







©PaperWeekly 原创 · 作者 | 刘潇
单位 | 清华大学
研究方向 | 基础模型,基础智能体

背景:从“基础模型”到“基础智能体”
基础模型,特别是大规模预训练语言模型,展现出超出人们预期的通用能力,可以通过提示(Prompting)和微调(Finetuning)实现在特定语言任务上的良好表现。更令人兴奋的是,通过允许基础模型与真实世界、环境甚至其他模型产生交互,我们发现了这类大模型涌现出作为智能体的潜力。LLM-as-Agent 这一领域也在过去一年多来产生了巨大的进展,成为基础模型研究中的一个重要分支。
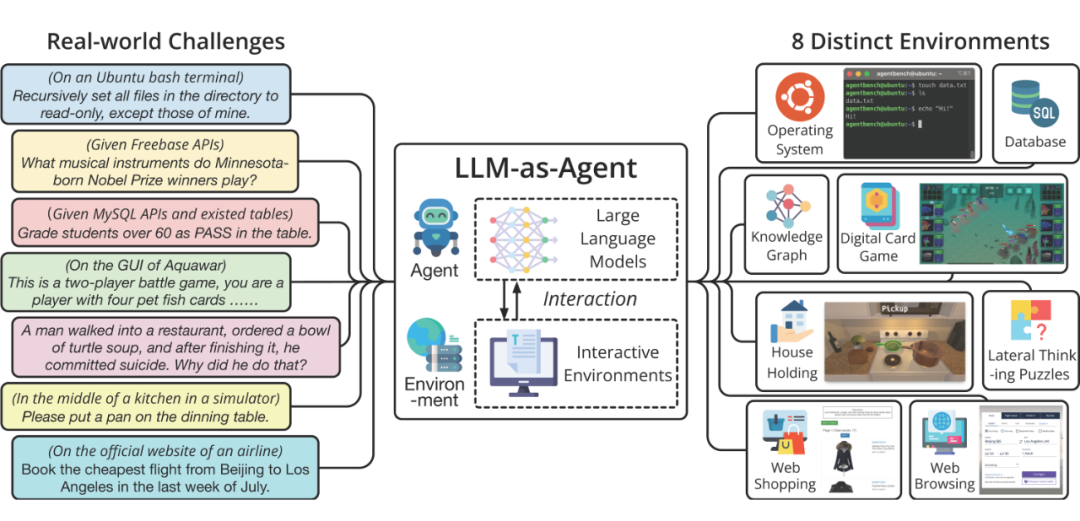
去年 8 月,笔者和合作者一起完成了 AgentBench 这一工作,成为了首个系统评估 LLM-as-Agent 能力的评测基准,得到了许多关注。从 AgentBench 发布一年来,基础模型和智能体领域都发生了翻天覆地的变化。
在基础模型领域,一个尤其重要的进展是多模态大模型的出现和逐渐成熟(如 GPT-4o)。这改变了大模型智能体的输入类型(文本-> 文本+视觉),并大大扩展了智能体的应用范围。
在智能体领域,一个重要的概念——基础智能体,开始引起大家的注意(参考 Jim Fan 在 TEDx 的演讲)。理想中的智能体,不应当只能完成一个特定的任务,而是能同时掌握应对多种环境的能力并实现泛化。
更关键的是,在笔者看来,基础智能体的概念为应对基础模型扩展定律的难题和实现基础模型真正的落地提供了绝佳的助力。具体来说,基础模型扩展定律(Scaling Law)面临数据天花板问题:文本数据逐渐被消耗殆尽,而现利用多模态数据的训练方式,目前看来大多无法提升模型的“智商”(即模型推理和完成复杂任务的能力)。
而面向智能体进行 Trajectory SFT(轨迹微调)数据的合成和 RL from Agent Feedback(智能体反馈强化学习),可能尚有巨大的空间,并且能直接面向具体应用进行落地。
在近期的另一个工作 AutoWebGLM 中,笔者和合作者就一起初步探索了在网页浏览方面合成训练 Trajectory 并采用强化学习的效果,并实现了基于 ChatGLM3-6B 模型媲美 GPT-4 在多个网页浏览数据集上的效果。因此,笔者也非常好奇合成轨迹这一方案,对于更广泛的多模态智能体环境的效果。而这也就是 VisualAgentBench 开发的缘由。

论文链接:
https://arxiv.org/abs/2408.06327
仓库链接:
https://github.com/THUDM/VisualAgentBench

VisualAgentBench:构成
因此,在过去半年的时间里,我和另外两位主要作者张天杰和谷雨,投入了大量精力打造 VisualAgentBench(VAB)这一评测基准,囊括 3 个代表性的多模态智能体应用场景和共计 5 个环境:
具身智能:居家机器人模拟器(VAB-OmniGibson),我的世界(VAB-Minecraft)
GUI:智能手机(VAB-Mobile)和网页浏览(VAB-WebArena-Lite,通过改造和修正 WebArena 实现)
视觉设计:前端 CSS(VAB-CSS)
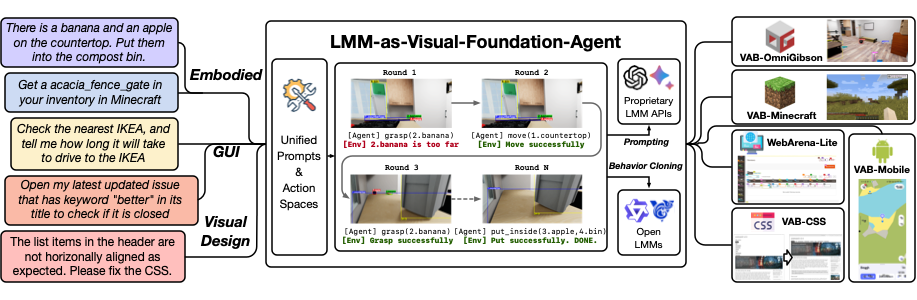
目标为大家更系统地理解多模态大模型和智能体的进展并投入开发铺平道路。在整个 VAB 的设计过程中,我们考虑到了几个重要的设计特性:
以视觉为中心:基础智能体应当具有良好的通过视觉获取环境信息的能力。尽管像网页这样的场景中,HTML 是非常有益的补充信息,但人类却无需阅读原始 HTML 仅通过视觉就完成网页上的复杂任务。这说明在评测基准中重点关于通过视觉如何完成智能体任务是十分必要的。
高层次的决策推理:VAB 关注多模态大模型在高层次上的决策能力。许多此前的工作比较关注多模态大模型在具体智能体低层次操控上的能力(如 Steve-1,RT-1),但大模型的能力优势主要还是结合常识、知识和指令遵从的复杂推理和工具调用。因此,VAB 重点希望探究和开发多模态大模型执行长序列决策和应对环境变化的准确性。
交互式评测:在真实世界智能体任务上评估大模型非常具有挑战性,因为实现目标往往可以有许多可行的路径。此前,许多评估数据集会采用在收集的某条成功轨迹上的平均单步成功率(Step Success Rate)作为评估方式,但这和真实世界的差异巨大,也无法考虑模型自我纠错的能力。
因此,开发 VAB 过程中,我们的许多工程努力在于实现在 5 个环境中的交互式评测(即通过最终智能体是否完成了特定目标来作为评判标准),并采用完整的成功率(Success Rate)作为评估标准。这也与当前许多特定领域智能体评估基准(SWE-Bench,WebArena,AgentBench 中的部分环境,OS-World)对齐。
用于行为克隆的轨迹合成数据:最最重要的一点,VAB 的构建中,我们花费了大量精力合成每个环境中的训练轨迹,用于给大家提供开发自己的多模态基础智能体的基础。
此前,绝大多数智能体评估基准(SWE-Bench,WebArena,AgentBench,OS-World)并未提供训练数据,使得在这些基准上通过微调开源模型进行改善非常困难。而 VAB 通过采用和组合一系列合成数据的策略,成功完成了这一目标(具体见下一章节的介绍)
评估结果整体见下:
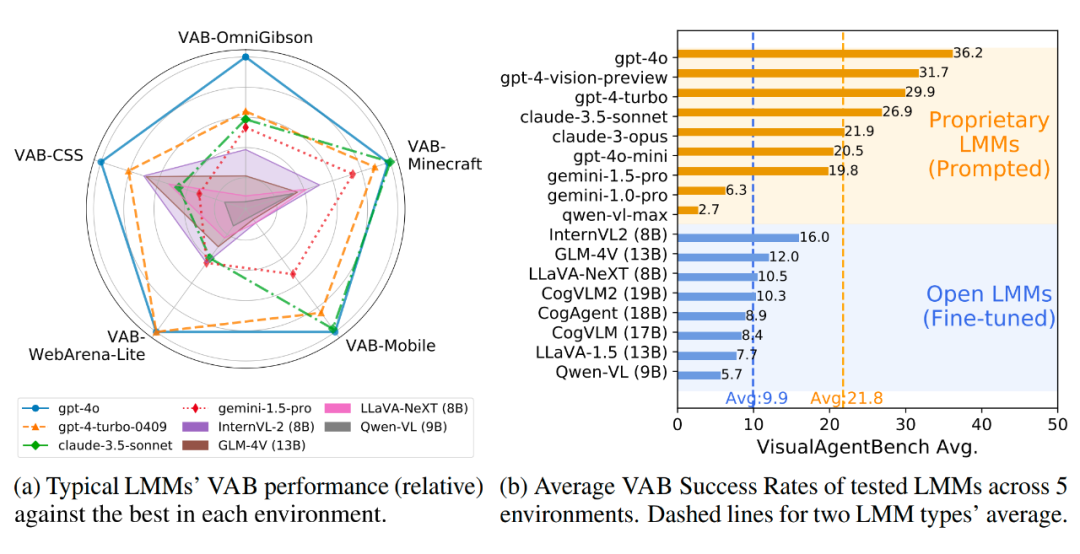
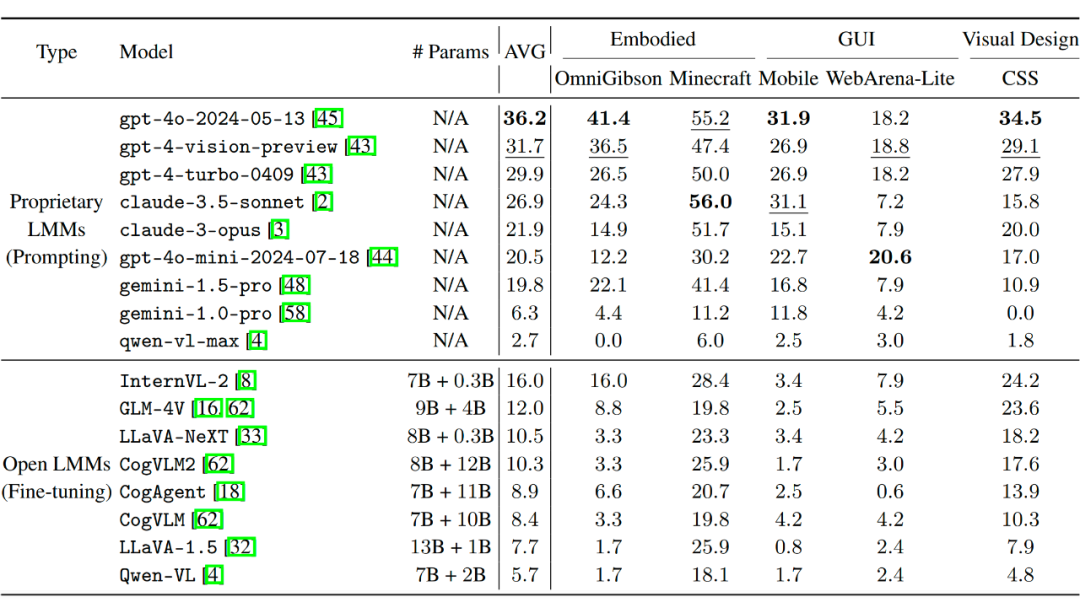
我们有以下的重要观察:
VAB 对于当前的多模态大模型十分有挑战性:我们发现在 VAB 上,当前的多模态大模型们表现普遍远远不能令人满意,闭源 API 的平均成功率也仅有 20% 左右,说明多模态大模型的推理和决策能力还亟须提升。最强的模型仍然是 GPT-4o,能取得 36.2% 的成功率,但也远远未在选定的这些环境上达到可以部署应用的水平。
而我们也发现,在传统视觉评估基准上声称自己能媲美 GPT-4v 和 GPT-4o 的一些模型(如 Claude-3.5-Sonnet 和 GPT-4o-mini),在涉及复杂推理的智能体任务上仍然有较大差距。Claude-3.5-Sonnet 在 VAB-Minecraft 和 VAB-Mobile 上取得了媲美 GPT-4o 的能力,说明可能在训练中专门面向此类环境进行了优化。
轨迹合成数据微调,可以大大提升开源多模态大模型的表现:在 VAB 的初步评测中,我们发现开源多模态大模型都存在复杂指令遵从的严重缺陷。具体来说,就是在微调前基本完全不能服从 GPT-4o 和 Claude-3.5-Sonnet 可以服从的系统提示(System Prompt)。
但经过在 VAB 的合成轨迹数据上的训练,我们发现这些开源大模型的表现还是能变得具有相当的竞争力的,普遍至少能超过 Google 的 Gemini-1.0-Pro 的表现。这说明轨迹合成微调是非常具有前景的方法。
最强的闭源模型和开源模型之间存在差距,但很有希望被缩小:尽管开源多模态大模型许多声称自己能媲美 GPT-4v,但实践表明即使使用微调数据进行调整,它们目前和 GPT-4v和 GPT-4o 的差距仍然非常巨大,更不提仅仅通过提示来完成任务了。
当然,轨迹合成微调的效果表明,这可能是由于当前开源社区一方面缺少基座更大的开源多模态大模型、另一方缺乏面向智能体能力对齐数据关注造成的(而大公司可能会尤为关注智能体方面的能力对齐)。如果社区协力在这方面进行开发,笔者认为这一差距是可以被大大缩小的。
在论文中,我们还深入分析了一些关于智能体能力的消融实验。例如,我们观察到:
Chain-of-Thought(或者说 ReAct 方法)并不总是有效,对于一些 Agent 任务而言反而是负面效果
当前多模态大模型对于多图的对比理解能力普遍很差
纠错能力在许多任务的成功中是不可或缺的
等有趣的观察。欢迎大家具体阅读论文查看相关分析数据和结论。

VAB的轨迹合成策略
如上文所言,我们在 VAB 的一个重点努力在于,深入探索了如何有效地合成轨迹数据以提升多模态大模型在智能体任务上的表现。面对给定环境合成轨迹数据问题,有两个值得深入思考的挑战:
如何获取大量多样的用户指令:与基础模型开发中的 Self-Instruct 方式类似,在合成智能体轨迹训练数据前,需要先合成指令数据。然而,相比 Self-Instruct 等方式更困难的点在于,智能体指令数据需要面向环境本身设计,并且绝大多数时候需要保证指令在环境中是可完成的。
如何获取对于指令的轨迹:这又存在两个问题。一是如何获得正确的轨迹,并且有办法让我们判断这一轨迹最终的确成功达成目标了。二是,如何有办法在轨迹中体现出模型的纠错,而非每一步的无比正确。
这些问题十分困难,即使在 VAB 中我们也只是进行了初步的探索。
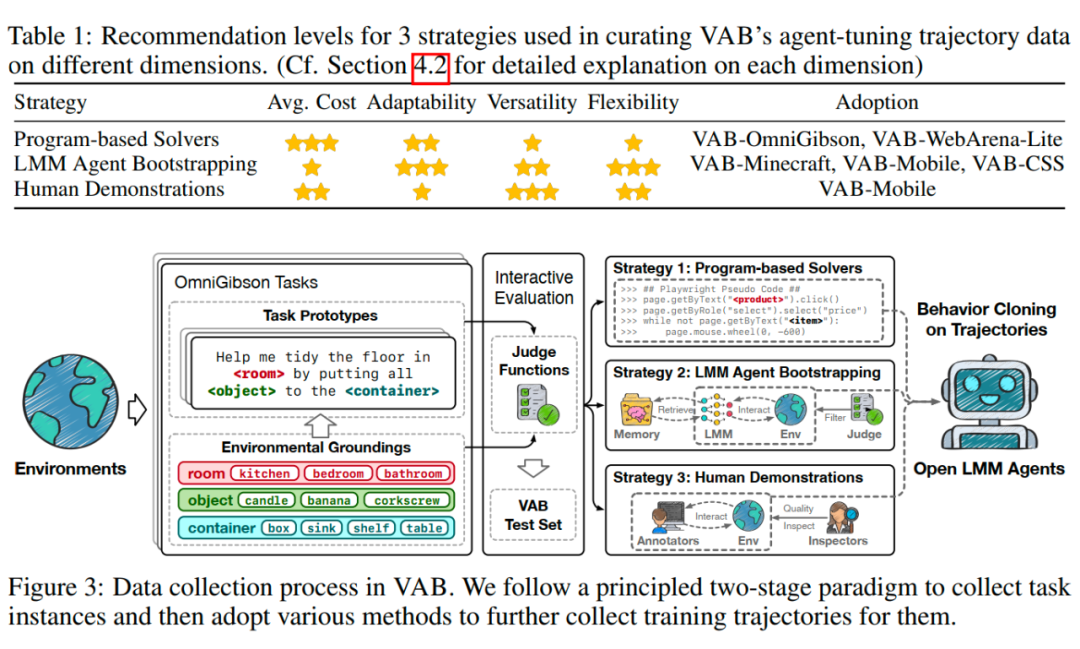
首先,对于获取大量多样的用户指令这一问题,我们采用了“原型+实例化”的构造方法。对于一个环境,我们可以分析出这一环境中大致可以进行的任务类型,并写成留有占位符的任务模板(例如,在居家机器人环境 VAB-OmniGibson 中可以有“Help me tidy the floor inby putting all to the”这样的任务原型)。
在原型的基础上,我们需要 Grounding(这个词挺难翻译的)到具体的环境内容中,实现具体指令的实例化。例如,在 VAB-OmniGibson 中,环境中的可以有厨房、卧室、浴室等,可以有蜡烛、香蕉、开塞钻等,可以有箱子、水槽等。这些环境内容列表,都需要从环境配置中具体获取,以实现指令对环境的 Grounding 并确保了指令的合理性。
这一过程同时也产生了对于指令最终能否完成的判断函数(Judge Function)的基础。例如,如果我选择为蜡烛,为箱子,那么在 VAB-OmniGibson 中我们最终的判断函数即为“是否所有蜡烛的位置都位于箱子中”这一规则。对于一些回答性的问题(例如在 Web 上查询自己最近订单的金额)也是可以类似方式来构造具体答案的。
其次,对于如何获取轨迹这一问题,我们设计和采用了三种各有特色的方式。
程序求解器:通过人类专家利用自动化脚本撰写一系列判断条件以实现程序化的轨迹合成。例如,在网页上对于具体某类任务,可以使用 Playwright 工具来实现 RPA 的功能,从而获取求解的轨迹用于训练。
多模态智能体自举(Bootstrapping):对于有判断函数的指令,可以通过对比较强的多模态大模型(如 GPT-4o)进行提示以构建能力较弱的智能体,然后执行任务并筛选正确轨迹的方式来构造训练集。我们为了提高正确率,还可以结合一些复杂的智能体设计策略(例如引入记忆模块)。
人类标注:许多场景最终可能前两种策略都不够高效,反而人类的标注更加合算和有效,那就不如采用更多的人工标注来完成。
事实证明,在每个具体的多模态智能体环境中构造轨迹时,都会需要考虑结合其自身特性才能实现最高效轨迹数据合成。具体来说,我们考虑了以下一些维度:
平均成本:这是最主要的考量(因为轨迹合成非常麻烦)。程序求解器一旦完成,就可以产生大量的数据,所以平均成本一般最低;人类标注成本中等,特别是随着标注员逐渐熟练,这一成本会有所下降;而在当前,多模态智能体自举反而是最贵的,因为需要使用到 GPT-4o 之类的闭源 API,成本不低。然而,我们相信随着开源多模态基础智能体的发展,这一问题应该可以得到长足的改善。
环境适应性:这一维度表征了一个策略有多容易在新的环境中被采用。总的来说,多模态智能体自举是适应性最强的,只需要设计良好的系统提示就可以完成;程序求解器需要人类专家撰写脚本,相对更复杂;而人工标注需要考虑到标注员招聘、培训和标注文档撰写的问题,通常启动起来很慢。
更要命的是,部分环境由于要求的资源条件太高(例如居家机器人 OmniGibson 环境,需要带有光线追踪的 GPU 和至少 16GB 内存才能有效运行,这超出了正常标注员的个人资源条件),也无法由人类标注员进行标注。
指令多样性:这一维度关注了在一个环境中,一种策略能解决如何多样的指令轨迹合成的需求。经过良好训练的人工标注通常能解决环境中几乎所有的问题,而多模态智能体自举对于困难的指令通常无能为力。相比之下,程序求解器只能 case by case 解决具体的任务类型,能支持的多样性指令最差。
轨迹灵活性:这是一个重要的考量,因为模型是否能学会纠错这一重要能力,取决于合成的轨迹中是否有类似的行为。然而,人类标注(为了质量控制)和程序求解器通常无法做到这一点。只有多模态智能体自举可以。
综合以上众多考虑因素,我们在 VAB 中对于每一个具体环境,最终采用了相当混合和灵活的策略。更多具体的考量,可以参考论文中的表述。我们相信,这些经验对于之后有意愿从事合成轨迹数据开发的研究者来说,会是十分重要的参考。

总结
VAB 在笔者看来,会成为多模态智能体研究中一个重要的平台,为接下来研究者们更深入地评估和开发多模态智能体铺平了道路。我们也希望对 VAB 感兴趣的同学一起加入 VAB 的下一个版本的迭代,包括引入更多环境和支持强化学习等。
笔者相信,要实现 AGI,仅仅让模型停留在思考(Think)的层面是远远不够的,只有当基础模型变成基础智能体,能在真实环境中大规模地采取行动(Act)以获取真实反馈实现自我提升时,才是实现将人类从繁琐工作中解放的 AGI 的真正黎明。
🌟本文内容已获论文原作者独家授权发布,如需转载请联系PaperWeekly工作人员微信:pwbot02,添加时请备注「转载」。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·
















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









