








 超级会员免费看
超级会员免费看

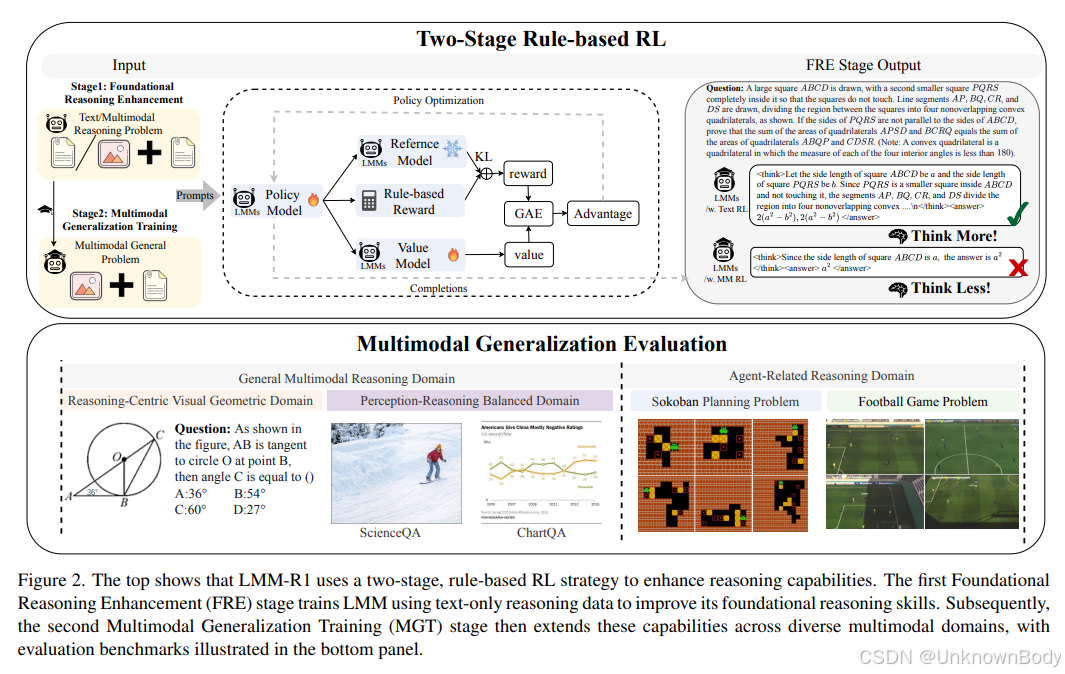
文章主要内容
- 研究背景:大型多模态模型(LMMs)增强推理能力面临挑战,基于规则的强化学习(RL)在多模态扩展中存在数据和基础推理方面的问题。
- 相关工作:介绍LMMs和RL在LLMs、LMMs中的研究现状,指出多数LMMs缺乏推理能力,多模态领域中利用RL增强LMMs推理能力的研究尚处于早期。
- 预备知识:采用近端策略优化(PPO)算法训练LMMs,设计包含格式奖励和准确率奖励的奖励函数。
- LMM-R1框架:分为基础推理增强(FRE)和多模态泛化训练(MGT)两个阶段。FRE阶段通过纯文本和多模态推理增强两种方式提升基础推理能力;MGT阶段在通用多模态推理领域(包括几何、感知-推理平衡等子领域)和与智能体相关的推理领域(如推箱子、足球游戏等任务)进行训练和评估。
- 实验:以Qwen2.5-VL-Instruct-3B为基线模型,

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











