







©作者 | 李逸清
单位 | 宁波大学本科生
研究方向 | 计算机视觉
本来打算寒假学学 CUDA,在 github 上找些项目研究一下,然后碰到一个超好玩的东西——一个可视化的 CUDA 解谜项目!
https://github.com/srush/GPU-Puzzles
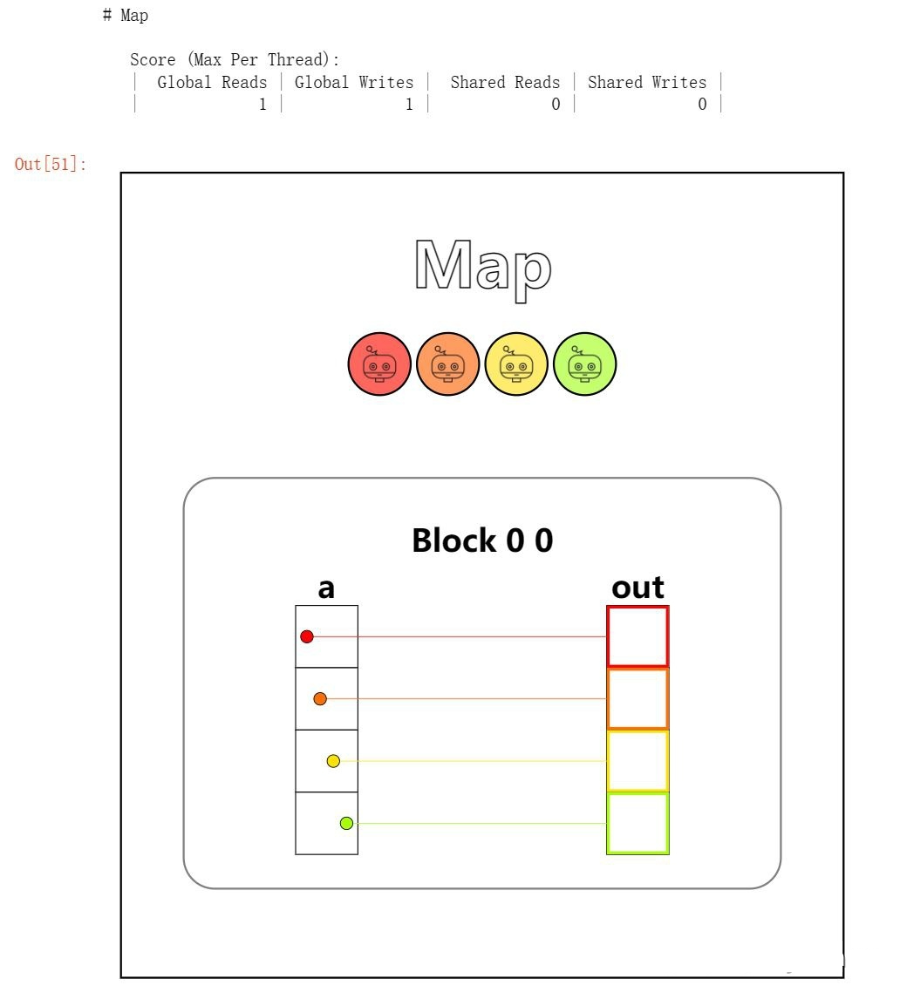
第一题 - Map
Implement a "kernel" (GPU function) that adds 10 to each position of vectoraand stores it in vectorout. You have 1 thread per position.
把给定数组a的值映射到数组out上,规则由map_spec给出,就是+10,题目给出的代码是:
def map_spec(a):
return a + 10
def map_test(cuda):
def call(out, a) -> None:
local_i = cuda.threadIdx.x
# FILL ME IN (roughly 1 lines)
return call
SIZE = 4
out = np.zeros((SIZE,))
a = np.arange(SIZE)
problem = CudaProblem(
"Map", map_test, [a], out, threadsperblock=Coord(SIZE, 1), spec=map_spec
)
problem.show()然后我们在_test()函数处# FILL ME IN (roughly 1 lines)的地方,补全代码就可以了。
这里其他创建 block 什么的我们都不需要干,已经为我们搭建了一个 block 中的四条 thread,然后只需要每个 thread 执行的时候只给数组对应 thread 编号的位置进行处理,这样就实现了并行操作。
上面的map_spec只是提示需要完成的工作,写CUDA不能像下面这样直接调用,The puzzles only require doing simple operations, basically +, *, simple array indexing, for loops, and if statements.
out[local_i] = map_spec(a[local_i])而要写成:
out[local_i] = a[local_i] + 10然后运行一下,就会有可视化的结果出现。
然后 check 一下结果,通过还可以有奖励猫狗视频(哈哈哈哈可爱)。
第二题 - Zip
Implement a kernel that adds together each position of a and b and stores it in out. You have 1 thread per position.
out[local_i]=a[local_i] + b[local_i]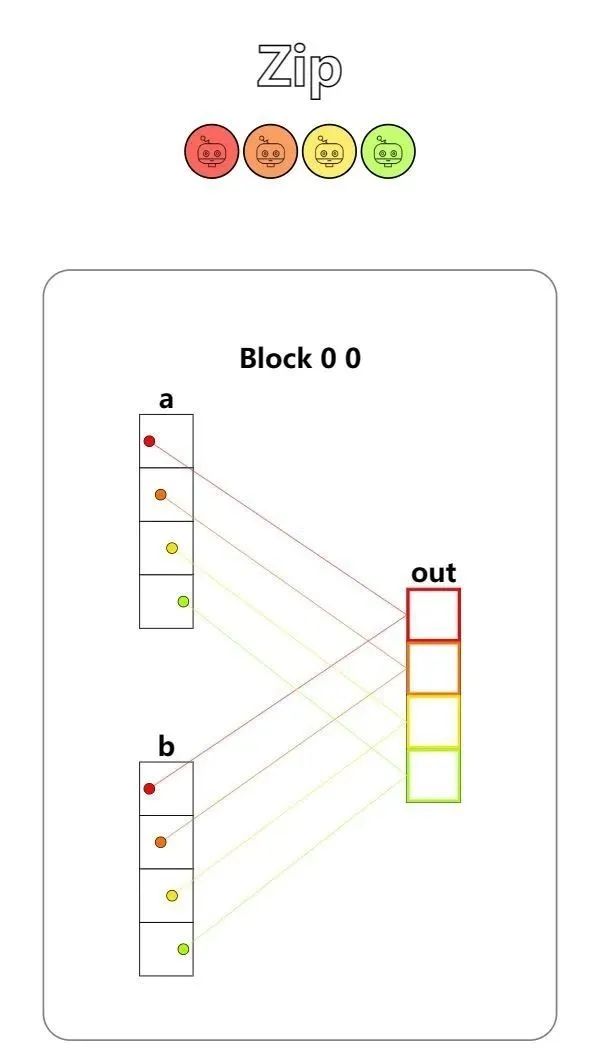
第三题 - Guards
Implement a kernel that adds 10 to each position of a and stores it in out. You have more threads than positions.
现在是和第一题相同,但是问题是我们每个 block 里的 thread 数量大于数组长度,所以需要 guard,应该就是哨兵吧,反正检测一下就可以啦。
if local_i < 4:
out[local_i] = a[local_i] + 10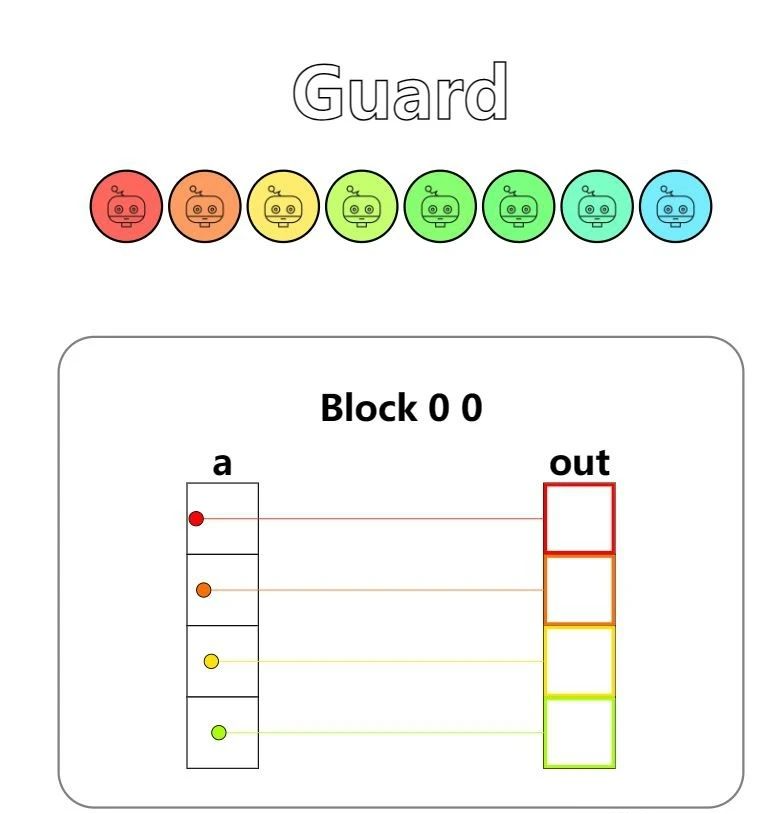
第四题 - Map 2D
Implement a kernel that adds 10 to each position of a and stores it in out. Input a is 2D and square. You have more threads than positions.
现在在第三题的基础上更进一步(贴近现实),thread 的编号变成了 2D 的,我们需要处理的 list 也变成了矩阵了。
def map_2D_test(cuda):
def call(out, a, size) -> None:
local_i = cuda.threadIdx.x
local_j = cuda.threadIdx.y
# FILL ME IN (roughly 2 lines)
return call
SIZE = 2
out = np.zeros((SIZE, SIZE))
a = np.arange(SIZE * SIZE).reshape((SIZE, SIZE))
problem = CudaProblem(
"Map 2D", map_2D_test, [a], out, [SIZE], threadsperblock=Coord(3, 3), spec=map_spec
)
problem.show()依旧是要加 guard:
if local_i < 2 and local_j < 2:
out[local_i, local_j] = a[local_i, local_j] + 10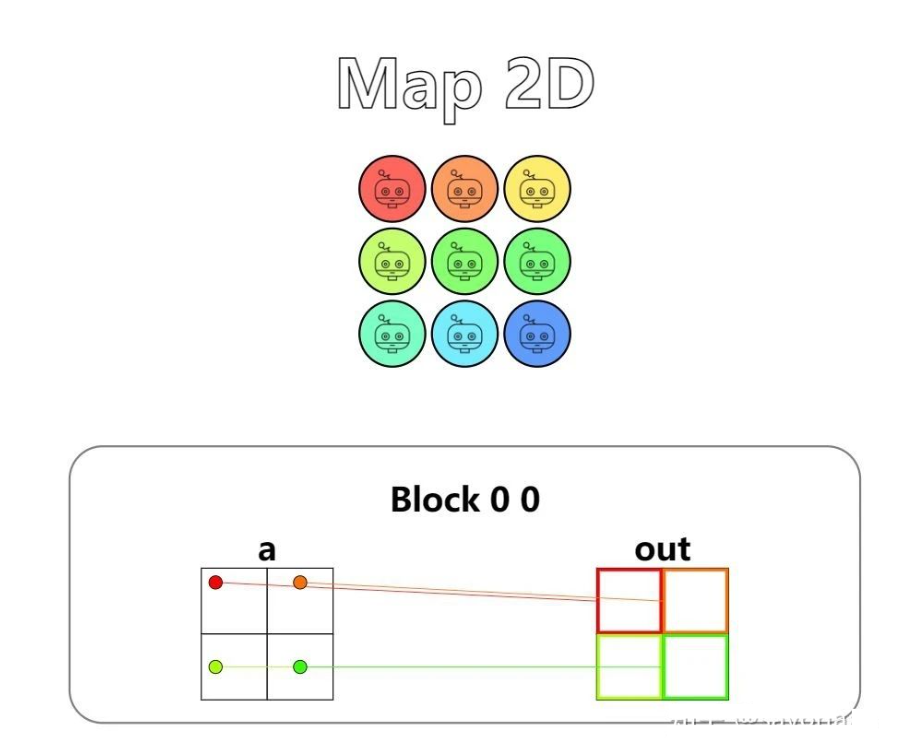
第五题 - Broadcast
Implement a kernel that adds a and b and stores it in out. Inputs a and b are vectors. You have more threads than positions.
if local_i < 2 and local_j < 2:
out[local_i, local_j] = a[local_i, 0] + b[0, local_j]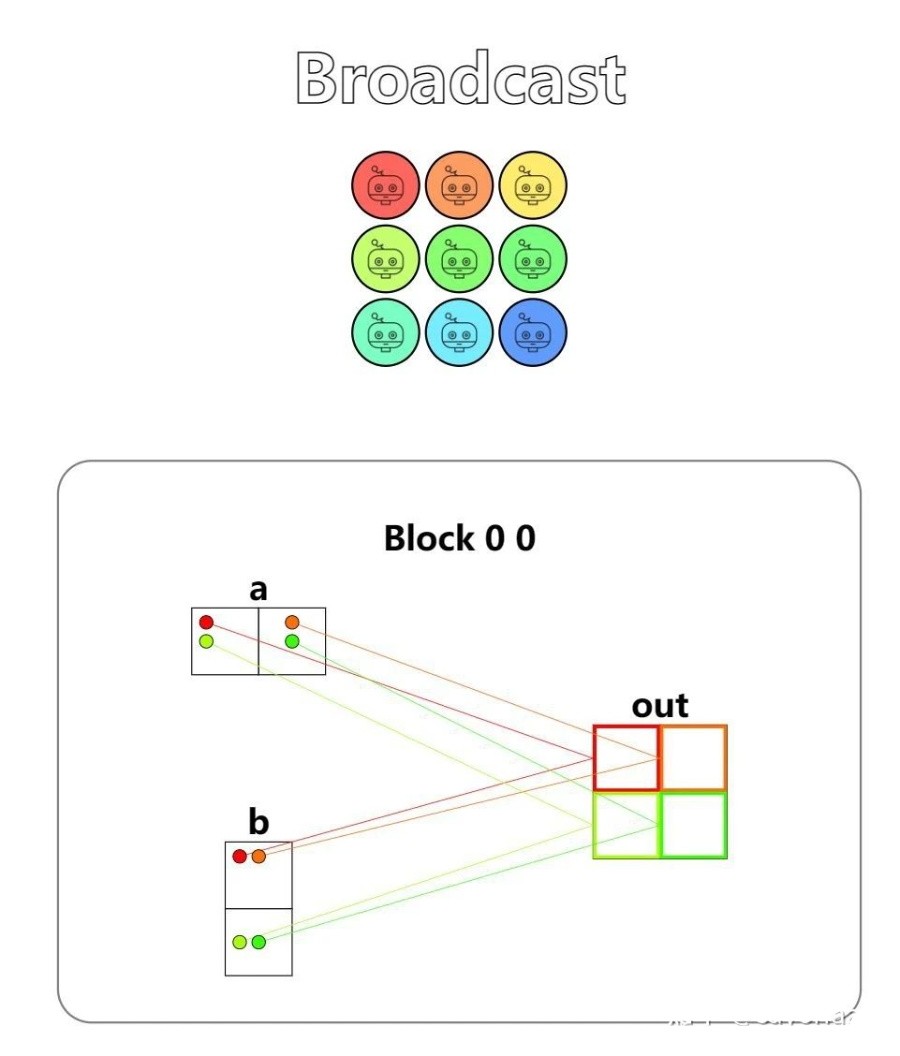
第六题 - Blocks
Implement a kernel that adds 10 to each position of a and stores it in out. You have fewer threads per block than the size of a.
Tip: A block is a group of threads. The number of threads per block is limited, but we can have many different blocks. Variable cuda.blockIdx tells us what block we are in.
现在我们终于接触到了 block 层级,因为硬件的原因每个 block 的数量是死的,但是我们可以通过调用不同多个 block 来对更多的 thread 进行操作。
所以现在的问题就是更常见的,数组的长度要大于单个 block 里的 thread 数量的情况(在这个问题里,每个 block 有 4 个 thread,而数组长度是 9,我们可以调用 3 个 block 的资源)。
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
# FILL ME IN (roughly 2 lines)
if i < 9:
out[i] = a[i] + 10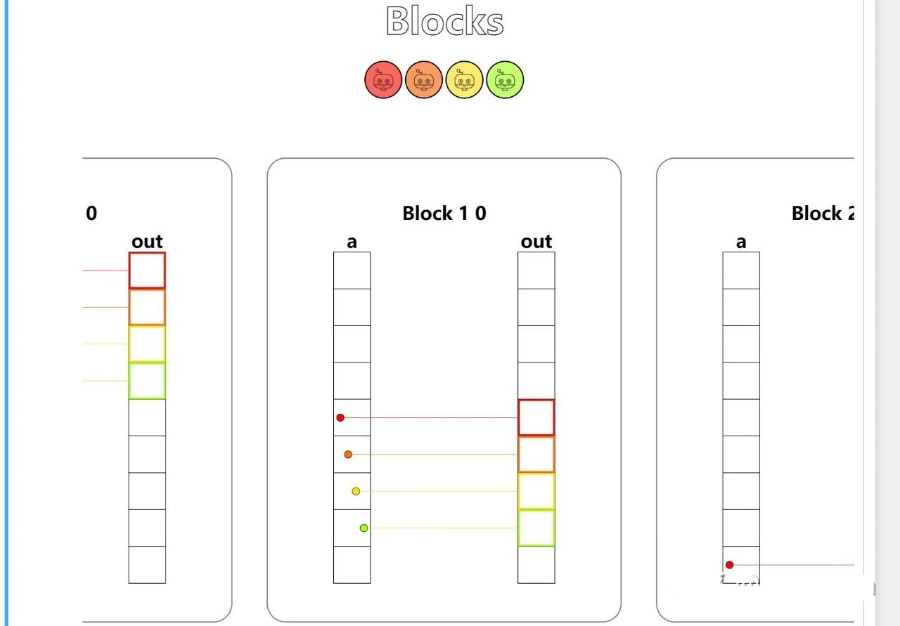
第七题 - Blocks 2D
Implement the same kernel in 2D. You have fewer threads per block than the size of a in both directions.
展现一下错误想法:
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
# FILL ME IN (roughly 4 lines)
if i < 25:
x = i // 5
y = i % 5
out[x, y] = a[x, y] + 10实际上。。。
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
# FILL ME IN (roughly 4 lines)
j = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
if i < 5 and j < 5:
out[i, j] = a[i, j] + 10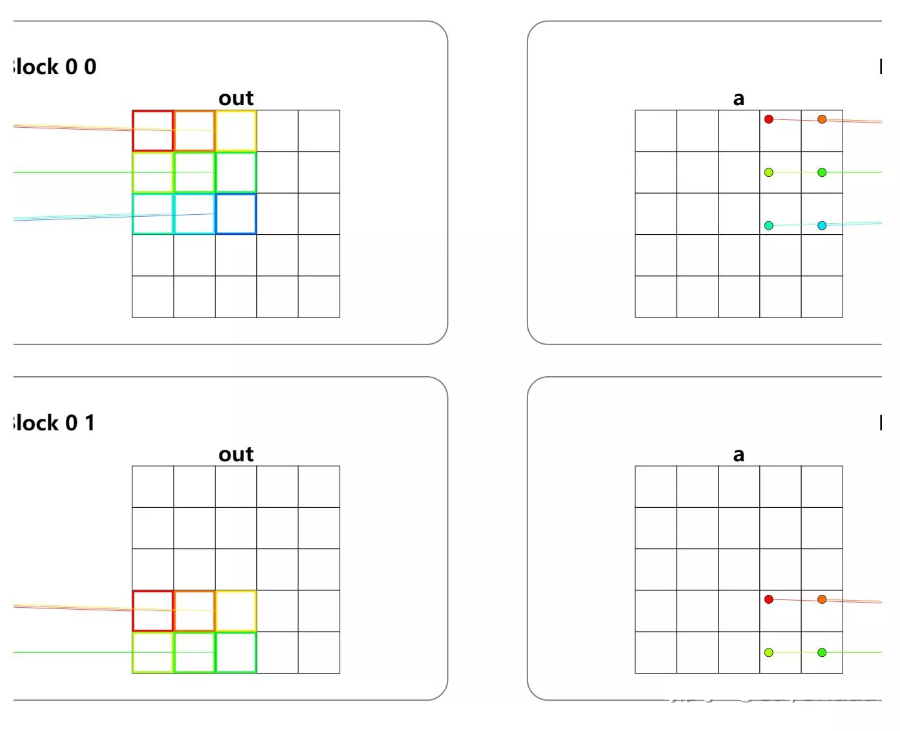
第八题 - Shared
Implement a kernel that adds 10 to each position of a and stores it in out. You have fewer threads per block than the size of a.
Warning: Each block can only have a constant amount of shared memory that threads in that block can read and write to. This needs to be a literal python constant not a variable. After writing to shared memory you need to call cuda.syncthreads to ensure that threads do not cross.
这一题就是关于 block 内部缓存的使用,先把a数组里的一部分数据放到这个 block 内部的存储里(每个线程需要 call cuda.syncthreads),再通过访问 block 内部存储得到out数组。
shared = cuda.shared.array(TPB, numba.float32)
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
local_i = cuda.threadIdx.x
if i < size:
shared[local_i] = a[i]
cuda.syncthreads()
# FILL ME IN (roughly 2 lines)
if i < size:
out[i] = shared[local_i] + 10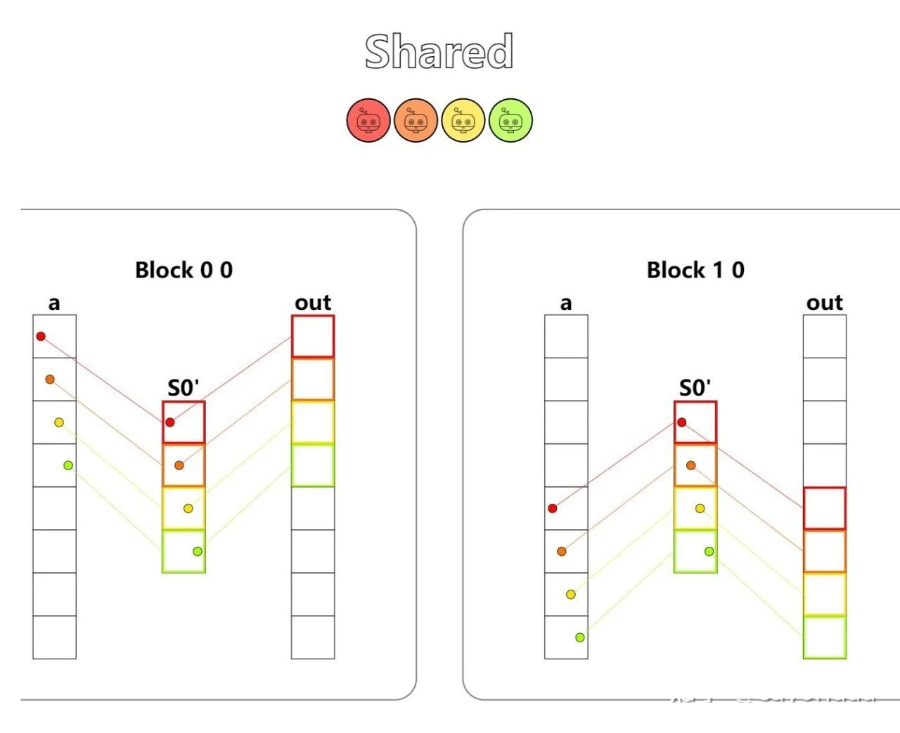
第九题 - Pooling
Implement a kernel that sums together the last 3 position of a and stores it in out. You have 1 thread per position. You only need 1 global read and 1 global write per thread.
好家伙,这是直接来写池化层了么,但是提供了池化的算法应用一下就可以了(这里不用 shared 也可以过样例)。
shared = cuda.shared.array(TPB, numba.float32)
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
local_i = cuda.threadIdx.x
# FILL ME IN (roughly 8 lines)
if i < size:
shared[i] = a[i]
cuda.syncthreads()
for k in range(3):
if i-k >= 0:
out[i] = out[i] + shared[i-k]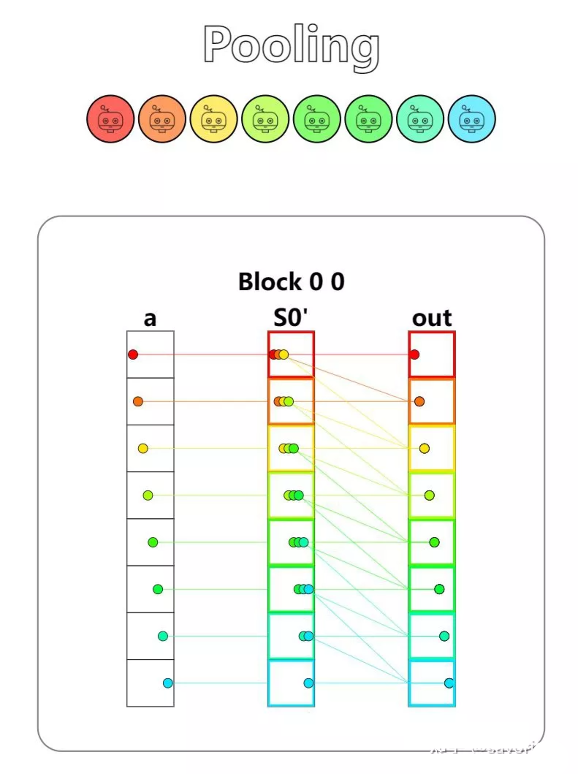
第十题 - Dot Product
Implement a kernel that computes the dot-product of a and b and stores it in out. You have 1 thread per position. You only need 2 global reads and 1 global write per thread.
Note: For this problem you don't need to worry about number of shared reads. We will handle that challenge later.
所以问题就是乘法并行很自然,但是加法怎么并行,直接加的话样例过不了,我突然有一个好主意,一起上要挂那干脆然一个线程来干呗。
shared = cuda.shared.array(TPB, numba.float32)
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
local_i = cuda.threadIdx.x
# FILL ME IN (roughly 9 lines)
if i < size:
shared[i] = a[i] * b[i]
cuda.syncthreads()
if i==0:
for k in range(size):
out[0] = out[0] + shared[k]哈哈哈我可真是个大聪明,虽然过了样例但是这样既不优雅,也不满足题目要求。
# Dot
Score (Max Per Thread):
| Global Reads | Global Writes | Shared Reads | Shared Writes |
| 10 | 8 | 8 | 1 |所以去翻书,发现点乘是最经典的归约操作,我们需要的就是操作系统里的原子操作!!必须只有一个 thread 工作,其他都被 block 掉。
但是这里不支持。。。
这我不会了,先放着(做到后面发现在十二题有提示)。
第十一题 - 1D Convolution
Implement a kernel that computes a 1D convolution between a and b and stores it in out. You need to handle the general case. You only need 2 global reads and 1 global write per thread.
这里的卷积操作是:
def conv_spec(a, b):
out = np.zeros(*a.shape)
len = b.shape[0]
for i in range(a.shape[0]):
out[i] = sum([a[i + j] * b[j] for j in range(len) if i + j < a.shape[0]])
return out就是b数组依次与a数组的0号,1号...元素对齐,点乘,作为out数组的0号,1号...元素,然后到后面b数组有多余的话就不管。
shared = cuda.shared.array(TPB_MAX_CONV, numba.float32)
if local_i < b_size:
shared[TPB + local_i] = b[local_i]
cuda.syncthreads()
if i < a_size:
shared[i] = a[i]
cuda.syncthreads()
acc = 0
for k in range(3):
if i+k < TPB:
acc =acc + shared[i+k] * shared[TPB+k]
out[i] =acc这里如果不用中间变量acc就会出 bug,也不知道为啥。
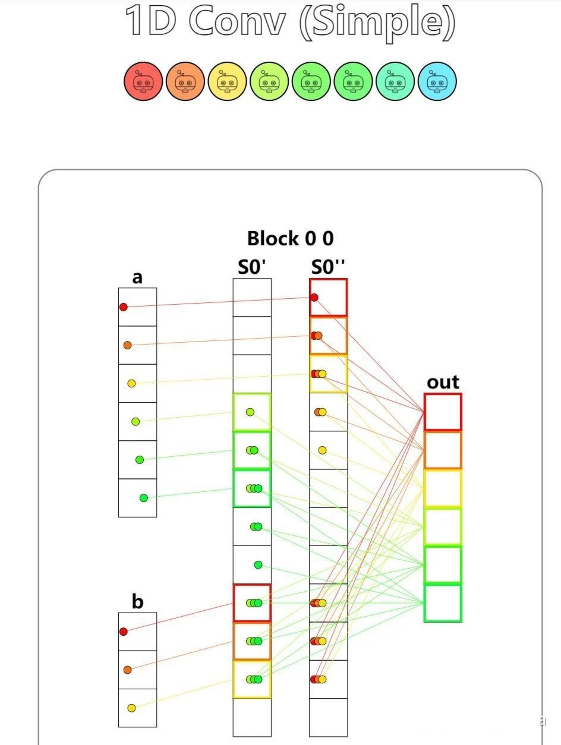
然后这个代码到用例 2 就过不了。。。估计因为 shared 没考虑好,然后另外一个问题就是,卷积核刚好涉及到两个 block 的数据,另外b_size硬编码了...
shared = cuda.shared.array(TPB_MAX_CONV, numba.float32)
if local_i < b_size:
shared[TPB + local_i] = b[local_i]
cuda.syncthreads()
if i < a_size:
shared[local_i] = a[i]
cuda.syncthreads()
acc = 0
for k in range(b_size):
if i+k < a_size:
if local_i + k < TPB:
acc =acc + shared[local_i+k] * shared[TPB+k]
else:
acc =acc + a[i+k] * shared[TPB+k]
out[i] =acc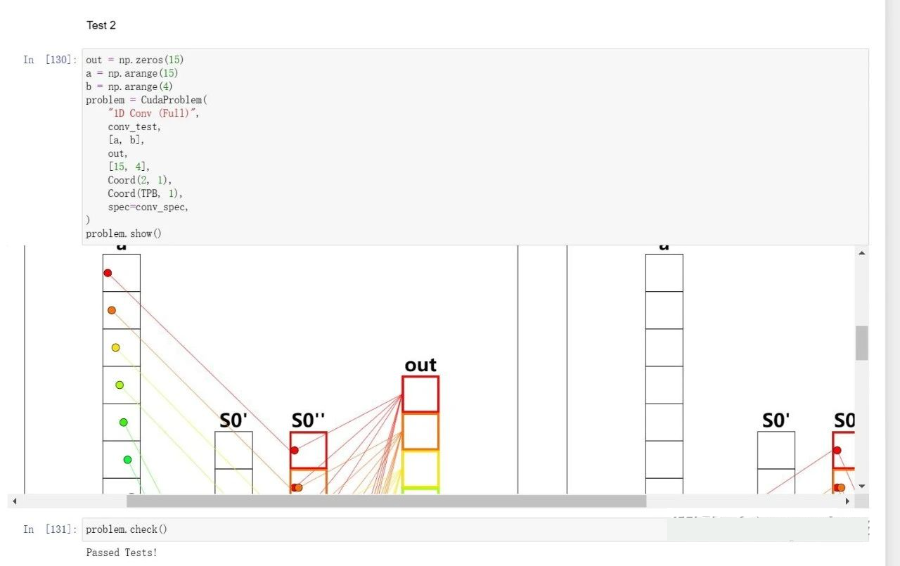
第十二题 - Prefix Sum
Implement a kernel that computes a sum over a and stores it in out. If the size of a is greater than the block size, only store the sum of each block.
We will do this using the parallel prefix sum algorithm in shared memory. That is, each step of the algorithm should sum together half the remaining numbers. Follow this diagram:
就是求一下前缀和,比如1 2 3 4 5对应1 3 6 10 15,那这里需要输出15,搬运一下维基百科,有两种算法,题目要求我们用后者。
Algorithm 1: Shorter span, more parallel
Circuit representation of a highly parallel 16-input parallel prefix sum.
Hillis and Steele present the following parallel prefix sum algorithm: [9]
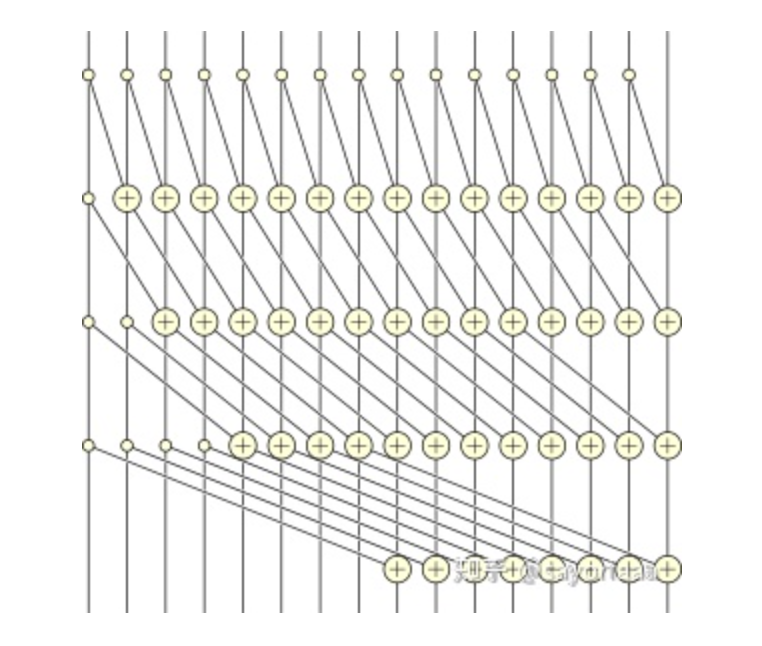
With a single processor this algorithm would run in O(nlog n) time. However if the machine has at least n processors to perform the inner loop in parallel, the algorithm as a whole runs in O(log n) time, the number of iterations of the outer loop.
Algorithm 2: Work-efficient
Circuit representation of a work-efficient 16-input parallel prefix sum.
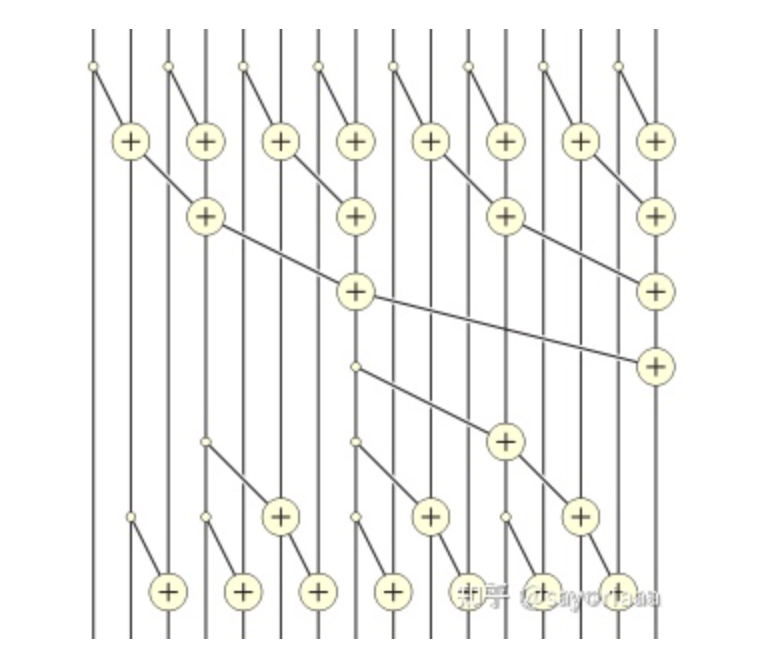
A work-efficient parallel prefix sum can be computed by the following steps.
1. Compute the sums of consecutive pairs of items in which the first item of the pair has an even index: z0 = x0 + x1, z1 = x2 + x3, etc.
2. Recursively compute the prefix sum w0, w1, w2, ... of the sequence z0, z1, z2, ...
3. Express each term of the final sequence y0, y1, y2, ... as the sum of up to two terms of these intermediate sequences: y0 = x0, y1 = z0, y2 = z0 + x2, y3 = w1, etc. After the first value, each successive number yi is either copied from a position half as far through the w sequence, or is the previous value added to one value in the x sequence.
If the input sequence has n steps, then the recursion continues to a depth of O(log n), which is also the bound on the parallel running time of this algorithm. The number of steps of the algorithm is O(n), and it can be implemented on a parallel random access machine with O(n/log n) processors without any asymptotic slowdown by assigning multiple indices to each processor in rounds of the algorithm for which there are more elements than processors.
就是上面的例子有 16 个数字,所以总共循环 次,分别是+1位,+2位,+4 位,+8 位的元素相加,那对于每个 block 就是循环 次,然后这里的每一根坚线就是一个 thread,要去判断处于第几次循环的时候加什么,然后输出最右边的那根 thread 对应的值。
cache = cuda.shared.array(TPB, numba.float32)
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
local_i = cuda.threadIdx.x
# FILL ME IN (roughly 12 lines)
cache[local_i] = 0.
cuda.syncthreads()
if (i < size):
cache[local_i] = a[i]
cuda.syncthreads()
ix = 1
while (ix != TPB):#ix can only reach TPB//2
if local_i % (ix*2) == 0:
cache[local_i] = cache[local_i] + cache[local_i + ix]
ix *= 2
out[cuda.blockIdx.x] = cache[0]这里同样也是有 2 个 test,第二个有两个 block。
ansformer 的长度外推能力的相关工作,其中包含了一个简单但强大的基线方案,以及若干篇聚焦于长度外推性的相关工作,从中我们可以发现,这些工作本质上都是基线方案——局部注意力的变体,局部注意力是长度外推的关键环节之一。
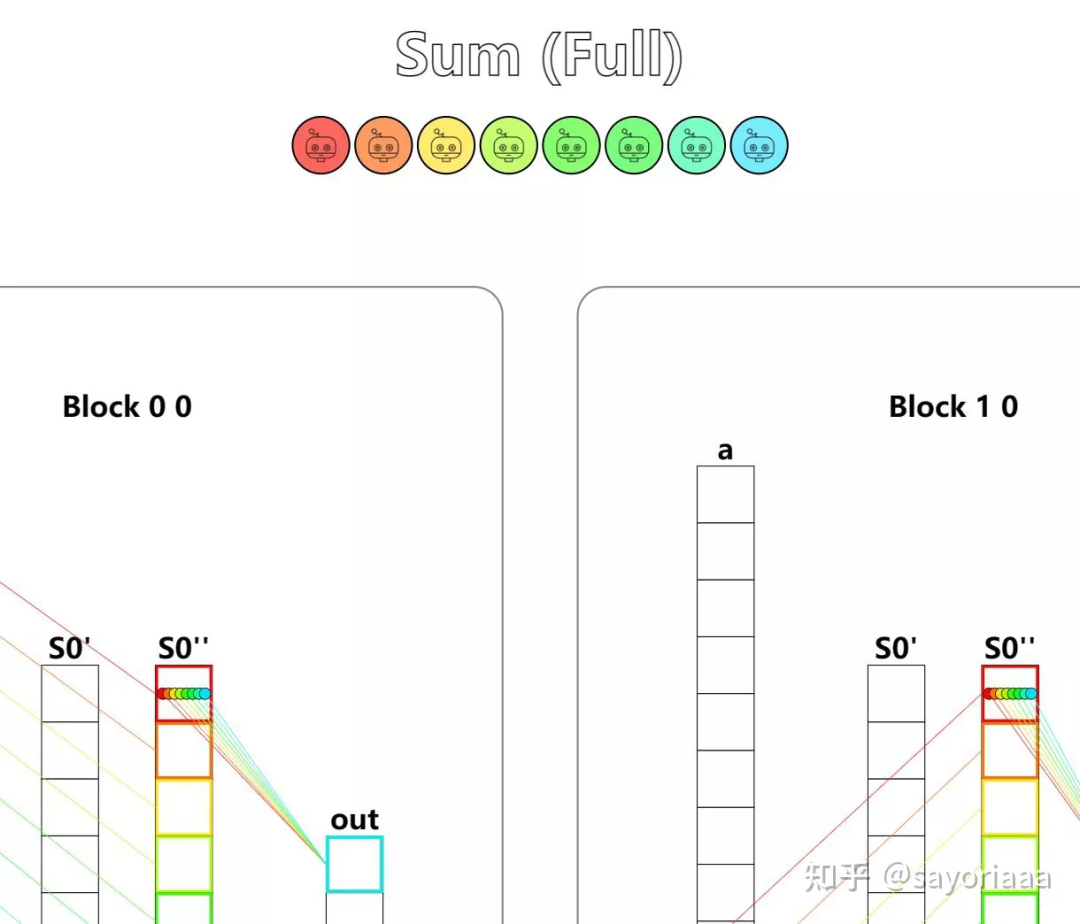
第十三题 - Axis Sum
Implement a kernel that computes a sum over each column of a and stores it in out.
求累加。。。点乘那题不会诶,等等前一题提示了耶,感谢,那之前的点乘那题也可以做了,这里都套一下。
cache = cuda.shared.array(TPB, numba.float32)
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
local_i = cuda.threadIdx.x
batch = cuda.blockIdx.y
# FILL ME IN (roughly 12 lines)
if local_i < size:
cache[local_i] = a[batch, local_i]
cuda.syncthreads()
ix = 1
while (ix != TPB):
if local_i % (ix*2) == 0:
cache[local_i] = cache[local_i] + cache[local_i + ix]
ix *= 2
out[batch, 0] = cache[0]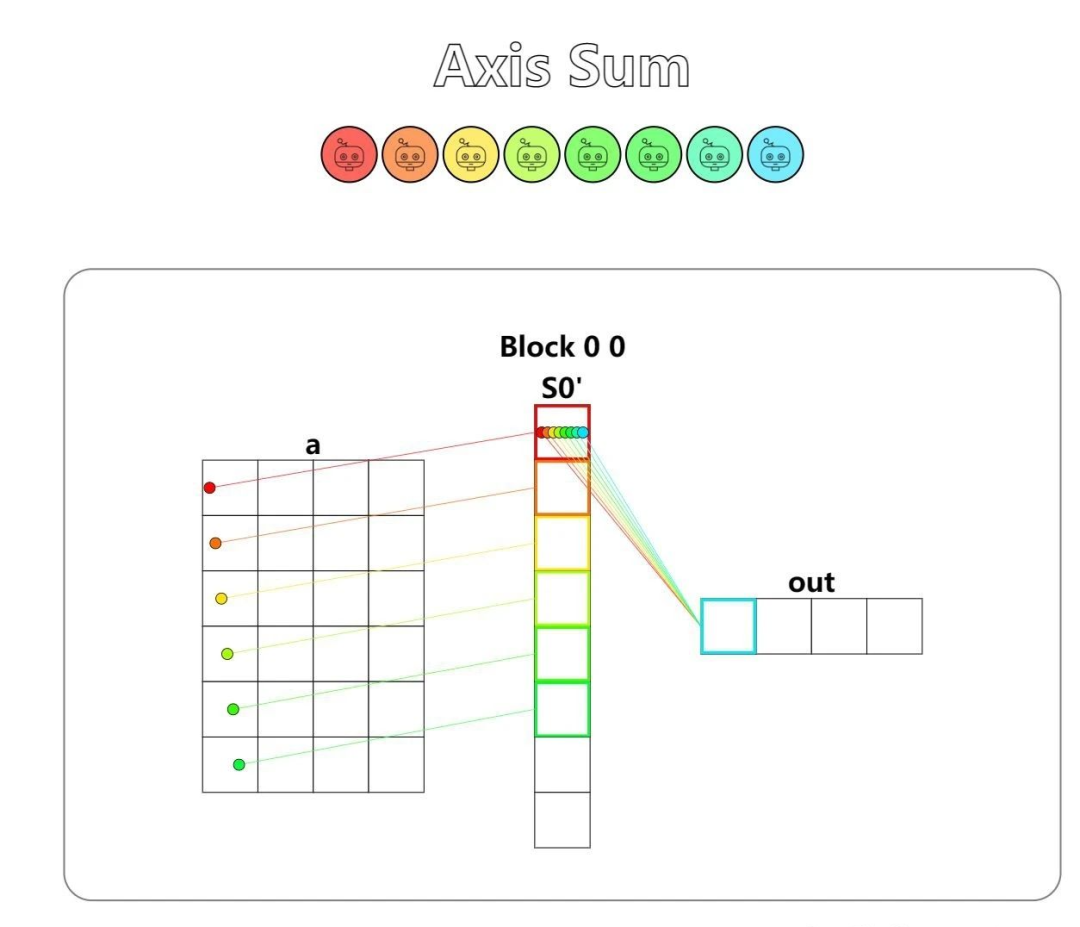
第十四题 - Matrix Multiply!
Implement a kernel that multiplies square matrices a and b and stores the result in out.
Tip: The most efficient algorithm here will copy a block into shared memory before computing each of the individual row-column dot products. This is easy to do if the matrix fits in shared memory. Do that case first. Then update your code to compute a partial dot-product and iteratively move the part you copied into shared memory. You should be able to do the hard case in 6 global reads.
感谢作者,学到了一些东西,除了 CUDA 的一些基本概念外,还有比如数组求和居然还可以有 的算法。
写这个教程的人是好人。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
















 15
15











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









