







©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
目前在 LLM 中最流行的 Tokenizer(分词器)应该是 Google 的 SentencePiece [1] 了,因为它符合 Tokenizer 的一些理想特性,比如语言无关、数据驱动等,并且由于它是 C++ 写的,所以 Tokenize(分词)的速度很快,非常适合追求效率的场景。然而,它也有一些明显的缺点,比如训练速度慢(BPE 算法)、占用内存大等,同时也正因为它是 C++ 写的,对于多数用户来说它就是黑箱,也不方便研究和二次开发。
事实上,Tokenizer的训练就相当于以往的“新词发现”,而笔者之前也写过中文分词和最小熵系列文章,对新词发现也有一定的积累,所以很早之前就有自己写一版 Tokenizer 的想法。这几天总算腾出了时间初步完成了这件事情,东施效颦 SentencePiece,命名为“BytePiece”。
Github:
https://github.com/bojone/bytepiece

理想特性
既然要重写 Tokenizer,那么我们就要思考一个理想的 Tokenizer 应该是怎样的,这样才能判断最终是否达到了预期。照笔者看来,Tokenizer 至少应该具备如下基本特性:
1. 无损重构:分词结果应该可以无损还原为输入;
2. 高压缩率:词表大小相同时,同一批数据的 tokens 数应该尽可能少;
3. 语言无关:基于统计,训练和分词过程都不应引入语言特性;
4. 数据驱动:可以直接基于原始语料进行无监督训练;
5. 训练友好:能够在合理的时间和配置上完成训练过程。
最后,还有一些加分项,比如分词速度快、代码易读、方便二次拓展等,这些满足自然最好,但笔者认为可以不列入基本特性里边。
对于笔者来说,SentencePiece 最大的槽点就是“无损重构”和“训练友好”。首先,SentencePiece 默认会进行 NFKC normalization [2],这会导致“全角逗号转半角逗号”等不可逆变化,所以默认情况下它连“无损重构”都不满足,所以很长时间里它都不在笔者的候选名单中,直到后来发现,在训练时添加参数 --normalization_rule_name=identity 就可以让它不做任何转换。所以 SentencePiece 算是支持无损重构,只不过要特别设置。
至于训练方面,就更让人抓狂了。SentencePiece 支持 BPE 和 Unigram 两种主流算法,Unigram 训练速度尚可,但压缩率会稍低一些,BPE 的压缩率更高,但是训练速度要比 Unigram 慢上一个数量级!而且不管是 BPE 还是 Unigram,训练过程都极费内存。总而言之,用较大的语料去训练一个 SentencePiece 模型真不是一种好的体验。

模型构思
一个新 Tokenizer 的构建,可以分解为三个部分:1)基本单元;2)分词算法;3)训练算法。确定这三个部分后,剩下的就只是编程技巧问题了。下面逐一介绍 BytePiece 对这些问题的思考。
2.1 基本单元
我们知道,Python3 的默认字符串类型是 Unicode,如果以 Unicode 为基本单位,我们称之为 Char-based。Char-based 很直观方便,汉字表现为长度为 1 的单个字符,但不同语言的 Char 实在太多,即便只是覆盖单字都需要消耗非常大的 vocab_size,更不用说引入 Word。所以 BytePiece 跟主流的 Tokenizer 一样,以 Byte 为基本单位。
回到 Byte 之后,很多问题都“豁然开朗”了。因为不同的单 Byte 只有 256 个,所以只要词表里包含了这 256 个单 Byte,那么就可以杜绝 OOV(Out of Vocabulary),这是它显而易见的好处。此外,我们知道汉字的平均信息熵要比英文字母的平均信息熵要大,如果我们选择 Char-based,那么虽然每个 Char 表面看起来长度都是 1,但“内在”的颗粒度不一样,这会导致统计结果有所偏置。
相比之下,每个 Byte 的信息熵则更加均匀【比如,大部分汉字的 UTF-8 编码对应 3 个 Byte,而汉字的平均信息熵正好是英文字母(对应一个 Byte)的 2~3 倍左右】,因此用 Byte 的统计结果会更加无偏,这将会使得模型更加“语言无关”。
在 Byte-based 方面,BytePiece 比 SentencePiece 更彻底,SentencePiece 是先以 Char-based 进行处理,然后遇到 OOV 再以 Byte-based 处理,BytePiece 则是在一开始就将文本通过 text.encode() 转为 Bytes,然后才进行后续操作,相比之下更加纯粹。
2.2 分词算法
基于词典进行分词的算法无非就那几种,比如最大匹配、最短路径、最大概率路径等,有兴趣追溯的读者,可以参考 Matrix67 之前写的《漫话中文自动分词和语义识别(上):中文分词算法》[3]。
跟 jieba 等中文分词工具一样,BytePiece 选择的是最大概率路径分词,也称“一元文法模型”,即 Unigram。选择 Unigram 有两方面的考虑。第一,Unigram 的最大概率换言之就是最大似然,而 LLM 的训练目标也是最大似然,两者更加一致;第二,从压缩的角度看,最大概率实际上就是最短编码长度(也叫最小描述长度),是压缩率最大化的体现,这也跟“压缩就是智能”的信仰一致。
当然,既然有“一元文法模型”,自然也有更复杂的“二元文法模型”、“三元文法模型”等,但它们的复杂度增加远大于它能带来的收益,所以我们通常不考虑这些高阶模型。
2.3 训练算法
之所以先讨论分词算法在讨论训练算法,是因为只有分词算法确定下来后,才能确定训练的优化目标,从而研究对应的训练算法。
开头就提到,Tokenizer 的训练本质上就是以往的“新词发现”,而笔者之前也提了好几种新词发现算法,如《基于切分的新词发现》[4]、《基于语言模型的无监督分词》[5]、《更好的新词发现算法》[6]。现在看来,跟 Unigram 分词算法最契合、最有潜力的,应该是《基于语言模型的无监督分词》[5],BytePiece 的训练就是基于它实现的,这里称之为 Byte-based N-gram Language Model(BNLM)。
具体来说,对于 Unigram 分词,如果一个长度为 l 的字节串 ,最优分词结果为 ,那么概率乘积 应该是所有切分中最大的。设 的长度分别为 ,那么根据条件分解公式:
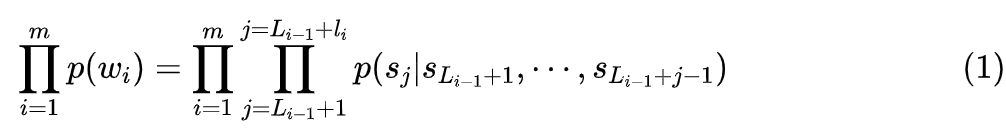
这里 。只考虑 n-gram 模型,将 的 统一用 近似,那么 Unigram 分词就转化为一个字(节)标注问题,而 Tokenizer 的训练则转化为 n-gram 语言模型的训练(推荐 n=6),可以直接无监督完成。更详细的介绍请读者移步原文《基于语言模型的无监督分词》[5]。

代码实现
原理确定之后,剩下的就是枯燥的开发工作了。幸不辱命,勉强写出了一套可用的代码:
Github:
https://github.com/bojone/bytepiece
代码很简单,单文件,里边就 Trainer 和 Tokenizer 两个类,分别对应分词两部分。分词借助 pyahocorasick [7] 来构建 AC 自动机来稍微提了一下速,能凑合用,但还是会比 SentencePiece 慢不少,毕竟速度方面纯 Python 跟 C++ 确实没法比。
训练则分为四个主要步骤:1)n-gram 计数;2)n-gram 剪枝;3)预分词;4)预分词结果剪枝。其中 1、3、4 都是计算密集型,并且都是可并行的,所以编写了相应的多进程实现。在开足够多的进程(笔者开了 64 进程,每个进程的使用率基本上都是满的)下,训练速度能媲美 SentencePiece 的 Unigram 训练速度。
这里特别要提一下结果剪枝方面。剪枝最基本的依据自然是频数和 vocab_size,但这还不够,因为有时候会出现 ( 指两个词拼接)且 三个词都在词表中,这种情况下 这个词永远不会切分出来,所以将它放在词表中是纯粹浪费空间的,因此剪枝过程也包含了这类结果的排除。

效果测试
到了大家喜闻乐见的测试环节,是骡子是马总要拉出来遛遛。首先做个小规模的测试,从悟道之前开源的数据集里边随机采样 10 万条作为训练集(导出来的文件大概 330MB),然后另外采样 1 千作为测试集,训练一个 vocab_size=50k 的词表,结果对比如下:
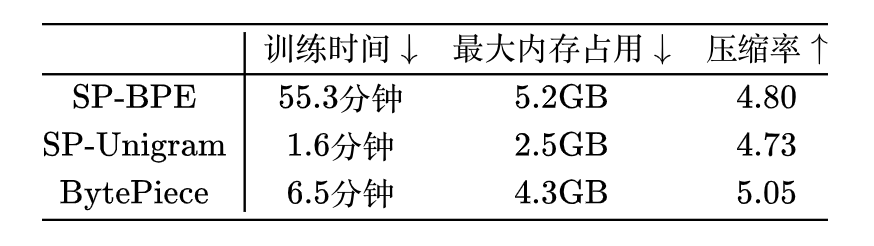
解释一下,这里 SP-BPE、SP-Unigram 分别指 SentencePiece 的 model_type 设为 BPE 和 Unigram,训练代码分别是:
spm.SentencePieceTrainer.train('--input=wudao.txt --model_prefix=wudao_m --vocab_size=50000 --model_type=bpe --train_extremely_large_corpus=true --normalization_rule_name=identity')
spm.SentencePieceTrainer.train('--input=wudao.txt --model_prefix=wudao_m2 --vocab_size=50000 --model_type=unigram --train_extremely_large_corpus=true --normalization_rule_name=identity')压缩率的单位是“bytes/token”,即平均每个 token 对应的字节数。可见,BytePiece能够在训练时间和内存都比较折中的情况下,获得最大的压缩率。
接下来进行一个更大规模的测试。从中英比例大致为 3:5 的混合语料库中,抽取出 10 万条样本训练 vocab_size=100k 的 Tokenizer。这个语料库的文本都比较长,所以这时候 10 万条导出来的文件已经 13GB 了,测试集包含两部分,一部分是同样的语料库中采样出 1000 条(即同源),另一部分是刚才采样出来的 1000 条悟道数据集(代表不同源)。结果如下:

不管是训练时间、内存还是压缩率,看起来训练数据量越大,BytePiece 越有优势!

未完待续
就目前的结果看来,BytePiece 在训练方面是有一定优势的,分词效果也尚可,不过吃了纯 Python 的亏,分词速度只有 SentencePiece 的 1/10 左右,这是未来的一个优化方向之一,期待有 C/C++ 大牛能参与进来,帮助提升 BytePiece 的分词速度。
实际上,如果采用随机采样、动态剪枝等技术,BytePiece 的训练速度和内存都还可以进一步优化。目前 BytePiece 为了保证结果的确定性,直到所有结果都统计完毕才进行剪枝,这样不管是单进程还是多进程,都能保证结果的一致性。如果随机打乱输入,并且定时进行剪枝,那么可以进一步控制内存的占用量,同时还能加快统计速度,并且可以预期对最终效果的影响也不大。这部分工作,也在后面根据用户体验进一步引入。
除了以上这些,BytePiece 细节之处还有不少需要完善的地方,以及可能还有未发现的错漏之处,敬请大家海涵且反馈。

文章小结
本文介绍了笔者自行开发的 Tokenizer——BytePiece,它是 Byte-based 的 Unigram 分词器,纯 Python 实现,更加易读和易拓展。由于采用了新的训练算法,所以压缩率通常比现有 tokenizer 更高,同时支持多进程加速训练。此外,它直接操作文本的 utf-8 bytes,几乎不进行任何的预处理,所以更加纯粹和语言无关。

参考文献
[1] https://github.com/google/sentencepiece
[2] https://github.com/google/sentencepiece/blob/master/doc/normalization.md
[3] http://www.matrix67.com/blog/archives/4212
[4] https://kexue.fm/archives/3913
[5] https://kexue.fm/archives/3956
[6] https://kexue.fm/archives/4256
[7] https://github.com/WojciechMula/pyahocorasick
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









