







 UDP协议具有无连接、不可靠传输的特性,其报头包括源/目的端口、报文长度和校验和。端口范围0-65535,知名端口0-1023通常预留给特定服务。UDP最大传输64KB,超过需分包或使用TCP。校验和用于错误检测,CRC和MD5等算法用于生成。
UDP协议具有无连接、不可靠传输的特性,其报头包括源/目的端口、报文长度和校验和。端口范围0-65535,知名端口0-1023通常预留给特定服务。UDP最大传输64KB,超过需分包或使用TCP。校验和用于错误检测,CRC和MD5等算法用于生成。
UDP协议
基本特点:无连接、不可靠传输、面向数据报、全双工
UDP协议报文结构 ,以下分别是种画法
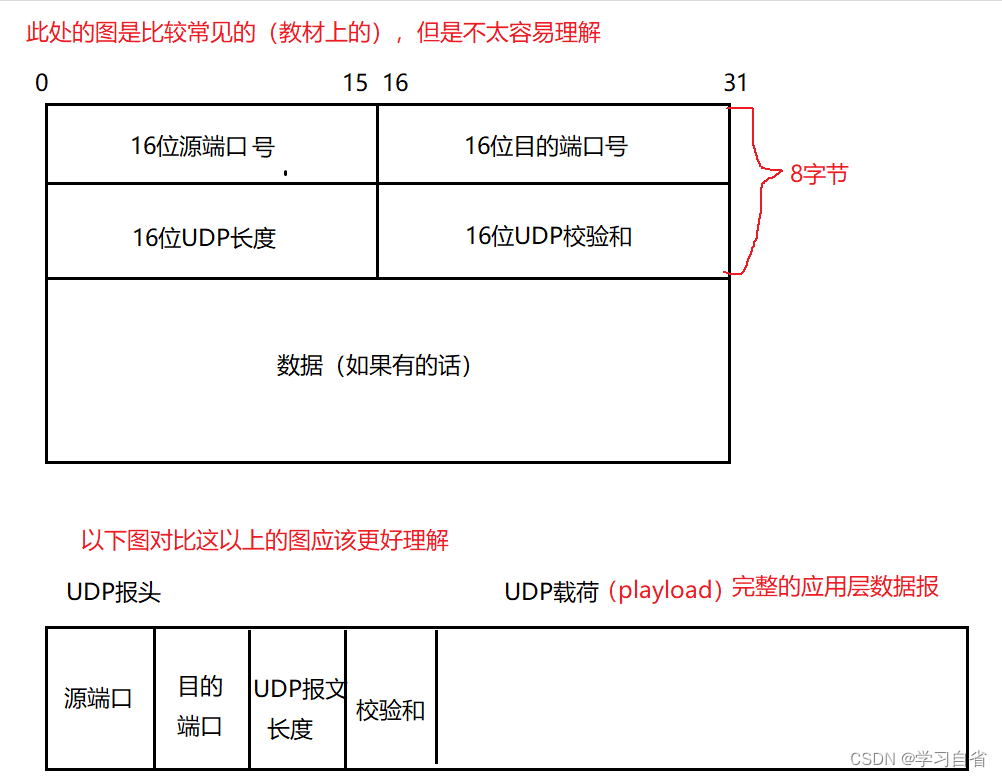
对上图进行解释:
UDP就会把载荷数据(就通过UDP socket ,也就是send方法拿来的数据,基础上再在前面拼接上几个字节的报头)
拼接:相当于字符串拼接 (此处是二进制的,不是文本的)
UDP报头里面包含了一些特定的属性,就携带了一些重要的信息
不同协议,功能不同,报头中带有的属性信息就不同
一次网络通信涉及到五元组:源IP 、源端口 、目的IP 、目的端口 、协议类型
对于UDP来说,报头一共就是8个字节 ,分成了4个部分(每个部分2个字节)
这四个部分:就是UPD报头对应的:源端口 、目的端口、UDP报文长度、校验和
1、端口
常提及到这里的端口都是有范围的 ,因为被分配了2个字节,所以端口范围:0->65535
但是我们自己写程序,绑定的端口,得是从1024起的
0->1023这个范围的端口:称为“知名端口号/具名端口号”,这些端口号是属于已经分配给了一些知名的广泛使用的程序了
那如果我们写代码非要指定一个1023以内的端口号行不行???
答案:不是不行 (以下是需要条件)
(1)先确定你使用的这个端口确实没有程序在绑定
(2)确定你有管理员权限
当然1023以下的端口,不是不能用,但是不是不建议用,这些端口是分配给了特定的程序,但是这个程序具体在你的电脑上是否运行着,电脑上是否安装了这些程序,都是不一定的,所以说即便这些端口真的空着,我们一般也不会去把他们作为我们使用的端口号
2、UDP报文长度
UDP报文长度也是2个字节,所以就是说它的范围也是:0->65535 换算单位 64kb,一个UDP数据报,最大只能传输64kb的数据(说实话真不大,太小了)
如果应用层数据报,超过了64KB 咋办???
(1)就需要在应用层,通过代码的方式针对应用层数据报进行手动的分包,拆成多个包通过多个UDP数据报进行传输(原来小于64kb send 一次就够了,现在需要多次send )
(2)不用UDP,换成TCP(TCP没有这样的限制)
以上虽然是两种方式,但是已经有比较大的区别了,使用UDP多次传输还是TCP传输
类比一下:货物装车 :
UDP:货物太多了,一辆车装不下,那就需要多辆车来,其实这个也挺麻烦的,多辆车都需要等着,看着比较耗费
注:UDP多次send 要写的代码也比较多,多些代码也就预示这代码可能产生bug的机会越多,有的地方如果必须使用UDP的话,那就使用
TCP:货物太多,一辆小车装不下,那直接装一辆货车,一次上货拉走
注:TCP代码就会少些,也不用顾虑这样的问题(此处没有说一定就要用谁,也并非数据量大的时候就一定会选择使用TCP,此处只是指明两者的区别,根据情况而定)
3、校验和
作用:是验证传输的数据是否是正确的
网络传输过程中,可能会受到一些干扰,在这些干扰下就可能出现“比特翻转”的情况
比特翻转: 就是 1 变 0 ,或者 0 变 1
网络传输本质上就是光信号或者电信号,这些可能受到一些物理环境的影响
再举出一个实例:网络传输数据 :10101010 在物理环境的影响下变为11110000一旦数据变了,对于数据的含义可能是致命的(代指关键性数据)
这样的现象是客观存在的,不可避免,咱们能做的就是,及时识别出,当前的数据是否出现问题,就引入了校验和来进行鉴别
针对数据内容进行一系列的数学运算,得到一个比较短的结果(比如2字节),如果数据内容一定得到的校检和结果结果就一定,如果数据变了,得到的校验和也就变了
针对以上解析(图解)
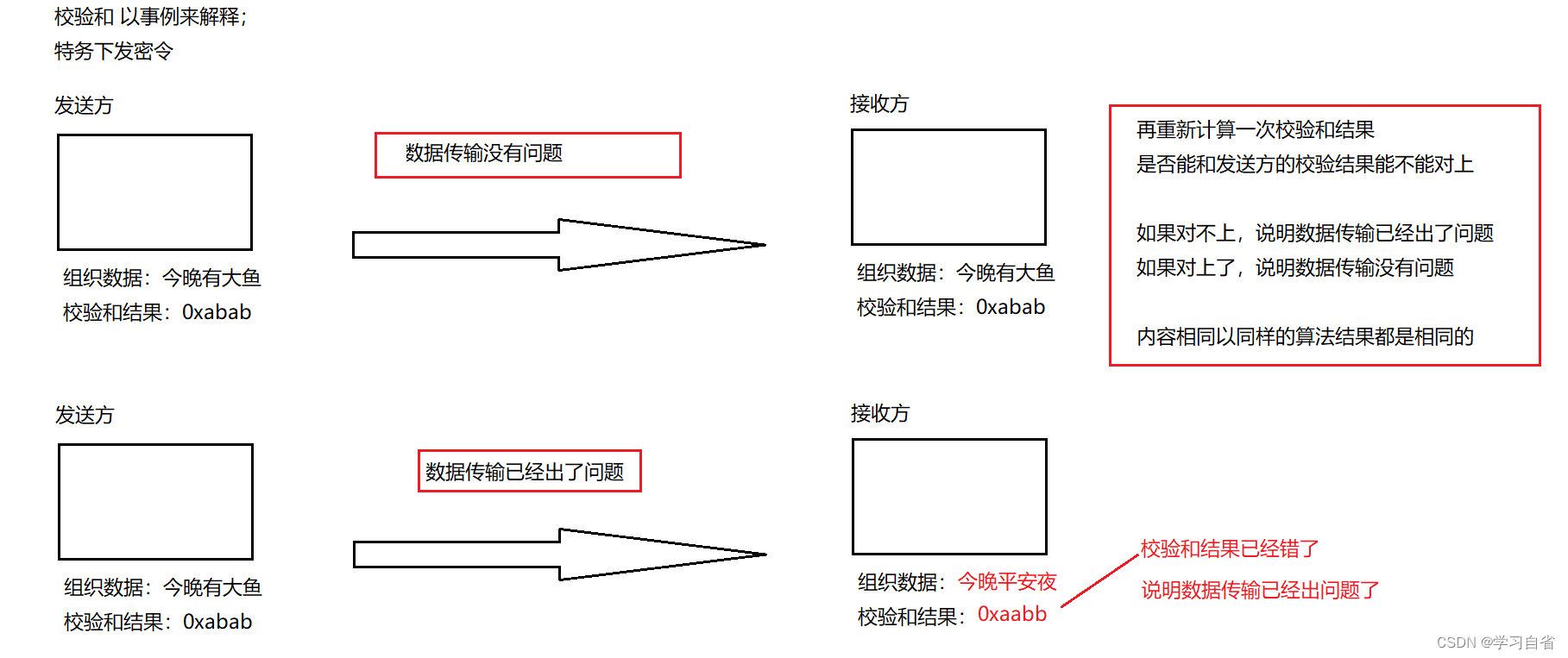
注:发送方把要发送的数据计算出校验和(checksum1);接收方,收到数据就把数据按照同样的方式再算一次校验和(checksum2),同时接收方也收到了checksum1(接收方对比checksum1和checksum2是否相同)
以上已经涉及了正常情况;
特殊情况:假设数据传输过程中出错了,但是计算机得到的校验和与之前的校验和恰好一样??
也就是说 发送方其他的组织数据经过处理后得到的校验和与“今晚有大鱼”这个组织数据得到了一样的校验和
这个情况理论是上存在,实际上应用概率太小可以忽略不计
如果内容相同,得到的校验和结果一定相同,校验和相同,原始内容不一定相同(以上特殊情况),但特殊情况在实际中概率实在太小了,所以一般认为校验和相同,原始内容也相同
校验和如何校验??
细致的校验和一般会和内容相关联
基于数据内容算出来的校验和,内容一旦有变换就能发现
举个例子:还是以刚刚组织数据 “今晚有大鱼” ,校验和相关每个字符,即便组织数据修改一个字“今晚无大鱼” 一字之差就是不同的校验和
注:实际上网络传输过程中,往往是把数据的所有字节都参与生成校验和的运算,这样任何一个字节出现问题,都能及时发现
针对网络传输的数据来说,生成校验和的算法有很多种
(1)CRC :循环冗余校验,简单粗暴,把数据的每个字节,循环往上累加,如果累加溢出了,高位就不要了。
注:其实这里不难看出缺点,校验结果不是特别理想,万一你的数据同时变动了两个bit位(前一个字节少1,后一个字节多1),就会出现内容变了,CRC没变这样的情况
(2)MD5:不在像CRC 简单相加,有一系列的公式,来进行更复杂的数据运算(数学问题)
MD5算法的特点:
<1>定长: 无论原始数据多长,得到的MD5值都是固定长度(4字节版本,也有8字节版本)
<2>冲突概率很小:原始数据哪怕只变动一个地方,算出来的MD5值都会差别很大
<3>不可逆:通过原始数据计算MD5 很容易。通过MD5还原成原始数据(找到哪个数据生成了这个MD5)很难,但是简单常用的可以通过查表的方式解密
MD5有以上3个特点可以应用在多方面校验和,作为计算Hash值的方式,加密
(3)SHA1:同一样是有一系列的数据运算将长度在2^64bit的消息,输入消息(明文),以512bit的分组为单位处理,输出160bit的消息摘要

















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









