




 本文探讨了随机梯度下降(SGD)的收敛性,通过一个基础的收敛结论展示了SGD在适当条件下能逼近损失函数的最小值。分析了常数学习率和衰减学习率两种策略,并指出理论分析通常基于强假设,如损失函数的凸性和梯度的有界性。证明过程中引入了投影操作以确保迭代结果的有界性,并总结了整个证明过程所需的假设。
本文探讨了随机梯度下降(SGD)的收敛性,通过一个基础的收敛结论展示了SGD在适当条件下能逼近损失函数的最小值。分析了常数学习率和衰减学习率两种策略,并指出理论分析通常基于强假设,如损失函数的凸性和梯度的有界性。证明过程中引入了投影操作以确保迭代结果的有界性,并总结了整个证明过程所需的假设。

©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 月之暗面
研究方向 | NLP、神经网络
很多时候我们将深度学习模型的训练过程戏称为“炼丹”,因为整个过程跟古代的炼丹术一样,看上去有一定的科学依据,但整体却给人一种“玄之又玄”的感觉。尽管本站之前也关注过一些优化器相关的工作,甚至也写过《从动力学角度看优化算法》系列,但都是比较表面的介绍,并没有涉及到更深入的理论。为了让以后的炼丹更科学一些,笔者决定去补习一些优化相关的理论结果,争取让炼丹之路多点理论支撑。
在本文中,我们将学习随机梯度下降(SGD)的一个非常基础的收敛结论。虽然现在看来,该结论显得很粗糙且不实用,但它是优化器收敛性证明的一次非常重要的尝试,特别是它考虑了我们实际使用的是随机梯度下降(SGD)而不是全量梯度下降(GD)这一特性,使得结论更加具有参考意义。

问题设置
设损失函数是 ,其实 是训练集,而 是训练参数。受限于算力,我们通常只能执行随机梯度下降(SGD),即每步只能采样一个训练子集来计算损失函数并更新参数,假设采样是独立同分布的,第 t 步采样到的子集为 ,那么我们可以合理地认为实际优化的最终目标是
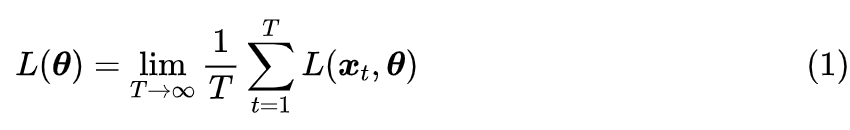
实际情况下,我们也只能训练有限步,所以我们假设 T 是一个足够大的正整常数。我们的目标是寻找 的最小值点,即希望找到 :

现在,我们考虑如下 SGD 迭代:

其中 是学习率,其中 是 关于 的梯度。我们的任务就是分析如此迭代下去, 是否能够收敛到到目标点 。

结论初探
首先,我们给出最终要证明的不等式:在适当的假设之下,有
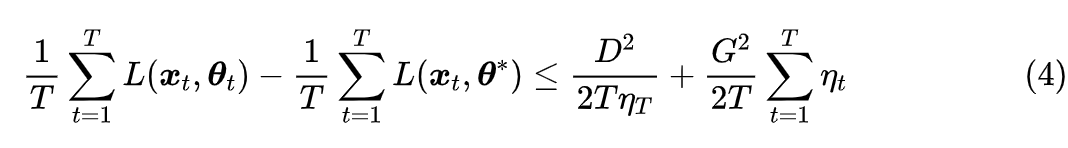
其中 D,G 是跟优化过程无关的常数。后面我们会逐一介绍“适当的假设”具体是什么,在此之前我们先来观察一下不等式(4)所表达的具体含义:
1. 左端第一项,是优化过程中每一步的损失函数的平均结果;
2. 左端第二项,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









