








在迈向通用大原子模型(Large Atomic Model,LAM)的征途上,深度势能核心开发者团队面向社区,发起 OpenLAM 大原子模型计划。OpenLAM 的口号是“征服元素周期表!”,希望通过建立开源开放的围绕微尺度大模型的生态,为微观科学研究提供新的基础设施,并推动材料、能源、生物制药等领域微尺度工业设计的变革。

经过北京科学智能研究院、深势科技、北京应用物理与计算数学研究所等 29 家单位的 42 位合作者的通力协作,深度势能团队近日面向社区发布了深度势能预训练大模型 DPA-2,将成为 OpenLAM 大原子模型计划的重要载体。基于 DPA-2 的微调/蒸馏/应用自动化流程也于同期面向社区全面开放,打通了面向各类实际应用的最后一公里。相关文章[1]以《DPA-2: Towards a universal large atomic model for molecular and material simulation》为题,在arXiv上预发表。

论文链接:
https://arxiv.org/abs/2312.15492
面向丰富的下游任务,微调 DPA-2“大模型”所需的数据量整体相比过去减少了 1-2 个数量级;同时,进一步蒸馏、压缩得到的深度势能“小模型”可以保持过去模型的精度和效率。相比于去年发布的 DPA-1,DPA-2 在模型架构显著更新的同时,最大的特点在于采用了多任务训练的策略,从而可以同时学习计算设置不同、标签类型不同的各类数据集。由此产生的模型在下游任务上显示出极强的 few-shot 乃至 zero-shot 迁移的能力,显著超越过去的方案。目前用于训练 DPA-2 模型的数据集已覆盖了半导体、钙钛矿、合金、表面催化、正极材料、固态电解质、有机分子等多类体系。
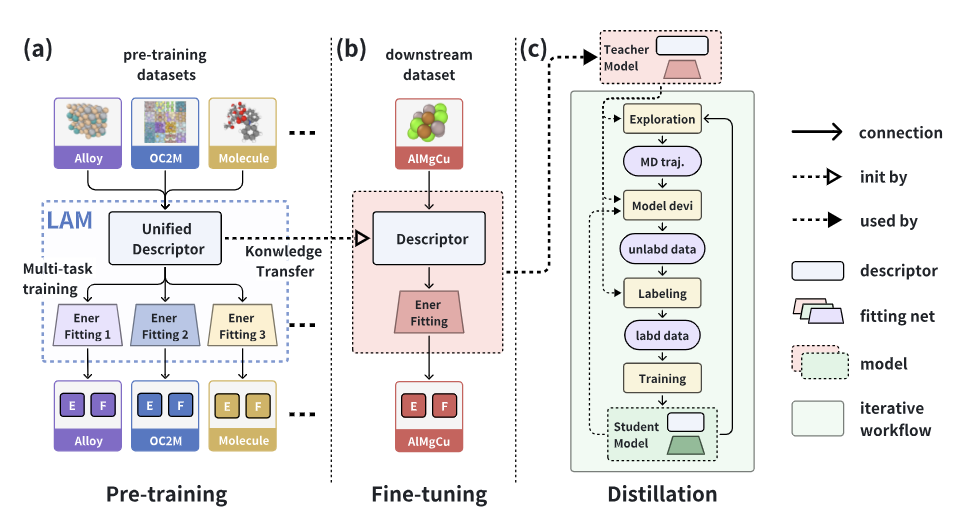
图1 DPA-2 提出的多任务预训练、微调、蒸馏全流程示意图
“大原子模型计划(OpenLAM)”为进一步打破数据壁垒,拓宽原子层面各方面的应用,为开源开放的科学计算生态共建打开了新的思路。作为一项开放式的协作计划,建立一个开放且面向应用的模型评估系统也格外重要。面向社区该计划将定期进行模型更新与评估报告发布、定期更新发布领域应用与评估工作流,同时开展比赛、培训交流,与领域开发者协作推动建立供预训练与评估的数据集等。这将是 OpenLAM 计划在 2024 年的重点。
感兴趣的读者,欢迎通过以下 Bohrium Notebook 链接快速上手 DPA-2,也欢迎使用 DP Combo@Bohrium APP 更加深入系统地产生你需要的势函数!

Notebook链接
https://nb.bohrium.dp.tech/detail/18475433825
以下为关于 DPA-2 的详细介绍。

DPA-2 项目背景

机器学习势函数在材料科学、计算物理等领域应用广泛,并取得了较大成果。然而,面对一个新的复杂体系,要获得可用的、较为完备的势函数模型,科学家们基本上仍然需要获取大量计算数据并从头开始训练模型。随着电子结构数据的积累,开始有工作关注“通用”的势能函数模型,比如 DPA-1,Gemnet-OC,Equiformer-V2,M3GNet 等,并有部分工作将其应用到“预训练+微调”的范式上来,从而节省新体系的数据生产成本。
但是这些模型还没有做到通用,主要有以下几方面的问题:
(1)模型要求产生预训练数据的方式(比如泛函、DFT 计算的参数设置等)必须严格一致,这极大地限制了训练数据的来源范围,使得大部分模型都只能局限在单一数据集或统一生产的数据库中,数据量受到限制,从而也导致模型泛化能力不足。
(2)模型结构本身的迁移能力不足,预训练之后在下游体系上的微调效果有限;
(3)部分模型本身不满足基本的物理性质,比如保守性(即输出受力必须严格是输出能量关于输入坐标的负梯度)、连续性(模型输出必须关于输入二阶连续)等,从而无法用于真正应用体系的模拟中,再加上部分模型参数规模庞大,进一步限制了应用的发展。
要实现真正意义上的 LAM 通用大原子模型,以上的问题是必须要被解决的。

多任务预训练

为此,参考 LLM 的发展理念,在提出新模型结构的同时,DPA-2 首先提出了一套多任务预训练(Multi-task Training)框架,可以在不同标注的数据上同时进行训练,得到统一的预训练模型,如上图1(a)所示。DPA-2 可以通过共享大部分网络参数、不同数据集使用不同 head 的方式,在任意多种来源的数据集上同时进行多任务训练,相比使用单一来源数据训练的模型,极大地扩展了其泛化能力和应用范围。但与此同时,多任务的模型参数量并没有本质的增加,这也导致在训练上可能会更为困难。原文中采用了更为科学的采样训练方式,结果表明多任务模型在不同数据集上的精度,和单独训练的模型精度非常接近甚至更高,这也表明了这种训练方式的可行性。

下游数据集微调

在预训练结束后,文中采用了图1(b)中的方式在下游数据上进行微调。“预训练+微调”范式的核心要求是下游数据集上的迁移能力,即在经过预训练之后,在下游的数据集上,能用尽可能少的数据达到满意的精度。为了测试这一点,文中在各种不同下游数据集上,对 DPA-2 预训练之后的模型进行了迁移能力的测试,部分结果如图2所示:
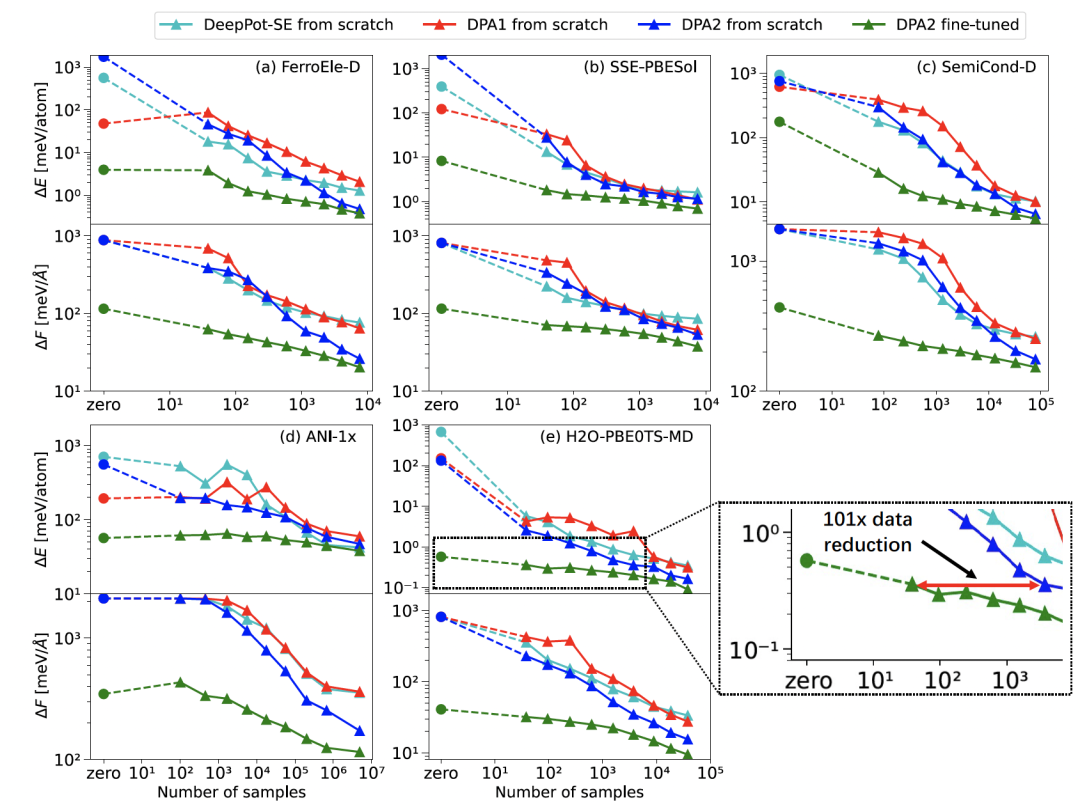
图2 DPA-2 多任务预训练后在下游体系微调的表现
图中横坐标是所用数据量,纵坐标是能量和受力的收敛误差。可以看到,在多任务预训练后,DPA-2 微调代表的深绿色线,要远远低于从头训练的深蓝色线,在大多数体系上,多任务预训练后的模型仅用很少样本(few-shot)、甚至完全不用下游数据(zero-shot)就已经达到了实际应用中可用的精度。平均来看,基于多任务预训练获得的 DPA-2 模型,在各个下游体系能节省 90% 以上的数据。

模型蒸馏和应用测试

为了追求预训练模型框架的泛化能力,模型参数规模肯定会越来越大,从而影响推理性能,导致模型难以被用于真实场景。为了解决这个问题,文中也提出了模型蒸馏的方式,如图1(c)所示。在下游体系上少量数据微调结束后的模型,可以被叫做Teacher模型,用它去教更简单、轻量的Student模型(比如 DPA-1,DeepPot-SE 等),期望能使其在特定下游体系拥有接近 Teacher 模型的精度,同时相比 Teacher Model 有接近两个量级的效率提升,从而可以被用于大规模、高效率的应用模拟中。文中具体采用的是类似主动学习的方式用 Teacher 模型去探索数据空间,并代替量子力学方法来做新数据的标注,从而高效地将知识蒸馏到更简单的 Student 模型中,文中 Teacher 和 Student 的精度对比也证明了蒸馏方案的可行性。
回到势能函数本身,其最终必然是应用导向。为了测试模型的可靠性,文中还在多种体系上进行了实际模拟和性质测试,如图3所示:
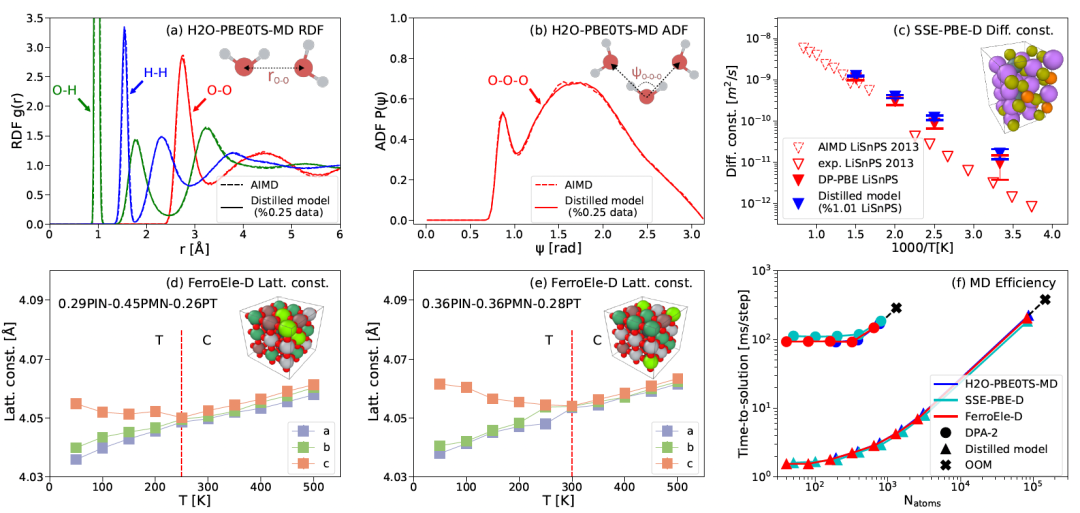
图3 DPA-2蒸馏后的模型在下游体系中的应用测试
上图测试了蒸馏后的模型在水上的径向分布函数(Radial Distribution Function)、固态电解质上的扩散系数(Diffusion Constant)和钙钛矿铁电固溶体上晶格常数(Lattice Constant)随温度的变化等性质的复现。对比原来的模型,使用预训练后微调、蒸馏的方式,在三个体系上分别仅使用了原来 0.25%、1.01% 和 7.86% 的数据,证明了整套流程的可靠性。

其他模型框架的对比

文中还将 DPA-2 的模型结构和其他模型,如 Gemnet-OC (GNO)、Equiformer-V2 (EFV2)、Nequip、Allegro 进行了对比,在传统单数据训练的意义下,公平比较了模型结构本身的能力,如下表所示:
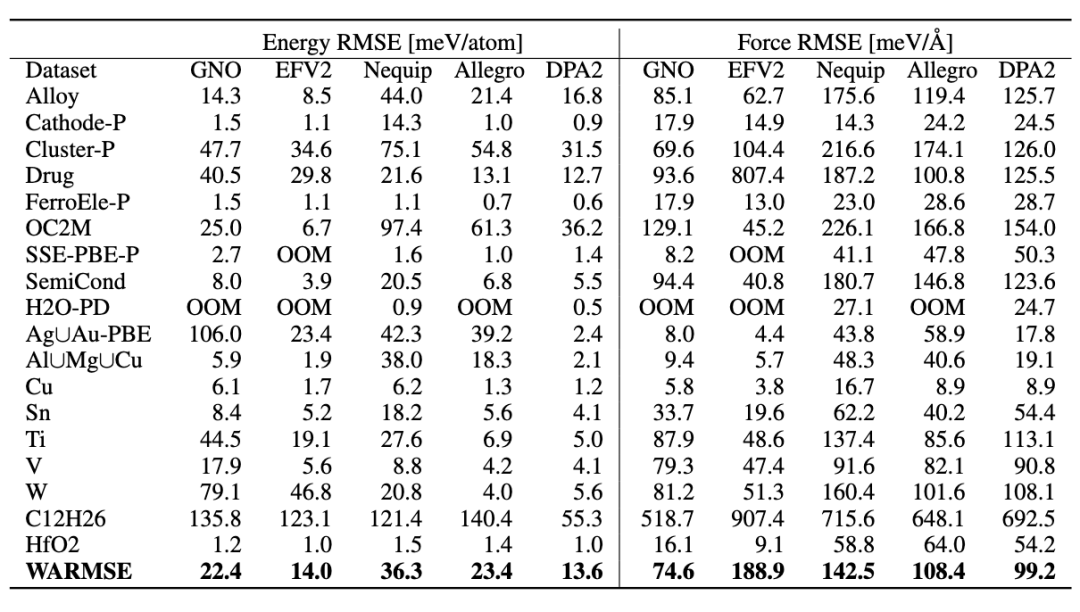
表1 DPA-2 模型结构相比其他模型的精度对比
(batchsize=1, 1 million steps)
可以看到,相比其他模型来说,DPA-2 在各个应用数据集上的表现要更为稳定。

总结

DPA-2 的提出是我们迈向“通用大原子模型”的重要一步。通过在多种数据集上的大规模多任务预训练,DPA-2 在各种下游应用体系展现出显著的迁移能力,极大地减少了所需数据量,从而很大程度上降低数据生产的成本。另一方面,DPA-2 也强调,建立一个开放且面向应用的模型评估系统是非常重要的。
在走向大原子模型时代的过程中,开源开放将是必然的主题。欢迎志同道合的各位加入,开启更广泛科学发现和工业应用的新机遇。在征服元素周期表的路上,期待与你携手共创!
前往加入“大原子模型计划”:https://www.aissquare.com/openlam

参考文献
[1] DPA-2: Towards a universal large atomic model for molecular and material simulation.https://arxiv.org/abs/2312.15492


















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









