







 华盛顿大学提出了QLoRA,这是一种针对大语言模型(LLM)的低精度量化和微调技术。QLoRA在保持性能的同时,减少了内存使用,使得在单个48GB GPU上可以微调65B参数模型。QLoRA的核心包括4-bit NormalFloat(NF4)量化、Double Quantization和Paged Optimizers。作者已在huggingface上发布了使用QLoRA训练的Guanaco模型,其中33B和65B模型可以直接使用,且在Vicuna基准测试中表现优秀。
华盛顿大学提出了QLoRA,这是一种针对大语言模型(LLM)的低精度量化和微调技术。QLoRA在保持性能的同时,减少了内存使用,使得在单个48GB GPU上可以微调65B参数模型。QLoRA的核心包括4-bit NormalFloat(NF4)量化、Double Quantization和Paged Optimizers。作者已在huggingface上发布了使用QLoRA训练的Guanaco模型,其中33B和65B模型可以直接使用,且在Vicuna基准测试中表现优秀。

©PaperWeekly 原创 · 作者 | 张洪洋
单位 | 西南财经大学硕士
研究方向 | AIGC

背景
大型语言模型(LLM)的发展日新月异,是近年来自然语言处理(NLP)领域的热门话题,LLM 可以通过大规模的无监督预训练来学习丰富的语言知识,并通过微调来适应不同的下游任务,从而在各种 NLP 任务上取得了令人瞩目的性能。
然而,LLM 也带来了一些挑战,其中一个便是它们的巨大规模和高昂的计算成本。例如,微调 LLaMA 的 65B 模型需要超过 780G 的显存,在 BLOOM-176B 上进行推理,需要 8 个 80GB 的 A100 gpu(每个约 1.5 万美元)。这远远超出了普通用户和研究者的可用资源。虽然最近出现的一些量化方法可以减少 LLM 的内存占用量,但是这些技术仅适用于推理,并不适合在训练过程中使用。因此,如何在保持或提高性能的同时,降低 LLM 的内存占用和训练时间,是一个急需解决的问题。
5 月 24 日华盛顿大学在《QLORA: Efficient Finetuning of Quantized LLMs》这篇文章中提出了一种针对 LLM 的低精度量化和高效微调技术,可以在保证完整的 fp16 的微调任务性能的同时,减少内存使用,从而能够在单个 48GB 显存的 GPU 上微调 65B 参数模型。
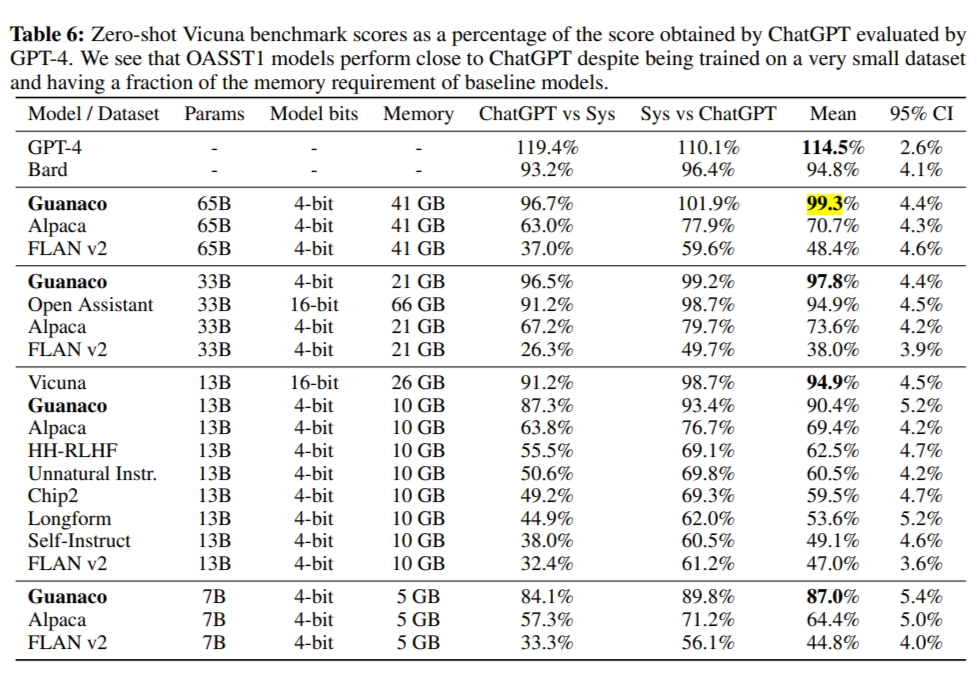
作者 Tim Dettmers 在 huggingface 上已经公布了他们利用 QLoRA 方法训练的系列模型 Guanaco,其中 33b 和 65b 的模型可以直接下载使用,7b 和 13b 的模型需要和对应的 LLaMA 模型进行参数融合。同时作者表明 Guanaco 在 Vicuna 基准测试中的表现超过了所有以前公开发布的模型,在 24 小时内微调的 Guanaco 65B 大模型甚至能够达到 GPT4 性能水平的 99.3%。以下是华盛顿大学的作者所公布的数据:

看到这里相信有很多同学已经按捺不住准备去尝试了,但如果我告诉你只要 5 元就可以在 DB-GPT 上部署自己的 Guanaco 33b 模型呢 🔥 在安全隐私的环境下拥有如此一个强大的模型将对个人知识库将带来怎样的改变?不妨先耐着性子看完以下介绍 😊😊

QLoRA
总的来说 QLoRA 使用一种低精度的存储数据类型(NF4)来压缩预训练的语言模型。通过冻结 LM 参数,将相对少量的可训练参数以 Low-Rank Adapters 的形式添加到模型中,LoRA 层是在训练期间更新的唯一参数,使得模型体量大幅压缩同时推理效果几乎没有受到影响。
QLoRA 的核心技术有三个:4-bit NormalFloat(NF4)量化、Double Quantization 和 Paged Optimizers。QLoRA 的 Q 其实已经很明显的说明了量化(Quantize)技术,所以我们首先简单了解一下量化。
2.1 核心技术
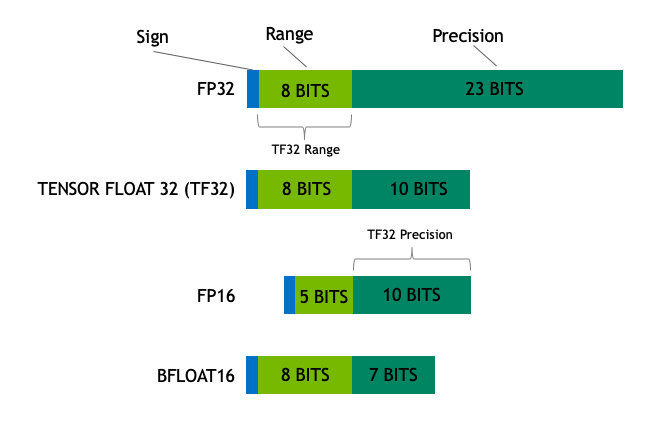
模型的大小通常由其参数的数量及其精度决定,常见的精度有全精度 float32(FP32)、半精度 float16(FP16)和 bfloat16(BF16)、英伟达的 TF32。
FP32:单精度浮点数,用 8bit 表示指数,23bit 表示小数。使用此数据类型,可以表示各种浮点数,并且支持大多硬件。
FP16:半精度浮点数,用 5bit 表示指数,10bit 表示小数。FP16 表示整数范围较小,但是尾数精度较高。
BF16:是对 FP32 单精度浮点数截断数据,用 8bit 表示指数,7bit 表示小数。BF16 可表示的整数范围与 FP32 一样广泛。但只有新的硬件(A100\3090\4090 等)才支持,V100/昇腾910等不支持
TF32:将 BF16 的动态范围和 FP16 的精度相结合,只使用19位。它目前仅在某些操作期间在内部使用。
在 ARM NEON 指令集中,一条指令最多 load 128bit 数据,则对于 FP32 的数据,一次性最多支持 4 个数据的并行计算;对 FP16/BF16 数据,一次性最多支持 8 个数据的并行计算,那么在计算中,FP16/BF16 的性能峰值应该是 FP32 的两倍。
而且,实验表明 FP16/BF16 往往能够在模型大小减半的情况下还能获得和 FP32 模型几乎相同的推理结果,这种惊人的效果吸引着众多研究人员前往更深的领域——FP8、FP4、FP2、FP1。许多量化的技术也逐渐引入了大模型的研究中。
2.1.1 LLM.int8 量化
量化的本质实际是从一种数据类型舍入到另一种数据类型,通常包含量化和反量化两步,假如我们有两组数据类型 A、B,A 可以表示的数值为 [0, 1, 2, 3, 4, 5],B 可以表示的数值为 [0, 2, 4]。我们要做的便是:
将数据范围从 A 标准化为 B。数据类型 A 表示的向量为 [3, 1, 2, 3]。
找到向量 [3, 1, 2, 3] 的最大绝对值 3
向量 [3, 1, 2, 3] 除以最大值 3:[3, 1, 2, 3]->[1, 0.33, 0.66, 1.0]
将向量 [1, 0.33, 0.66, 1.0] 与 B 的数据范围 4 相乘:[1, 0.33, 0.66, 1.0]->[4.0, 1.33, 2.66, 4.0]
将向量 [4.0, 1.33, 2.66, 4.0] 中的每个值用 B 中最接近的数值表示:[4.0, 1.33, 2.66, 4.0] -> [4, 0, 2, 4]。
用 B 中最接近的数值表示 A 。
[4, 0, 2, 4] 除以 4->[1.0, 0.0, 0.5, 1.0]
乘以量化过程中找到的最大的绝对值:[1.0, 0.0, 0.5, 1.0] -> [3.0, 0.0, 1.5, 3.0]
近似表示:[3.0, 0.0, 1.5, 3.0] -> [3, 0, 2, 3]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









