








作者丨张琨
学校丨中国科学技术大学博士生
研究方向丨自然语言处理


论文动机
社区问答一直是一个非常热门的地方,人们在这里提出问题,寻找答案,例如知乎,Quora 等。但是社区问答一直有一个很严重的问题,那就是有很多重复性的问题,这就给搜索引擎带来了很大的挑战,如果过滤这些重复问题,为用户提供更好的答案推荐是这类网站不断探索的。
当前很多的方法更多的是关注如何构建问题的语义表征,通过这些语义表征区分相似问题和不相似问题。但这存在一些问题,有些问题虽然问的问题看起来不一样,但是结合先验知识就会发现他们其实问的是一个问题,例如下图中的第一个例子。

这个时候答案就可以为我们提供这种先验知识,通过答案就能发现两个问题问的内容是相同的。而利用答案来增强对问题的理解是目前大多数工作没有考虑到的。那么是否可以直接将答案和问题放到一起,然后进行分类呢?答案是否定的,某些情况下,答案虽然是相同的,但是针对的问题却是完全不同的,例如下图中的第二个例子,这时答案的引入反而会影响到对问题的判断。
因此如何才能准确的利用答案的信息去增强对文本的理解,同时不会引入更多的噪声呢?这就是本文想要解决的问题。
模型结构
为了解决以上两个问题,本文设计了一个自适应的多头注意力网络,在引入答案信息的同时不会引入过多的噪声,模型的整体结构如下:
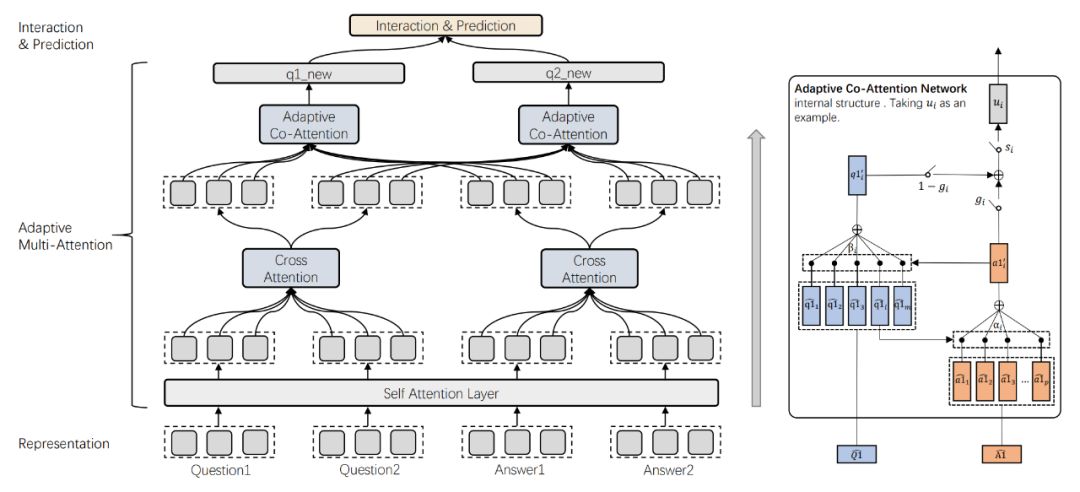
Representation Layer
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4047
4047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









