







大型语言模型(LLMs)逐渐成为自然语言处理(NLP)中的常态,并在生成和推理任务中展现出良好的性能。然而其最致命的缺点之一是生成的内容缺乏事实正确性。思维链(CoT)[1] 通过生成可解释的推理链,进一步在复杂的推理任务中提高了模型性能,但在知识密集型任务中仍存在事实性错误问题。
在本文中,我们提出了自查纠错(Verify-and-Edit)框架,通过根据外部知识对推理链进行准确性检验和后期编辑,以提高模型的任务性能。我们的框架基于 GPT-3 构建,并在多个开放域的问答任务中提高了准确性。

论文标题:
Verify-and-Edit: A Knowledge-Enhanced Chain-of-Thought Framework
收录会议:
ACL 2023
论文链接:
https://aclanthology.org/2023.acl-long.320.pdf
数据代码:
https://github.com/RuochenZhao/Verify-and-Edit
作者:
赵若辰*,李星漩*,秦成伟,邴立东等(*为共同一作)

问题定义
大型语言模型(LLMs)逐渐成为许多自然语言处理任务中的新常客。思维链也被广泛应用,通过生成可解释的推理链以提高 LLMs 解决复杂推理任务(如数学问题、常识推理和符号推理)的性能 [2]。
然而 LLMs 最致命的缺点之一是无法确保生成内容的事实正确性。尤其在使用思维链时,如果推理链中出现了事实错误内容,最终的答案大概率也是错误的。即便像 ChatGPT 一样表现优异的大模型也将“虚构事实”标记为其 API 使用中的主要警告。由于 LLMs 的一个主要应用场景是替代传统搜索引擎,并通过问答的方式提供更直接的信息访问,事实错误问题会大大削弱它们的有效性并降低用户对其的信任。
针对上面的问题,我们提出了自查纠错(Verify-and-Edit)框架,通过利用外部知识对推理链进行准确性验证和后期编辑来提高 LLMs 在复杂事实性推理任务上的性能。VE 框架模拟了人类的推理过程:当人们在回答问题时,如果他/她不确定如何回答,会在给出最终答案前搜索知识来帮助他给出最终的答案。因此,VE 框架包含了三个不同的阶段:识别大模型不确定的答案,然后通过搜索知识来编辑推理链,最后使用编辑后的推理链生成最终的答案。
在推理链(CoT)领域,VE 框架是最先几个通过后期编辑推理链来提升任务性能的工作之一。
我们的方法在多个开放域知识密集型问答任务和事实验证任务中取得了显著的提升。

自查纠错(VE)框架
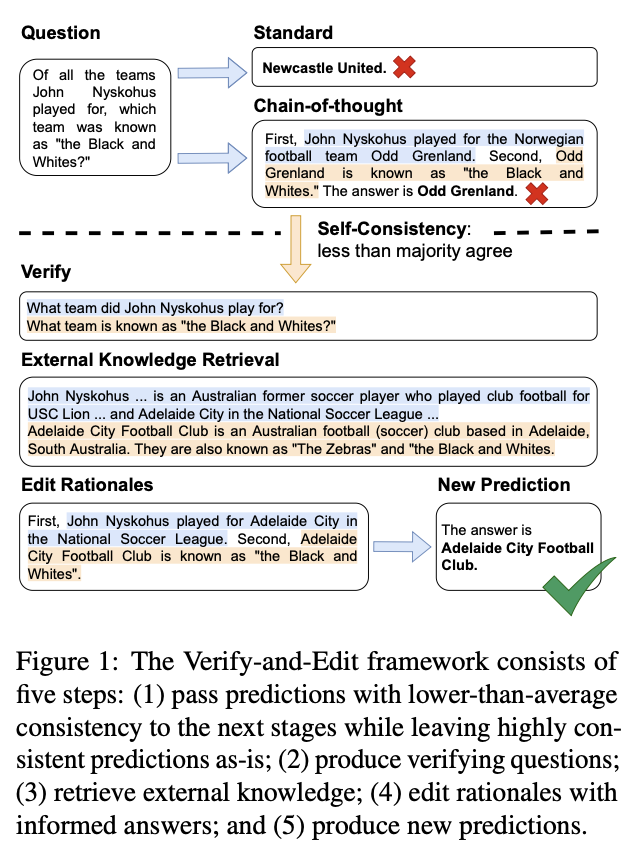
如图一所示,VE 框架包含了五个步骤。首先,我们利用自一致性方法 [3],通过对多条推理路径和答案的采样,对 LLMs 的回答进行不确定性评估。当回答的一致性低于一半,即大多数回答无法就同一个答案达成一致时,我们将其标记为“不确定”回答并进行后续步骤。如一致性超过一半则直接输出答案。
对于“不确定”回答,我们选择出现次数最多的回答进行后期编辑。当人们在搜索相关知识时,往往会提出一个问题去查找答案,我们也模拟这种自然的方式进行知识查找。如图一所示,当我们要验证 “John Nyskohus 曾经为挪威足球队 Odd Grenland 效力”时,我们先用 LLMs 生成一个验证问题 “John Nyskohus 曾经为哪些球队效力过?”根据验证问题,我们利用外部知识检索系统获取与验证问题相关的内容。
在该论文中,我们分别基于三种不同的知识检索系统进行了实验,包括 DrQA(开放域问答系统)、Wikipedia(维基百科内相关知识)和 Google(谷歌搜索内容片段)。由于获取的内容通常很冗长并且包含许多无关信息,我们利用 LLMs 从内容中进一步提炼出一句话以概括获取的内容。比如图一中验证问题 “John Nyskohus 曾经为哪些球队效力过?”的一句话概括回答为 “John Nyskohus 曾经在 National Soccer League 的 Adelaide City 球队效力。”
在对每一条推理链进行上述操作后,我们最后利用 LLMs 从最终后期编辑过后的推理链中推理得到最终答案。

实验结果
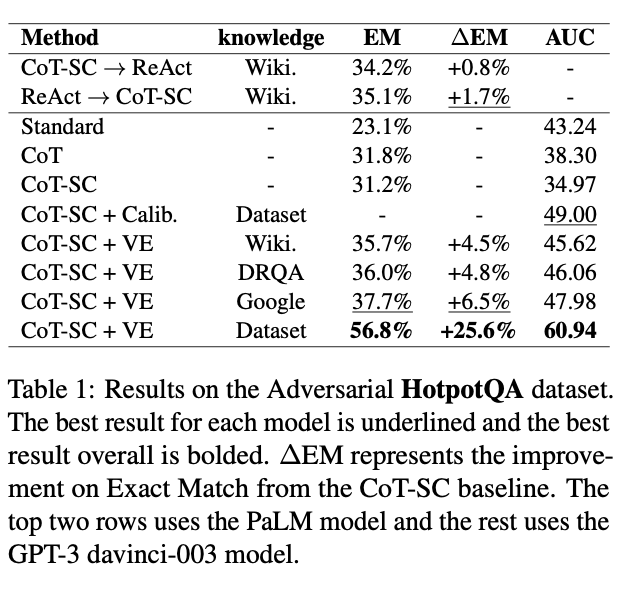
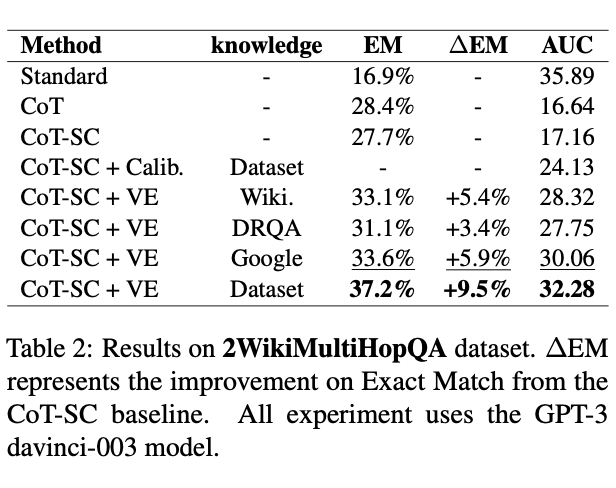
我们分别在开放域知识密集型问答任务和事实验证任务上做了大量实验。对比思维链方法,VE 框架在 HotpotQA 和 2WikiMultiHopQA 上分别有 5.27% 和 4.9% 的提升。同时我们发现,当外部知识不包含无关知识时,VE 框架的表现有平均 17.5% 的显著提升。这表明,如果我们能够始终从外部检索系统中获得与问题最相关的知识,就能够获得更大的提升。在后续的工作中,我们进一步验证了这一结果,并解决了相关问题 [4]。
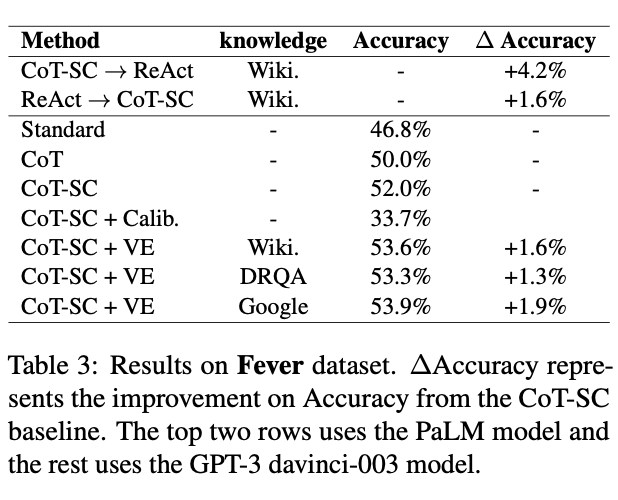
在事实验证任务 Fever 上,尽管不需要多跳推理过程,VE 框架仍然有平均 1.6% 的稳定准确率提升。

人为评估推理链
为了进一步验证由 VE 框架后期编辑后的推理链在事实正确性上有显著的提升,我们邀请了两位志愿者进行小规模的人为评估编辑前后的推理链。如表四所示,53% 的情况下由 VE 框架编辑后的推理链比编辑前更好,另外 30% 的情况中志愿者认为编辑前后的推理链质量相似。

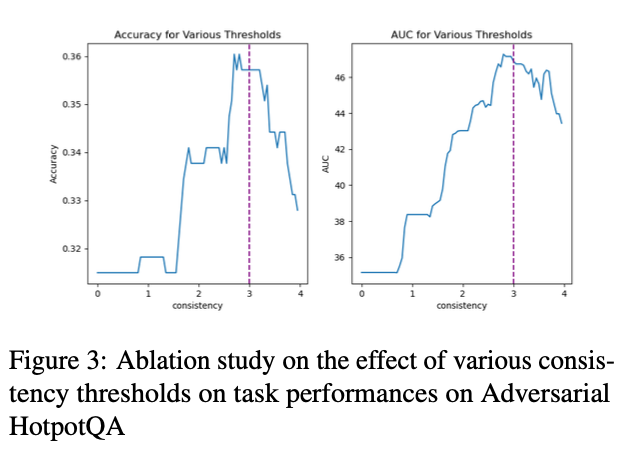
自一致性方法临界值的选择
VE 框架中唯一需要调整的超参为自一致性方法的临界值。如图三所示,当临界值为 ceil(n/2) 时,VE 框架的表现最好。因为当多数的回答一致时,编辑前的答案有更大概率是正确的,而此时编辑推理链有引入无关信息从而把正确答案改错的风险。因此 ceil(n/2) 是更合理的临界值选择。
更多分析请参考原文。

总结
在这项工作中,我们提出了自查纠错(VE)框架,通过利用外部知识对推理链进行准确性验证和后期编辑来提高 LLMs 在复杂事实性推理任务上的性能。VE 框架包含了三个不同的阶段:寻找不确定答案的预测,然后通过搜索知识来编辑推理链,最后使用编辑后的推理链生成最终的答案。我们的方法在多个开放域知识密集型问答任务和事实验证任务中取得了显著的提升。

参考文献
[1] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
[2] Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided language Models.
[3] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[4] Xingxuan Li, Ruochen Zhao, Yew Ken Chia, Bosheng Ding, Lidong Bing, Shafiq Joty, and Soujanya Poria. 2023. Chain of Knowledge: A Framework for Grounding Large Language Models with Structured Knowledge Bases. arXiv preprint arXiv:2305.13269.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









