







题目
给定一个整数数组 cost ,其中 cost[i] 是从楼梯第i 个台阶向上爬需要支付的费用,下标从0开始。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
数据范围:数组长度满足 1≤n≤105,数组中的值满足 1≤costi≤104
示例1
输入:
[2,5,20]
返回值:
5
说明:
你将从下标为1的台阶开始,支付5 ,向上爬两个台阶,到达楼梯顶部。总花费为5
示例2
输入:
[1,100,1,1,1,90,1,1,80,1]
返回值:
6
说明:
你将从下标为 0 的台阶开始。
1.支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。
2.支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。
3.支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。
4.支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。
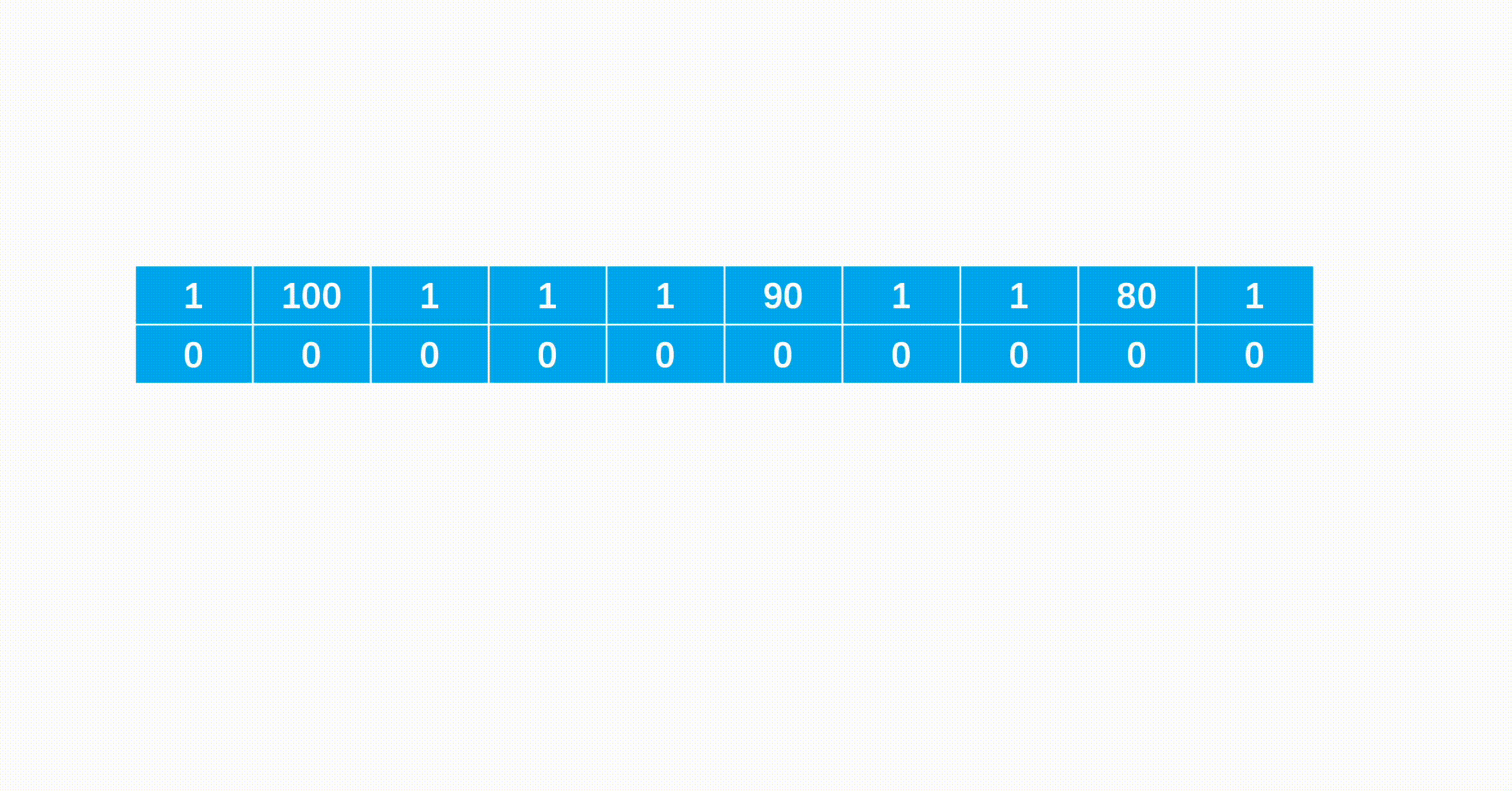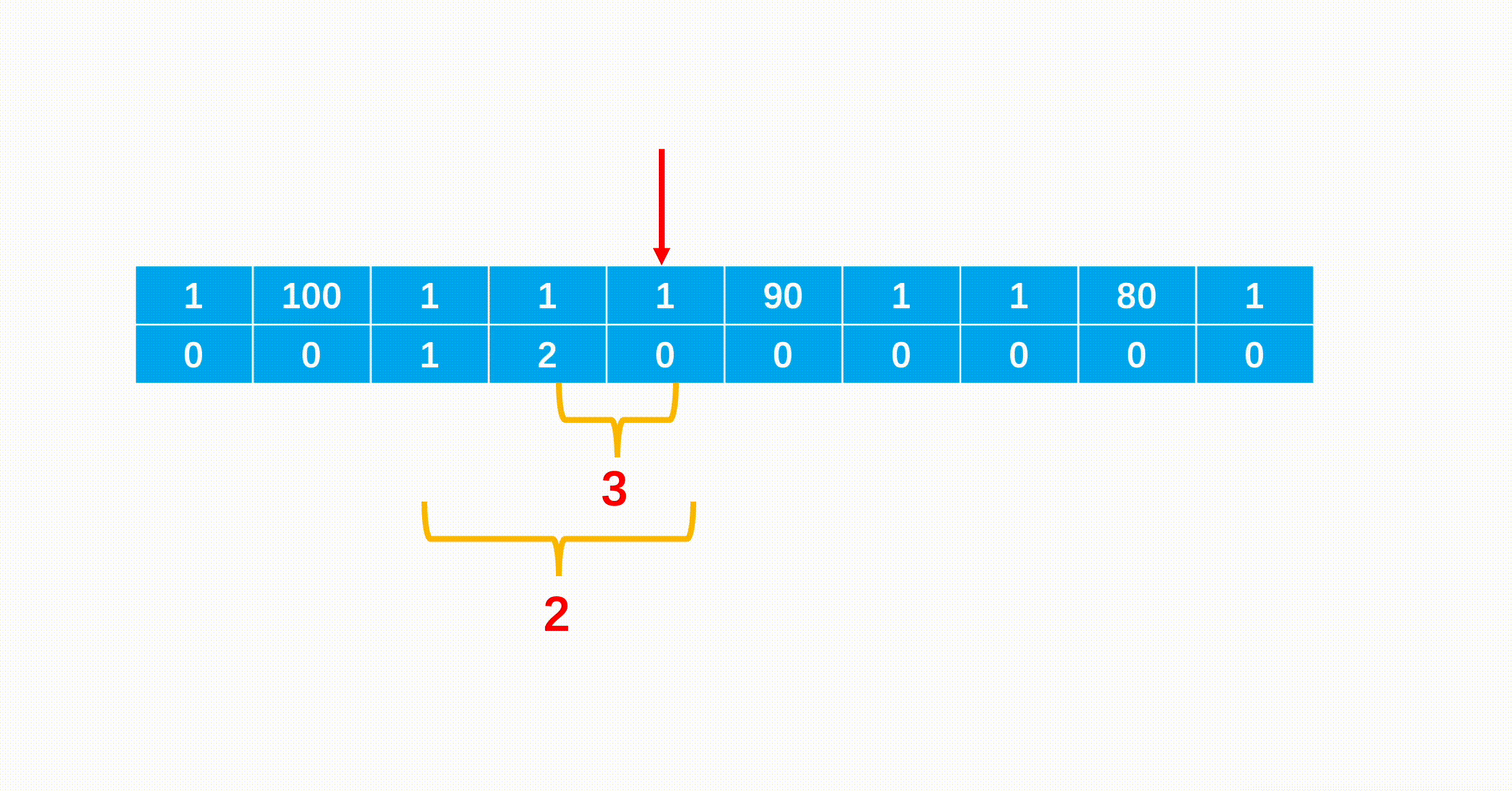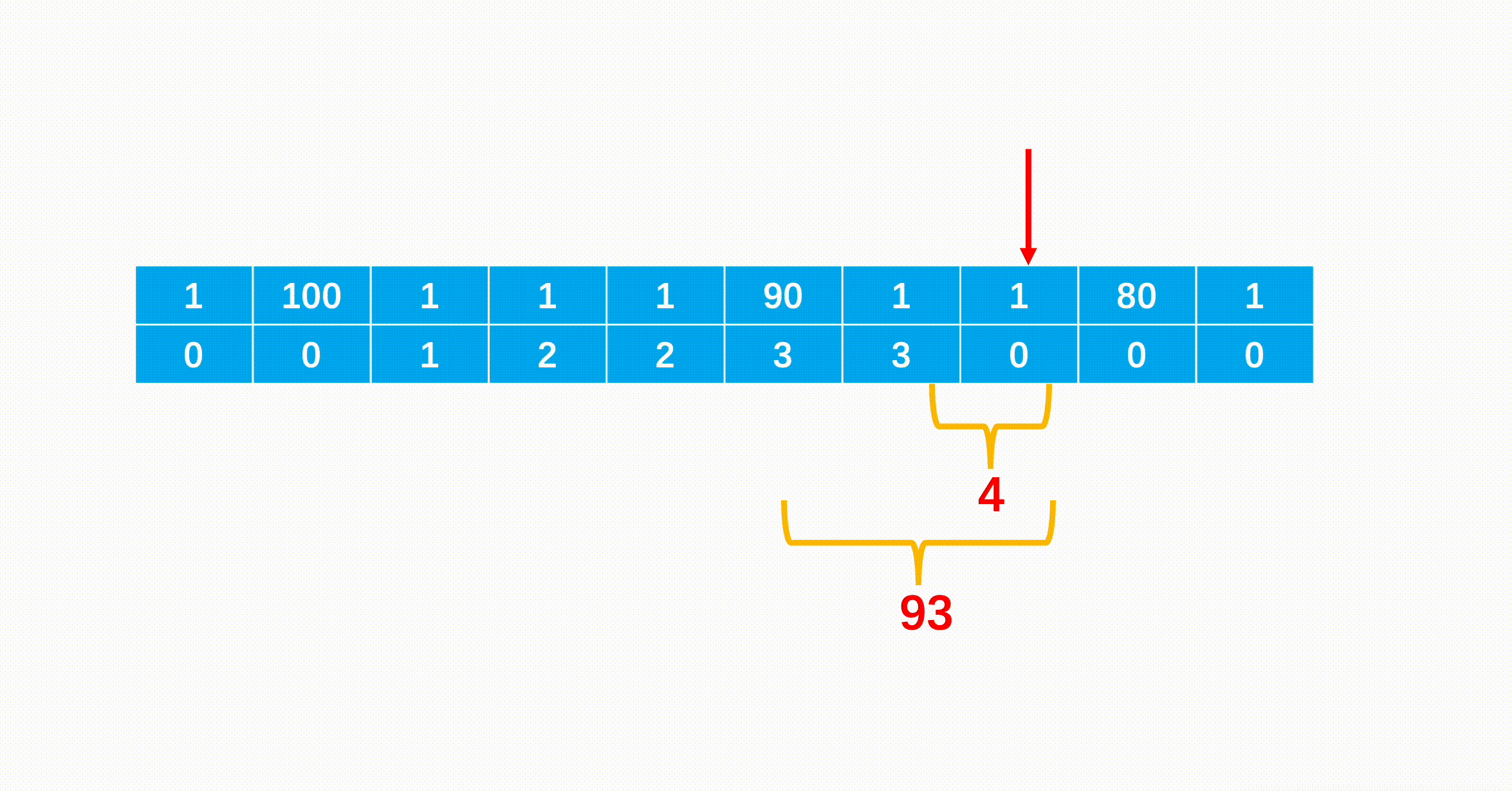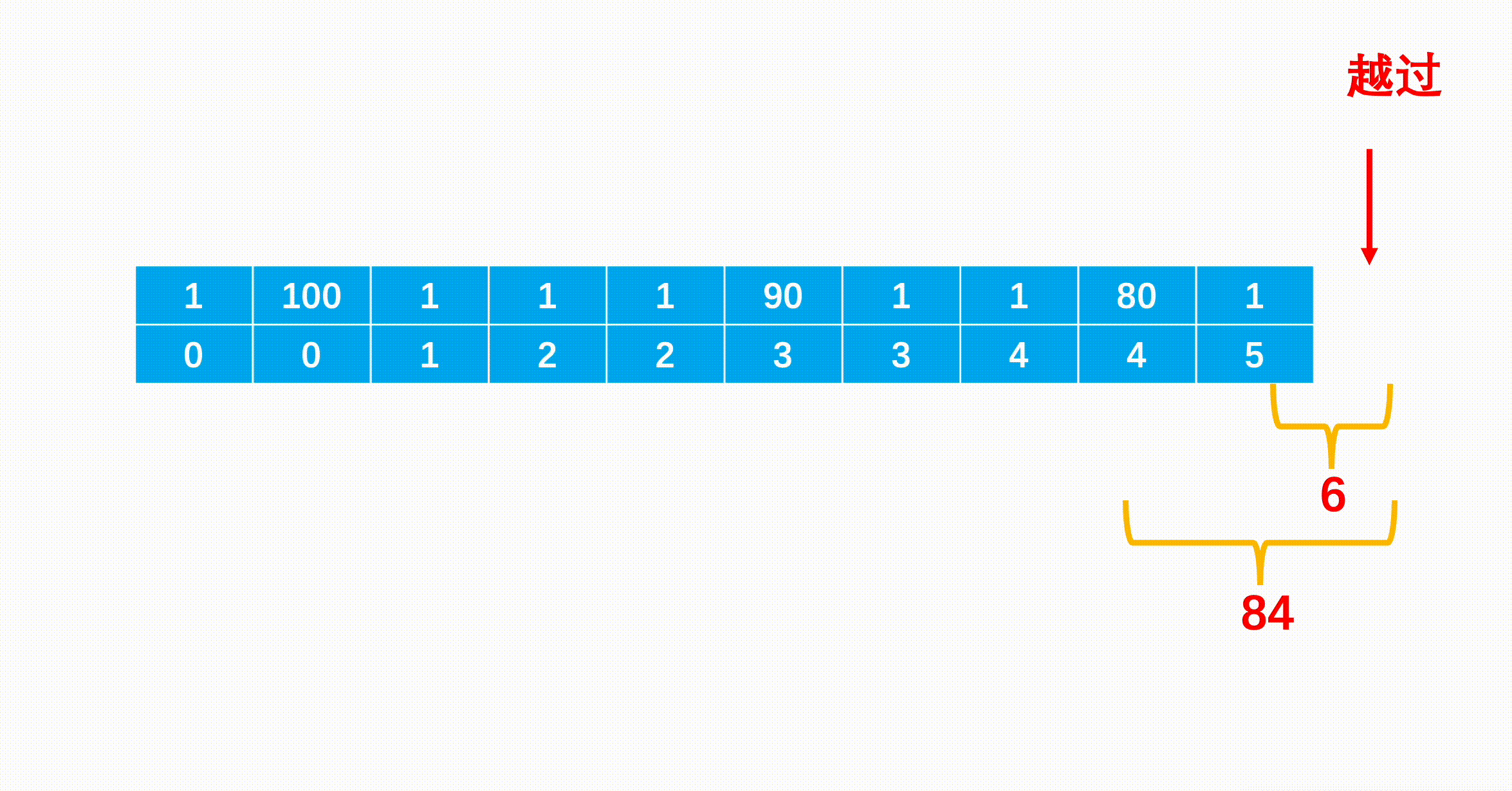
5.支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。
6.支付 1 ,向上爬一个台阶,到达楼梯顶部。
总花费为 6 。
思路
题目考察斐波那契数列的动态规划实现,不同的是题目要求了最小的花费,因此我们将方案统计进行递推的时候只记录最小的开销方案即可。
可以用一个数组记录每次爬到第i阶楼梯的最小花费,然后每增加一级台阶就转移一次状态,最终得到结果。
因为可以直接从第0级或是第1级台阶开始,因此这两级的花费都直接为0。
每次到一个台阶,只有两种情况,要么是它前一级台阶向上一步,要么是它前两级的台阶向上两步,因为在前面的台阶花费我们都得到了,因此每次更新最小值即可,转移方程为:min_cost[i]=min(min_cost[i−1]+cost[i−1],min_cost[i−2]+cost[i−2])。
解答代码
#include <algorithm>
#include <vector>
class Solution {
public:
/**
* @param cost int整型vector
* @return int整型
*/
int minCostClimbingStairs(vector<int>& cost) {
// write code here
auto size = cost.size();
if (size < 3) {
return 0;
}
std::vector<int> min_cost(size+1, 0);//记录每移动一次的最小花费
for (int i = 2; i <= size; i++) {
min_cost[i] = std::min(cost[i-1] + min_cost[i-1], cost[i-2] + min_cost[i-2]);
}
return min_cost[size];
}
};














 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









