








指令数据越来越多,哪些真正应该被用来训练?
每个模型各有优点,如何博采众长为己所用?
PaperWeekly 今天帮大家精读 WizardLM 团队最新论文:Arena Learning,这是一种让 LLM 在模拟竞技场中相互对战,并不断提升的全新的数据飞轮训练算法。

论文标题:
Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena
论文链接:
https://www.microsoft.com/en-us/research/publication/arena-learning-build-data-flywheel-for-llms-post-training-via-simulated-chatbot-arena/

背景
近年来,自然语言处理领域经历了一场显著的变革,这得益于大型语言模型(LLM)经过海量文本数据训练,在各种任务中表现出了理解、生成和与人类语言交互的卓越能力。基于 LLM 的聊天机器人成功的关键因素之一是能够利用大规模高质量指令数据进行有效的 post-training,如 SFT 和 RLHF。
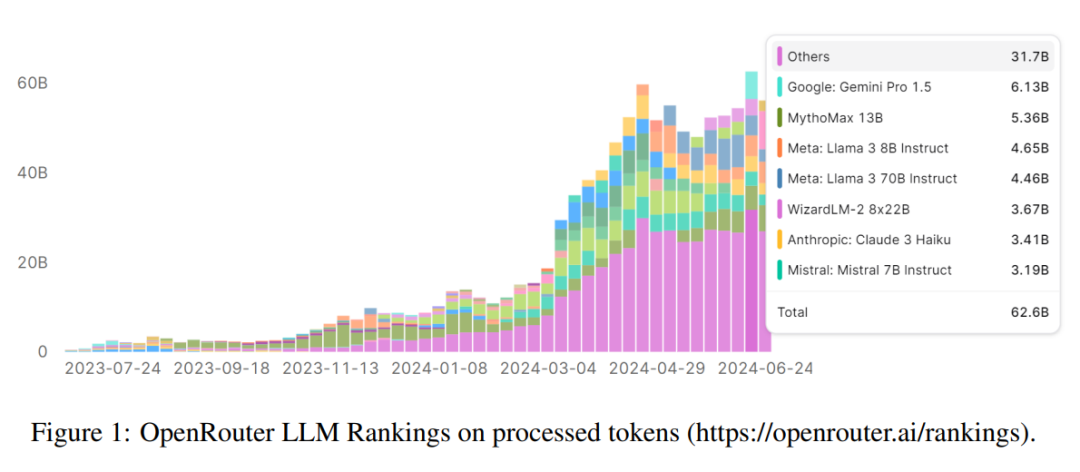
随着各种大模型应用的快速实施和推理成本的降低,企业和消费者对使用大语言模型服务的兴趣和需求迅速增加。如图 1 所示,仅 OpenRouter 平台每天将处理超过 600 亿 token。同时,随着应用场景的创新和深化,这需要 LLM 不断演进以适应用户的新意图和指令。因此,构建高效的数据飞轮,不断收集反馈,查缺补漏,提升模型能力,成为下一代人工智能研究的关键方向。
在此背景下,LMSYS Chatbot Arena 的出现是一个重大进展,它通过让不同聊天机器人模型在一系列对话挑战中相互竞争,利用多样化的人类评估者判定,并使用 Elo 评分系统进行排名。同时,它还开放了一些真实的直接聊天和战斗偏好数据,这些数据已被证明是模型 post-training 和开发指导的宝贵资源。
然而,以人为中心的评估过程也存在自身的挑战:手动安排和等待聊天机器人与人类评估者之间的互动可能非常耗时且昂贵,从而限制了评估和训练数据开源周期的规模和频率。另一方面,由于优先级限制,大多数模型无法参与竞技场评估,开源社区也最多只能获得 10% 的聊天数据,因此很难直接有效地指导基于该竞技场快速开发新模型。因此,对更高效、可扩展的基于竞技场的聊天机器人 post-training 和评估系统的需求变得越来越迫切。
本文提出了一种名为 Arena Learning 的数据飞轮训练技术,可以模拟 Chatbot Arena 的场景,让最先进的 LLM 在大规模指令数据上不断地相互竞技,然后基于 AI 标注的战斗结果进行有监督微调(SFT)或强化学习(RL),以此来不断增强模型:
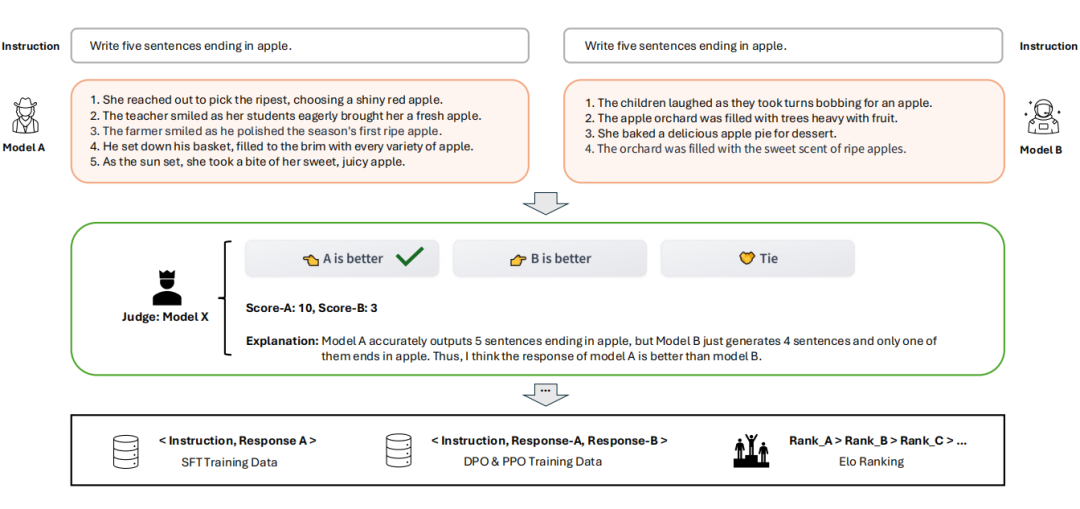
整套全 AI 驱动的数据飞轮实现了“对战-训练-评估-再对战-再训练-再评估”的完美闭环。
特别地,本文还提出了一个新的离线测试集— WizardArena —用于新模型的性能评估及选择,它可以准确地预测模型的 Elo 排名。从其给出的排名结果来看,WizardArena 与 LMSYS Chatbot Arena 的 ranking 结果一致性高达 98.79%,但该模拟竞技场的对战评判效率(等效 16 H100 算力情况下)却实现了高达 40 倍的提升,如下表 2 所示:

最终实验结果表明,基于 Arena Learning 训练的模型 WizardLM-β 在 SFT、DPO 和 PPO 阶段均显著提高了模型性能。

方法
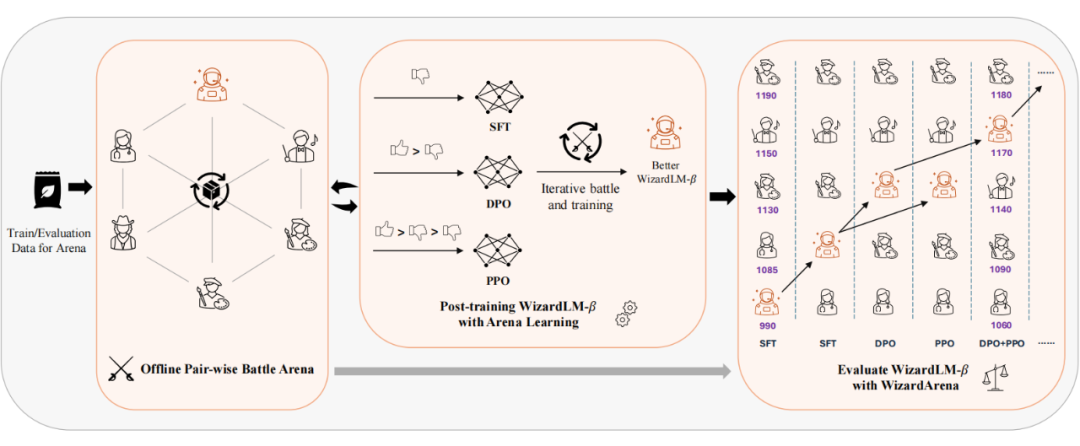
2.1 LLM as Judge
Arena Learning 中构建模拟竞技场战斗的核心是一个强大的 LLM,它充当“裁判模型”。裁判模型的作用是分析和比较配对战斗模型的响应。输入是对话历史、用户指令和两个 LLM 的响应。输出包括每个 LLM 的分数,以及针对各种因素(例如连贯性、事实准确性、上下文意识和整体质量)的解释,以确定一个响应是否优于另一个。
每个模型都会获得 1 到 10 的总体分数,分数越高,整体表现越好。下文在竞技场 post-training 阶段和评估阶段中均使用 Llama-3-70B-Instruct 作为“裁判模型”。
2.2 Data Flywheel
收集大规模指令数据
论文中使用了 276K 数据模拟多阶段的增量飞轮数据。数据收集过程涉及过滤、清理和重复数据删除等几个阶段,以确保指令数据的质量和多样性。本文将数据平均分成几个部分 D = {D_0, D_1, D_2, ..., D_N},分别用于后续迭代训练和更新。然后使用模拟竞技场战斗结果为 WizardLM-β 生成训练数据,并针对不同的训练策略进行定制:监督微调(SFT)、直接偏好优化(DPO)和近端策略优化(PPO)。
迭代式对战与模型进化
Arena Learning 采用迭代过程来训练和改进 WizardLM-β。在每一轮模拟竞技场战斗和训练数据生成之后,WizardLM-β 使用适当的训练策略(SFT,DPO 和/或 PPO)进行更新。然后这个更新的模型被重新引入竞技场,它再次与其他 SOTA 模型战斗。这个迭代过程允许 WizardLM-β 不断改进和适应竞技场的不断变化。随着模型变得越来越强大,模拟战斗也变得越来越具有挑战性,这迫使 Wiz
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









