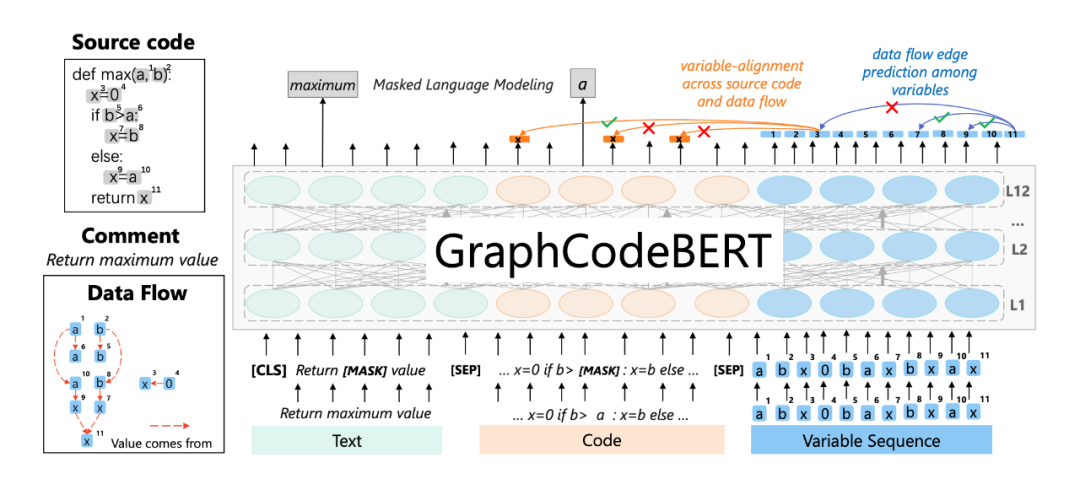
▲ GraphCodeBERT的预训练
GraphCodeBERT 在模型预训练阶段额外提出了两个在当时较为新颖的训练任务
Edge Prediction,即数据流图边预测,通过预测数据流图的边学习代码的结构信息。
Node Alignment,即变量对齐,具体而言是学习数据流图中的某个 node 来自输入代码中的哪个 code token。
将它们和从 CodeBERT(或是 BERT or RoBERTa)继承下来的 MLM 任务一起优化。考虑到 AST 是一种图结构,为了让 Transformer 能适应其与一般序列结构的差异,作者修改了其注意力机制,主要是通过调整 Attention Mask 缩小感受野。
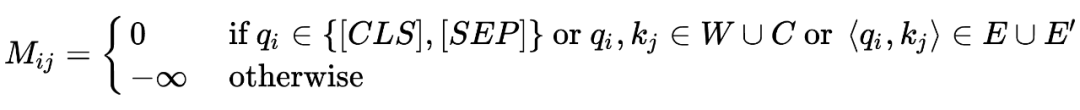
作者将其称为 Graph-Guided Masked Attention,其中 E 代表的是数据流图的边,E' 代表的是数据流图的节点和代码的对应关系边。
就下游任务而言,GraphCodeBERT 文中主要完成了 Natural Language Code Search、Clone Detection、Code Translation 和 Code Refinement 这几个任务,它同样适用 CodeXGLUE Benchmark 中的其他任务,比如 Code Summarization 等。
GraphCodeBERT 相较于前作 CodeBERT 解决了 CodePTM 只学习自然语义,而不学代码结构/语法的问题。但细心的读者或许能发现,学习数据流相较于学习 AST 本身有相当的信息损失,这也为之后的 UniXcoder 挖了一个小坑。

GPT-C
IntelliCode Compose: Code Generation Using Transformer. FSE/ESEC 2020.
https://arxiv.org/abs/2005.08025
GPT-C 是为了代码补全(Code Completion)这个任务而设计的,作者认为之前的的代码补全工作有两点不同。
根据上文的 token 来预测下个 token,没有将代码的全文环境纳入考虑;
多语言效果不佳。
▲ Code Completion
作者提出的 GPT-C 是 GPT-2 模型的变体,在一个大规模、无监督、多语言的数据集上从零开始训练。基于 GPT-C,作者构建了一个代码补全 Framework,称之为 IntelliCode Compose,并对多种编程语言进行建模。作者将 Sequence decoding 的过程视为对树的搜索,搜到出现目标 token 为止。
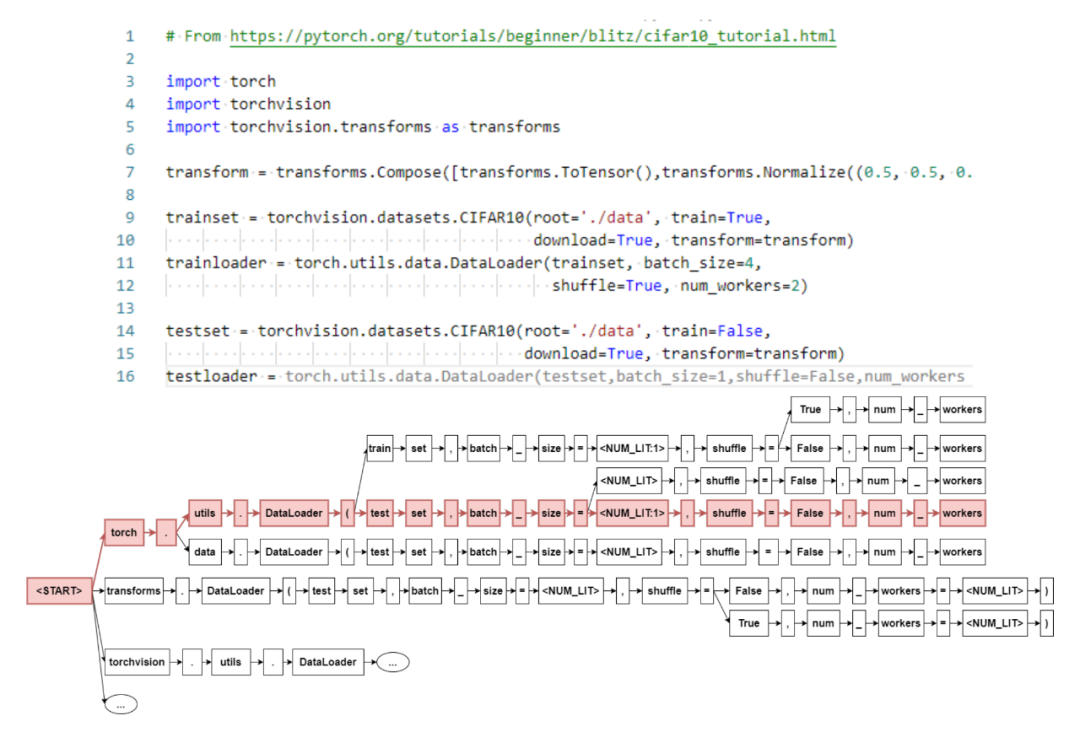
▲ Sequence decoding
虽说是多语言,但是使用的是 Python, C#, JavaScript 和 TypeScript,和 CodeXGLUE 不同且少了两个语言。就多语言模型的训练而言,作者提出了四个训练的策略
Language-agnostic baseline,即忽略掉编程语言的不同构建一个 baseline 多语言模型。
Language-type embedding,即加入一个向量来表示每种编程语言,和 token embedding 等相加。
Language-specific control codes,每个输入的训练样本前拼接一个"lang ∗ remaining token sequence”字符串,∗即为编程语言。
add a programming language classification task during model pretraining,即在预训练阶段加入一个分类编程语言的任务。
随后在下游任务上验证了这几个方案的效果,证明了 Language-type embedding 和 control codes 方案在对各编程语言建模方面的有效性。
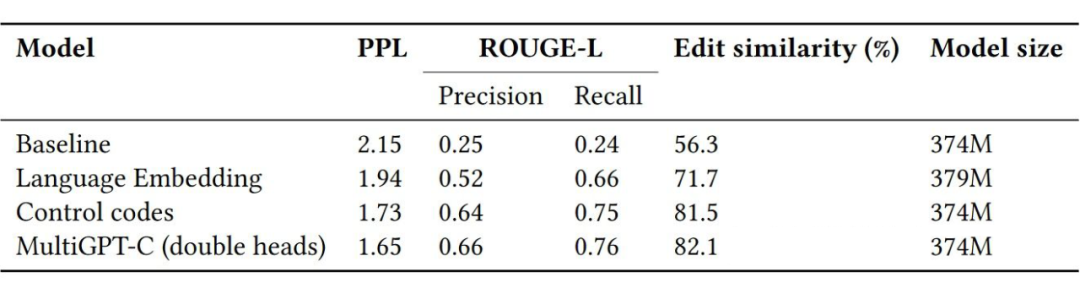
▲ multilingual modeling approaches based on GPT-C
在文末,作者考虑到了模型的推理开销问题,还上了一个知识蒸馏,并且还讨论了一下模型基于 K8S 和 VS Code 的部署应用等问题。

Code-GPT
Code-GPT 是在 CodeXGLUE 中被提出的,没有单独成文,不要和 GPT-C 搞混了。作者实现它的目的是为了 code completion 和 text-to-code generation 任务。它就是一个由 Code 训练,与 GPT-2 完全同架构的 12 层 Transformer Decoder 模型,不过 MSRA 的研究者实现了两个版本。
Pretrained from scratch:随机初始化,从零训练;
CodeGPT-adapted:先使用一个 GPT-2 作为起始点,再持续使用 Code 进行训练,作者将这个方法称为“domain-adaptive”。
更详细的内容可以参考 CodeXGLUE 原文的 4.2 节,作者在 Huggingface 提供了 CodeGPT-small-java [4] 和 CodeGPT-small-java-adapted [5] 这两个 checkpoints,正常地使用 transformers 库加载就能使用了。

PLBART
Unified Pre-training for Program Understanding and Generation. NAACL 2021.
https://arxiv.org/abs/2103.06333
顾名思义,就是应用于编程语言的 BART,参考了文章:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(ACL 2020)[6]。
先简单说下 BART,它吸收了 BERT 模型的双向编码器和 GPT 中的单向 left-to-right 解码器这二者的优点,因此比 BERT 更适合文本生成的场景(BERT 因 Pre-training 阶段和生成式下游任务差异比较大,因此被认为不适合做 NLG 相关任务),而它相比 GPT,也多了双向上下文语境信息(GPT 是单向建模)。除此之外,相比 BERT 的 Token Masking,BART 对 Encoder 端采用了更加复杂的Noise。
基于对 BART 的知识,理解 PLBART 并不算困难,其使用了和 BART-base 相同的架构,唯一结构上的不同的是它在 Encoder 和 Decoder 的顶部添加了一个额外的 LayerNorm。在 Noise 策略方面,PLBART 使用了 token masking, token deletion 和 token infilling 这三种策略,与 BART 相比少了 Sentence Permutation 和 Document Rotation 这两个任务,这些任务的细节都可以参考 BART 原文。
在微调下游任务方面,作者将 PLBART 的下游任务分为两块。
首先是 Sequence Generation,又可细分为三个任务,可参考下图:

▲ PLBART: Sequence Generation
其次是 Sequence Classification:将序列尾部的 special token 喂给线性分类器用于预测,与 BERT 等模型的分类区别不大。
实验与比较方面,作者先指定了 baseline 模型,并将其分成了两种:
Training from Scratch,作者用下游任务的数据集从零开始训练了 LSTM + Attention 以及一个 Transformer。
Pre-trained Models,作者挑选了 RoBERTa、CodeBERT、GraphCodeBERT、GPT-2、CodeGPT(-adapted)。
具体的实验部分做了 Code Summarization、Code Generation、Code Translation 这三个生成式任务,效果自然是好的,在 Classification 方面做了两个任务:clone detection 和 vulnerability detection,在后者上 PLBART 不如基于 AST 的模型。

CodeT5
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. EMNLP 2021.
https://aclanthology.org/2021.emnlp-main.685/
文中对 CodeT5 的描述是:a unified pre-trained encoder-decoder Transformer model that better leverages the code semantics conveyed from the developer-assigned identifiers,即一个能更好地利用代码语法信息(形式是 identifier,即标识符)的统一预训练 Transformer 模型。在开始之前,和 PLBART 一样,先简单说下 Google T5 模型。T5 的名字来源是 Text-To-Text Transfer Transformer,顾名思义 T5 把所有的 NLP 问题统一归纳为了 Text2Text 任务,用来做 NMT、QA、文本摘要和文本分类任务。

▲ Text-To-Text Transfer Transformer
对比下 T5 原文,可以发现二者的核心思想还是非常类似的,作者将 CodeT5 归纳为 a pre-trained encoder-decoder model that considers the token type information in code,细心的玩家可能发现了,前面提到的 CodeBERT 为首的 BERT 类模型和 CodeGPT 为首的 GPT 类模型,仅含有 Encoder 或 Decoder,而非完整利用一个 Transformer 架构来处理代码。因此 CodeT5 最大的卖点即第一个 unified encoder-decoder CodePTM,可以理解为完全使用了 Transformer 的两个部分。
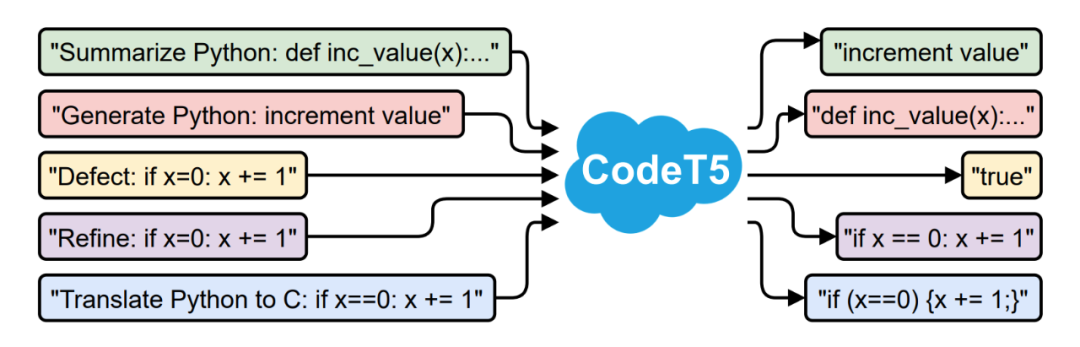
▲ CodeT5 Illustration
此外,除了使用 T5 的架构外,作者使用了以下两个方案来更好地利用代码结构特性:
使用了代码的标识符信息,提出了 Identifier-aware Pre-training,是一个与 T5中Masked Span 类似的目标,简而言之就是随机 mask 掉任意长度的 Span,然后让 decoder 去预测。
利用了代码地 Comments(自然语言注释)信息,作者称之为 Bimodel Dual Generation,让自然语言和源代码的表征可以对齐,帮助缓和 Pre-training 和 Fine-Tuning 阶段的差距。
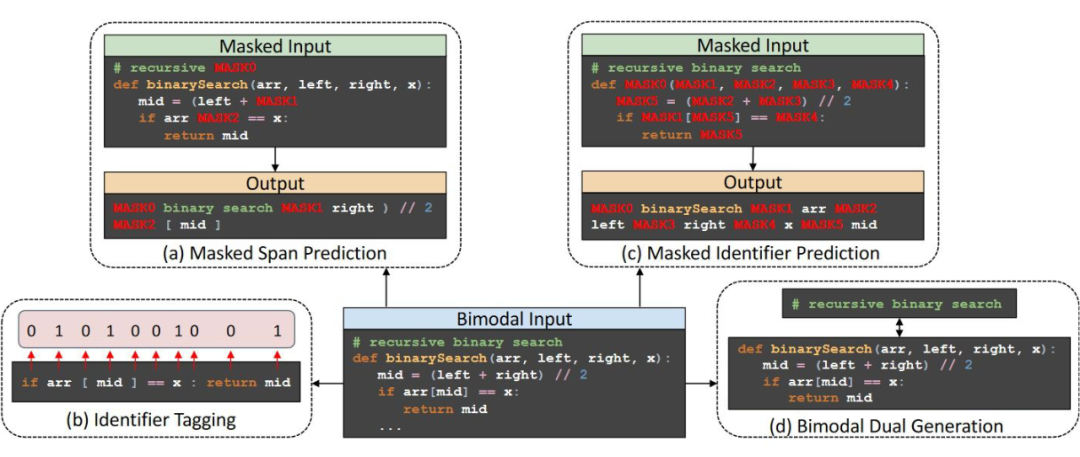
▲ Identifier-aware Pre-training
文章发表时在 CodeXGLUE Benchmark 的若干任务上取得了 SOTA 效果。

UniXcoder
UniXcoder: Unified Cross-Modal Pre-training for Code Representation. ACL 2022.
https://arxiv.org/pdf/2203.03850.pdf
这是当今(2022.7)的 SOTA 模型,参考了 NIPS 2019: Unified Language Model Pre-training for Natural Language Understanding and Generation [7]。
文章选择了五个任务,分为以下三类:
代码理解任务:Clone Detection 和 Code Search
代码生成任务:Code Summary 和 Code Generation
自回归任务:Code Completion
本文很重要的一个卖点就是更全面地利用了 AST 提供的代码结构信息。文章开头讲过,AST 一般会被表示为一个 Tree 结构,不能直接作为 Transformer 类模型的输入,回忆一下前面提到的 GraphCodeBERT,作者在以损失相当一部分信息的情况下让模型学习 AST 的数据流。为了能更加有效地利用 AST,因此 UniXcoder 地作者构建了一个 one-to-one 的 mapping function,将 AST 转为一个序列结构(flattened token sequence),然后和Code Comments一同编码,对这个 mapping function 的有效性的证明在文章的附录中。
模型结构方面,UniXcoder 的一个卖点就是一个统一的,可以同时兼容 Encoder-Only,Decoder-Only 和 Encoder-Decoder 三种模式的 CodePTM,相当于给模型添加了“开关”,来决定采用什么模式处理任务,用白话讲,就是通过使用三种不同类型的自注意力 Mask 策略来控制模型的行为。
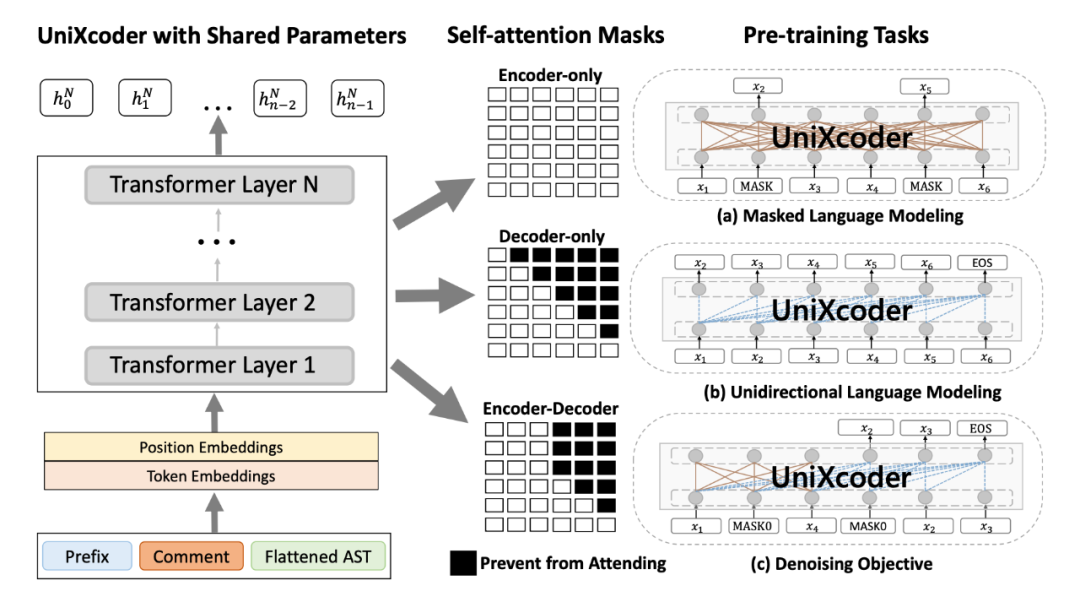
▲ UniXcoder的架构
既然同时能拥有三种模式,那么自然会有更多预训练任务,如下所示:
Masked Language Modeling(MLM),算是基本操作了。
Unidirectional Language Modeling(ULM),用于训练 decoder-only 模式,帮助完成自回归任务,对应的是右上三角 masking。
Denoising Objective DeNoiSing(DNS),可参考 BART 和 T5,用于训练 encoder-decoder 模式,帮助完成生成任务,参考架构图中的 encoder-decoder 部分。
除了上面这些任务以外,作者还提出了 Code Fragment Representation Learning。
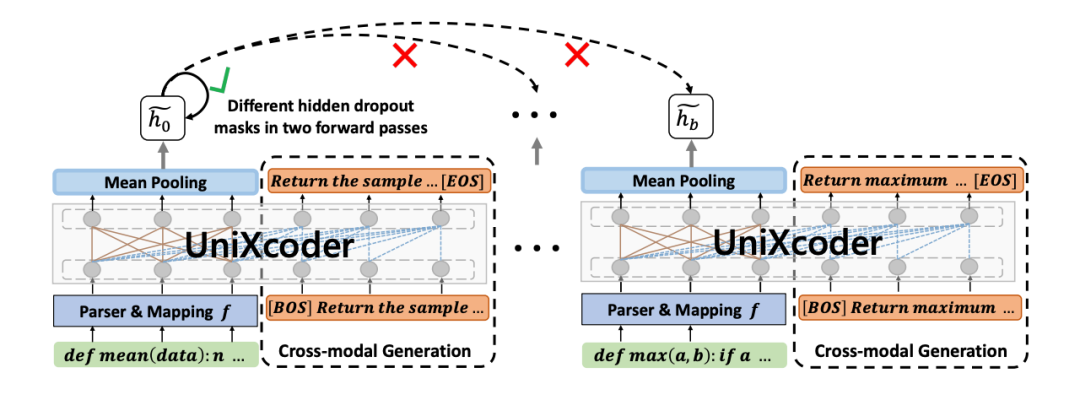
▲ Code Fragment Representation Learning
其中包含了 Multi-modal Contrastive Learning(MCL)和 Cross-Modal Generation(CMG)这两个任务。前者采用了一个对比学习损失,后者是使用了一个统一的自然语言描述(comment),文中使用了 fulcrum,即支点这个词,让模型学习到的代码表征在不同语言之间的对齐。
还需注意的一点就是,UniXcoder 在预训练和微调这两个阶段中的输入形式有所不同,由于引入了 Flattened AST,AST 展开后的序列中被引入了大量额外的 tokens(70% longer)会导致额外的开销。因此,在微调阶段 UniXcoder 仅使用 AST 的叶子节点,为了缓解这个 gap,在预训练阶段作者设置了 0.5 的概率随机丢弃输入序列中的非叶子节点。
除了 Clone Detection、Code Search、Code Summarization 和 Code Completion 等任务上表现较好外,UniXcoder 还提供了一个新任务:zero-shot code-to-code search,即在 zero-shot 的情境下,通过一个源代码的 query 在 candidates 集合中寻找语义相同的源代码,该任务使用的数据集是 CodeNet [8],用来衡量训练所得的 code fragment embeddings 的效果。

▲ zero-shot code-to-code search

相关代码整理
CuBERT:
https://github.com/google-research/google-research/tree/master/cubert
CodeBERT、GraphCodeBERT 和 UniXCoder
MSRA 提供了 CodeBERT、GraphCodeBERT 和 UniXCoder 在下游任务微调时可用的代码,在仓库:
https://github.com/microsoft/CodeBERT
但没有提供预训练阶段的实现(CodeBERT 和 UniXCoder 在预训练阶段都使用了 16 张 32GB NVIDIA Tesla V100 实现),使用时通过 transformers 加载 checkpoints 就可使用。
此外,huggingface 还提供了一个经济适用版的 CodeBERT 模型:
https://huggingface.co/huggingface/CodeBERTa-small-v1
CodeGPT
与上述三个 MSRA 提供的模型一样,CodeGPT 仍然是提供了可通过 transformers 加载 checkpoints,即:
https://huggingface.co/microsoft/CodeGPT-small-java-adaptedGPT2
CodeT5:
https://github.com/salesforce/codet5
PLBART:
https://github.com/wasiahmad/PLBART

总结
上述对 CodePTMs 相关的内容大致上是六月中下旬赶一个文章时调研文献后总结的笔记,然后补充了点链接和细节,实验部分写的比较简略,是因为如果每个模型的实验都要全讲的话篇幅就太长了,而且这些任务都大差不差,每个模型都讲一遍冗余会比较多,之后可能会在其他文章补充。
此外,有一些影响力比较小或者 Task-specific 的工作可能没完全覆盖到。总而言之,不论是 CodeBERT 开的新坑还是今天的 SOTA 模型 UniXcoder,MSRA 在这个领域还是完全 dominant 的存在。对于 CodeBERT 和 GraphCodeBERT 为首的大模型,复现预训练阶段的成本很高,不适合平民玩家,而且今年五月的 IJCAI 22 Survey Track 连 CodePTMs 的 Survey 工作都已经出了(Deep Learning Meets Software Engineering: A Survey on Pre-Trained Models of Source Code [9]),可能短时间内出革命性的新模型的可能性不大,而且 Code 领域使用的这些方法终究还是跟着 NLP 走的,需要 NLP 提出新技术后 Code 领域才有跟进的可能。
个人感觉接下来在这个相对较小但很卷的领域的研究热点可能会慢慢向可解释性和模型分析(Analysis of Models & Interpretability)方面转移,最近还研读了一些 22 年新出的 Probing CodePTMs 的文章,之后再补充。

参考文献
[1] https://github.com/google-research-datasets/eth_py150_open
[2] https://github.com/github/CodeSearchNet
[3] https://github.com/microsoft/CodeXGLUE
[4] https://huggingface.co/microsoft/CodeGPT-small-java
[5] https://huggingface.co/microsoft/CodeGPT-small-java-adaptedGPT2
[6] https://arxiv.org/pdf/1910.13461.pdf
[7] https://proceedings.neurips.cc/paper/2019/hash/c20bb2d9a50d5ac1f713f8b34d9aac5a-Abs
[8] https://arxiv.org/abs/2105.12655v1
[9] https://arxiv.org/abs/2205.11739
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









