







 超级会员免费看
超级会员免费看
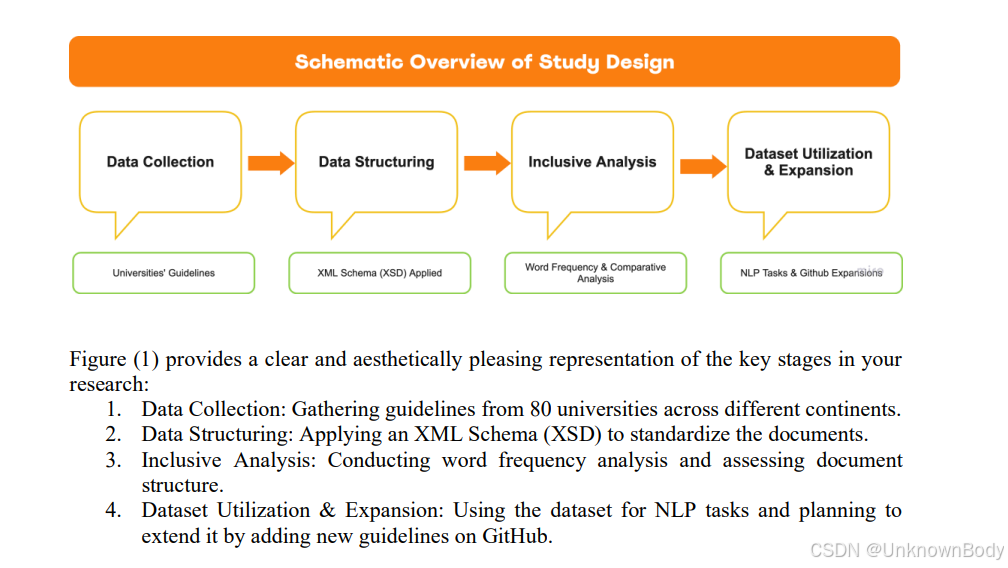
文章主要内容
- 研究背景:生成式人工智能(GAI)和大语言模型(LLMs)在学术界的应用日益广泛,但相关政策存在不足。联合国教科文组织调查显示,不到10%的学校和大学制定了正式政策,因此需要综合框架平衡创新与伦理考量。
- 数据集介绍:引入AGGA数据集,包含来自六大洲80所大学的学术指南,涵盖多种学术领域和机构类型,总字数达188,674字。数据集有MS Word、PDF和MS Excel三种格式,方便不同分析需求。
- 研究方法:从全球80所大学收集官方指南,依据地理位置和运营层面分类。运用Python和自然语言处理工具(如NLTK)进行文本挖掘和计算处理,包括分词、去除停用词、词干提取和词形还原等操作。
- 数据分析与验证:通过文本分析和可视化,识别出各大洲的热门关键词,并构建网络图表展示关键词与大洲之间的关系。验证了数据集的包容性和全球代表性,如不同大洲在人工智能应用方面有不同侧重点。
- 使

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











