







©作者 | 栾思焘
单位 | McGill University & Mila
研究方向 | 图表示学习、GNN
说起近两年图学习和图神经网络领域最热门的话题,就不得不提异配图上的学习问题,近期关于异配问题的 survey 已经有不少了 [1,2,3],这几篇都各有特点,不过总觉得没有一篇能达到我心目中对这个领域比较理想的总结,于是就自己归纳整理了这篇 handbook。它可以作为参考书帮新手快速入门 heterophily 这个领域,也可以协助 researcher 查询了解某个方向的类似工作,节省你整理 related work 的时间。

文章链接:
https://arxiv.org/pdf/2407.09618
我自己在整理的过程中也学习到不少新东西,比如我没想到 heterophily 在 fraud/anomaly detection 上应用这么多,还有跟 CV,optimization 等方向有些意想不到的联系。所以根据我在整理这篇 handbook 过程中得到的经验,我会在本文最后给 heterophily 相关的方向给个评级,希望帮助大家尤其是 junior researcher 快速找到适合自己的课题。
下面言归正传,我会先简单介绍一下什么是异配问题,然后简单总结一下每个章节涉及的主要内容。



图学习中的异配问题
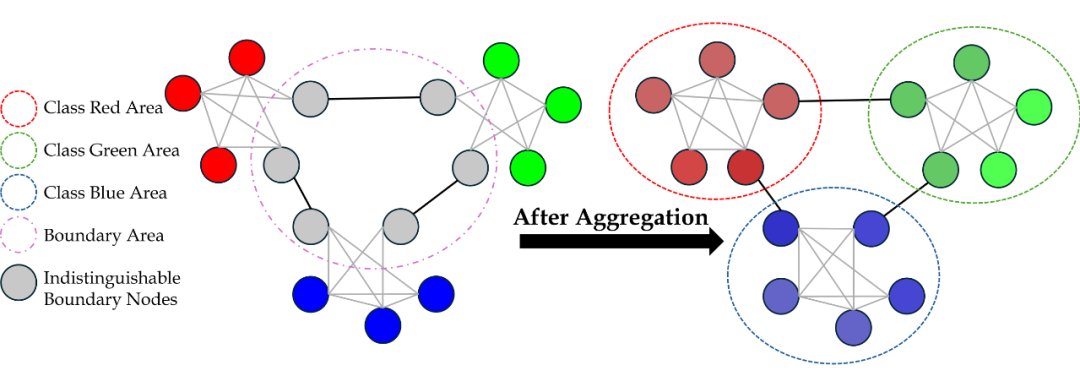
▲ 同配图上的信息聚合:可以把难分辨的节点变得容易分辨
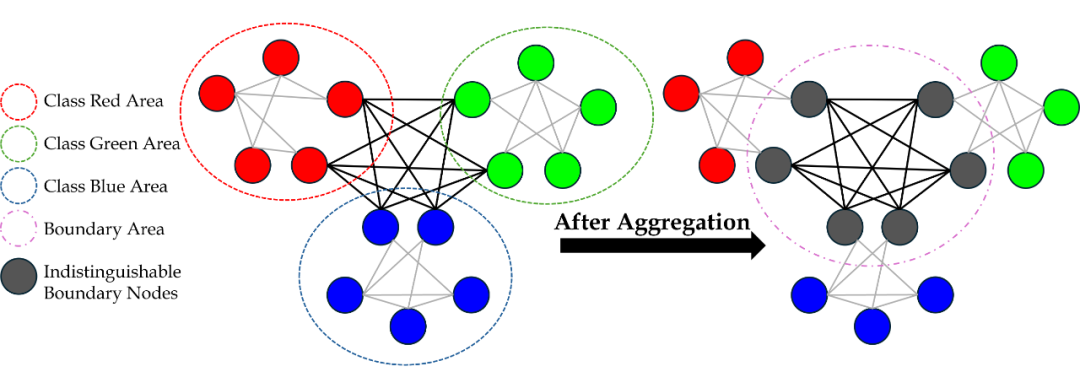
▲ 异配图上的信息聚合:可以把易分辨的节点变得难分辨,污染 boundary nodes
同配(homophily)说的是图中相连的节点更倾向于拥有相似的特征或标签,它被认为是消息传递网络(message passing neural network)比传统神经网络表现更好的重要基础,尤其是在节点级的任务上(node-level tasks)。而异配(heterophily)与同配相反,说的是图中不相似的节点更有可能被连接,这就会导致依据这种图结构做消息传递会使不同类的节点错误的混合到一起,从而让分类器难以辨认。
在上面图片中的两个例子也可以看出,同配图上的信息聚合可以把难分辨的节点变得容易分辨,而异配图上的信息聚合可以把易分辨的节点变得难分辨(尤其是boundary nodes)。
异配图学习就是专门研究如何在这些“不好的图(bad graphs)”上“变废为宝”地利用图结构学出有用的信息,同时又不会牺牲在同配图上的表达能力。更多背景介绍可以参考我之前写过的两篇博客 [4,5]。
作为图的基本性质,同配/异配深刻的影响着跟消息传递机制相关的所有网络,包括 transformer 和 graph transformer,同时,我们原有在图学习中建立的方法和结论几乎全部都需要在同配/异配的角度下推倒重建,并且重新审视他们的价值和正确性。

同配度量(Homophily Metrics)
同配度量就是用一个标量(scalar)来量化一个图的同配程度,比如衡量图里所有边中,连接两个同类节点的边的比例,如果这个比例低我们就说它是异配图。
设计同配度量的目的是希望根据这个值就可以挑出那些“不好的图“,也就是在图上做消息传递还不如不做消息传递的那类图,在 [5] 中我们进行了具体阐述,即在图上“graph-aware model underperforms its corresponding graph-agnostic model”。能用来区分这些图“好坏”的度量就是好度量,不然就是没啥用的(事实是有用的度量并不多)。
在这一部分,我们对同质(homogeneous,图中只有一个类型的节点和边)和异质图(heterogeneous,图中不止一个类型的节点和边)中的同配度量进行了归纳分类。
关于异配图和异质图的区别,请看:
https://zhuanlan.zhihu.com/p/686688743

基准和测试
3.1 同质图上的基准数据集
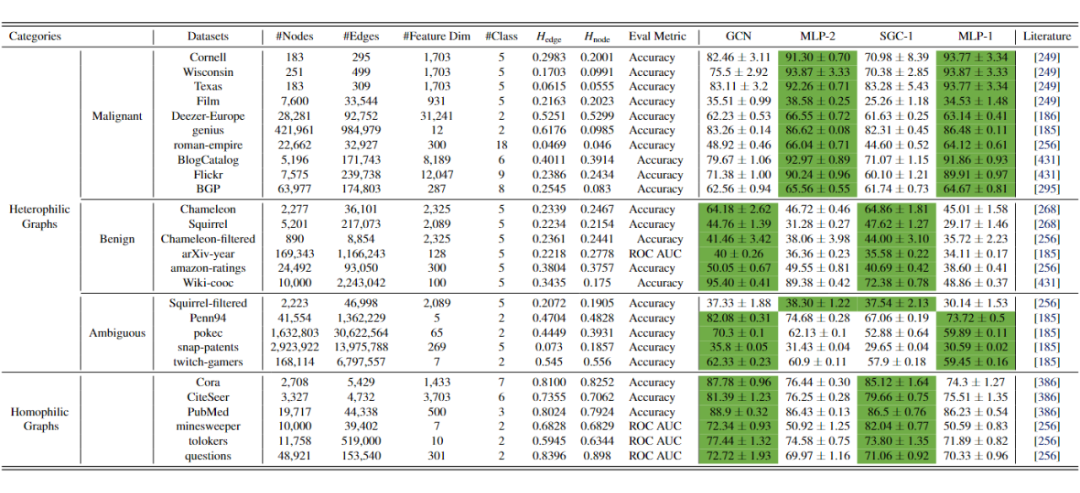
▲ Heterophilic Benchmark Datasets分类
近几年出了不少的 heterophilic benchmark datasets [6-12],要对他们进行分类很自然地需要先问一个问题:这些图对于 message-passing 来说都是 “bad graphs” 吗?
我们知道用现有 metric 来衡量虽然快但并不完全准确,但是我们可以进行实验,通过比较 graph-aware model vs. graph-agnostic model 的表现来判断。具体的,根据 [5],我们做两组实验 GCN vs. MLP-2 以及 SGC-1 vs. MLP-1,为了公平比较,我们不添加任何 trick 比如 skip connection,normalization 等,充分搜参并且搜参范围相同,其余训练 setting 也完全一样,比较结果放在上面的表格。通过在 27 个常用数据集上的实验,我们可以发现
异配数据集可以分为三类:1. malignant,即GCN 比 MLP-2 表现差,SGC-1 比 MLP-1 差;2. benign,即与malignant相反,graph-aware models 都比对应的 graph-agnostic models 表现好;3. ambiguous,即线性和非线性模型出现不一致的结果,这说明模型的非线性和 graph structure 之间可能存在协同作用,一起影响了 GNN 的表现。
只有 malignant 和 ambiguous heterophilic datasets 可以被称为 “bad graphs” 或者 challenging graphs,所以一个模型如果 claim 自己可以解决异配问题,则需要提供在这两类图上的测试结果;另一方面,如果一个模型只在 benign heterophilic datasets 上表现好,并不能说明它可以解决异配问题,因为本身在这些 “good graphs” 上做 message passing 就是 beneficial 的。
一个好的 heterophily-specific model 不仅要在 malignant 和 ambiguous 两类异配图中表现好,还要在同配图中不能比 baseline models(e.g. MLP, GCN, GAT, GraphSAGE)差,即不能牺牲在同配图上的表现来获取在异配图上的性能提升,或者说不能是瘸腿的。我们在之后会出文章专门测试讨论现有 SOTA models 的问题,并挑出瘸腿的方法,到时候会再写一篇博客,敬请期待。
3.2 同配度量在合成图(Synthetic Graphs)上的比较
对比 homophily metrics 常用的方法就是利用合成图进行比较,一般是生成 homophily level 不同的图结构还有节点特征,在每个图上计算 metric value 并且训练 baseline GNN,画出 metric curves 并与 GNN performance curves 进行比较,如果形状相似的话说明这个 metric可以比较贴切的描述 GNN 的 behavior。
我们总结了三个常用的合成图方法:Regular Graph [13],Preferential Attachment [14] 和 GenCat [15,16],并且在上面初步测试了一下常用的 metrics,详细结果请看原 paper。
3.3 异质图上的基准数据集
异质图上还没有啥像样的异配数据集,基本还是用以前的老图,我们总结了一下 [17,18] 中的实验结果,他们的研究初步发现 heterogeneous GNN 的表现跟 meta-path induced subgraphs 的 homophily values 还是有很强的相关性的,不过具体是如何影响还没有结论。[18] 还发现 homophily values 跟 connection strength 有关系。我们在文章 Section 6.2 里提出了这个方向下一步需要解决的几个问题并提供了几篇 references。

同质异配图上监督学习(Supervised Learning)
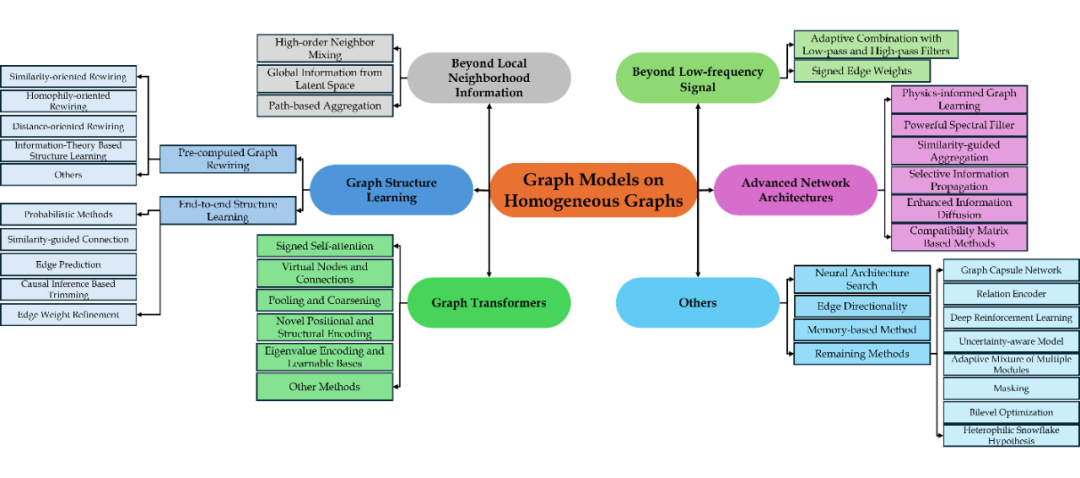
▲ Supervised Learning Methods on Homogeneous Graphs
这是目前市面上讨论总结最多的部分,相对于已有的 survey [1,2,3],我们对于 Beyond Low-Frequency Signal,Beyond Local Neighborhood Information, Advanced Network Architectures, Graph Structure Learning 方法总结得更加全面系统,特别增加了 graph transformer 部分,并且在 others 部分也整理了不少不算主流但是很有价值的遗珠方法。

异质图中的异配问题
异质图中的异配问题还属于蓝海,我们整理归类了现有的研究结果和模型,并且从三个方面提出了下一步应该做什么。

异配图上的无监督学习
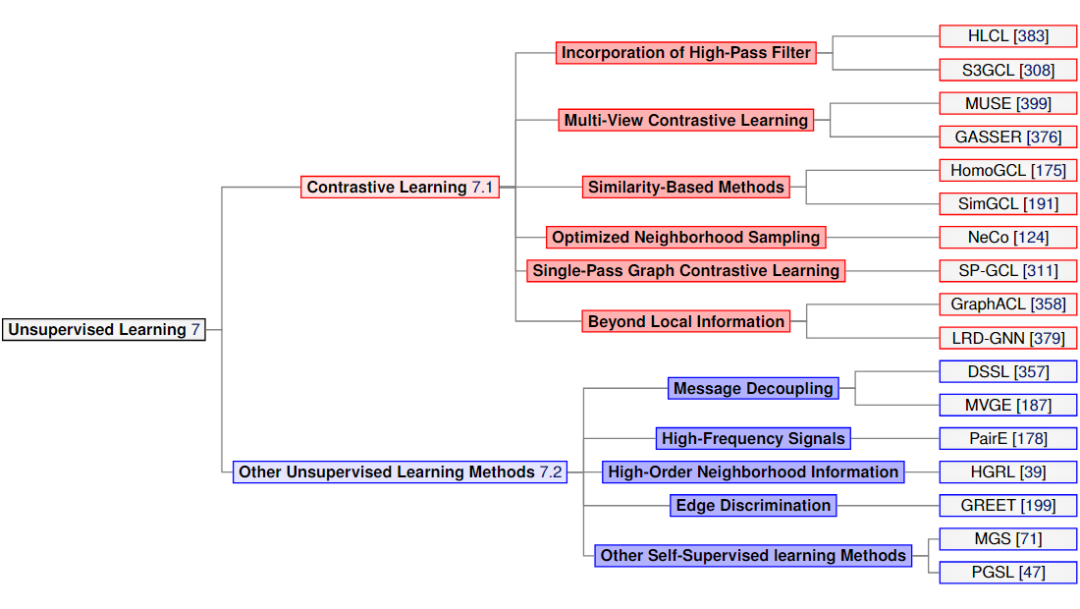
▲ Unsupervised Learning on Heterophilic Graphs
异配图上的无监督学习是近两年崛起比较快的研究方向,而且主要集中在对比学习(contrastive learning)上。这篇文章是第一个对无监督学习进行系统整理的。

同配/异配的理论分析

▲ Theoretical Studies
跟异配相关的理论文章方向繁多,我们也是第一个对理论分析进行归纳整理的,其中 Mid-Homophily Pitfall 和 Distribution Shifts 主要是分析异配对 GNN 有什么影响以及为什么有这样的影响,Section 8.3, 8.4 是研究异配与 GNN 另外两大挑战 over-squashing 和 over-smoothing 之间的关系,最后一部分总结了其余很有趣的分析角度。

与异配相关的应用
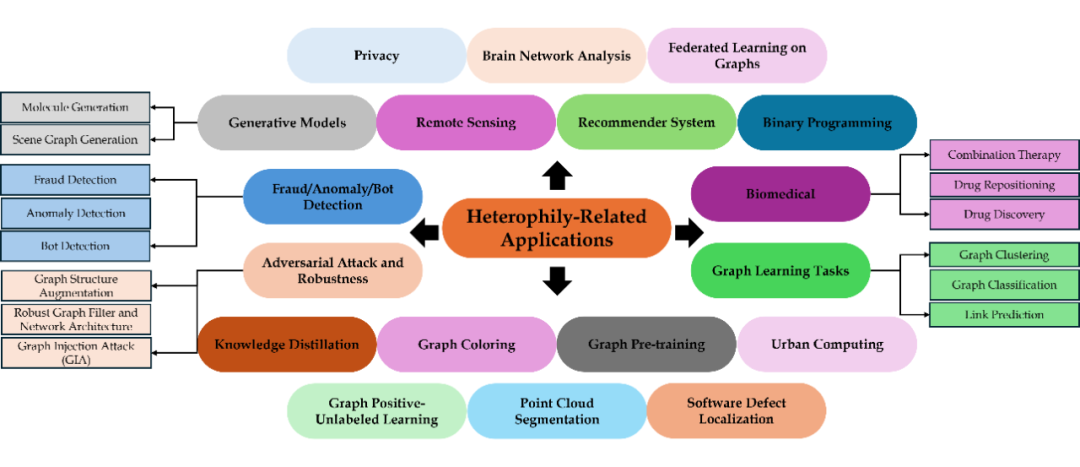
▲ Heterophily-related Applications
应用部分是最超出我预期的,特别是 fraud/anomaly detection 这部分已经有非常多的模型和方法被提出了,还有几个比较清奇的方向,比如 urban computing,graph coloring, binary programming, remote sensing, software defect localization。我觉得相关应用待开发的潜力还很大,这一部分就是帮各位开开脑洞,只要是在图中性质不同的节点会 densely connected 的应用方向都可以往异配方面考虑。

挑战和未来方向
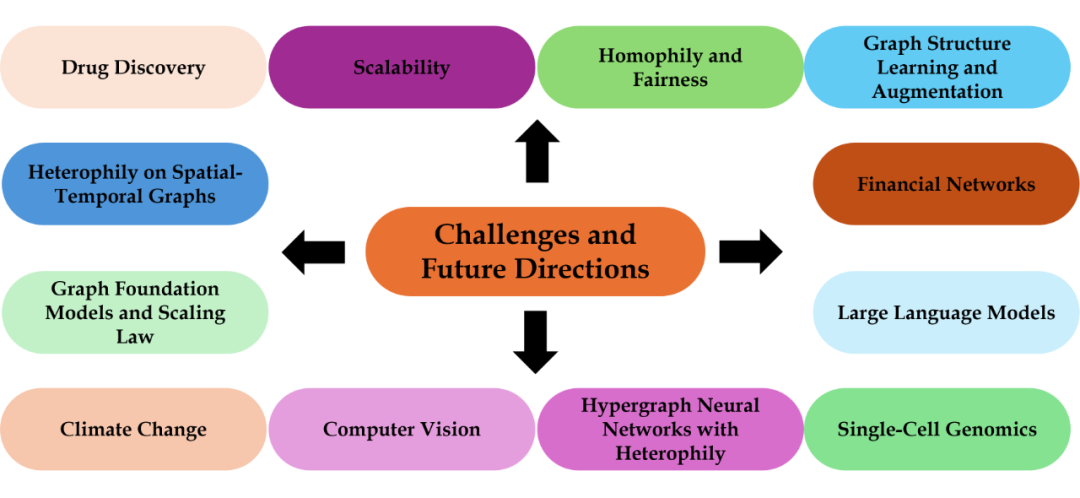
▲ Challenges and Future Directions
异配未来有不少可做的方向,例如探索时空图和超图上的异配,它也会成为构建 LLM 和 graph foundation model 中不可缺少的元素。
下面分享我对 heterophily 相关方向的评级,评级标准完全基于我个人在整理这篇 handbook 过程中的经验体会和主观感受。
C级
在同质图上做 heterophily-specific GNN:目前出 paper 最多但也是竞争最激烈的方向,方法同质化严重,benchmark 被刷的差不多了,感觉大部分新方法的提升都很 incremental,除非你模型的效果特别好,不然有点难卷,尤其想发三大会的话。
B级
异配图上的 graph transformer(GT):GT 目前还处于瘸腿状态,也就是做 graph-level task 很厉害但是 node-level 很一般,尤其是在异配图上非常差。
fraud/anomaly detection:这是目前应用做的最多的方向,前景不错,有一点点卷但是没有上面那么严重,处在发展最快的阶段。
同配/异配的理论研究:把他放到 B 主要是因为做理论难度大而且周期会长一点,需要灵感,而且每年真正有价值的好文章可能也就三五篇,可以参考 Section 8.5 看看有没有什么新奇的思考角度可以借鉴。
privacy/fairness:政治正确你懂的,而且我觉得 homophily 对 privacy 的确有挺大影响。
异配图上的无监督学习:同第二点,一般卷,还有不少待开发问题。
A级
heterogeneous graph, temporal graph, hypergraph 上的异配问题:benchmark dataset 缺,homophily metrics 缺,model 基本等于没有,理论无,这几个方向几乎还是白纸,这些类图上的所有应用和模型几乎都可以放到异配角度下重做一遍。
验证 graph classification 以及 graph generation 中的异配问题:异配问题最开始是在 node-level tasks 上提出的,它是否跟图分类和生成也有关系,有什么关系,如何定义这种关系是下一步可以研究的。
CV:目前我主要看到有 scene graph generation 和 point cloud segmentation 中引入了异配的概念进行研究,并且基于异配设计的 model 都挺好使的,鉴于 CV 有极多的应用场景,我觉得还有广阔的前景可以开发。
其他新的应用场景
我想分享的内容暂时就这么多了,希望能帮你梳理好脉络或者带来点灵感,建议博文配合原 paper 一起食用。学术合作和交流请联系 sitao.luan@mail.mcgill.ca。对这篇 handbook 有问题,建议(typo,写作问题也算)或文献补充,也请联系这个 email,谢谢。

参考文献
[1] Graph Neural Networks for Graphs with Heterophily: A Survey
[2] Heterophily and Graph Neural Networks: Past, Present and Future
[3] Learning from Graphs with Heterophily: Progress and Future
[4] https://zhuanlan.zhihu.com/p/587972974
[5] https://zhuanlan.zhihu.com/p/653631858
[6] Geom-gcn: Geometric graph convolutional networks. In International Conference on Learning Representations, 2020.
[7] New benchmarks for learning on non-homophilous graphs. In Workshop on Graph Learning Benchmarks (GLB 2021) at WWW 2021.
[8] Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods. Advances in Neural Information Processing Systems, 34:20887–20902, 2021.
[9] A critical look at the evaluation of gnns under heterophily: Are we really making progress? InThe Eleventh International Conference on Learning Representations, 2022.
[10] Multiscale attributed node embedding.Journal of Complex Networks, 9(2):cnab014, 2021.
[11] Beyond homophily: structure-aware path aggregation graph neural network. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI, pp. 2233–2240, 2022.
[12] Opengsl: A comprehensive benchmark for graph structure learning.Advances in Neural Information Processing Systems, 36, 2024.
[13] Revisiting heterophily for graph neural networks.Advances in neural information processing systems, 35:1362–1375, 2022.
[14] Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In international conference on machine learning, pp. 21–29. PMLR, 2019.
[15] Beyond real-world benchmark datasets: An empirical study of node classification with gnns.Advances in Neural Information Processing Systems, 35:5562–5574, 2022.
[16] Gencat: Generating attributed graphs with controlled relationships between classes, attributes, and topology.Information Systems, 115:102195, 2023.
[17] Homophily-oriented heterogeneous graph rewiring. In Proceedings of the ACM Web Conference 2023, pp. 511–522, 2023.
[18] Ogb-lsc: A large-scale challenge for machine learning on graphs. NeurIPS, 34, 2021.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









