







电子邮件
电子邮件的速度是按秒算
电子邮件软件被称为MUA:Mail User Agent——邮件用户代理,emil从MUA发出去,不是直接到达对方电脑,而是发到MTA:mail transfer agent——邮件传输代理,就是那些email服务提供商
email首先到达发送者的mta ,再由发送者的mta发到接收者的mta,这个过程可能还会经过别的mta
email到达发送者的mta后,会把email投递到邮件的最终目的地MDA——mail delivery agent邮件投递代理。到达MDA后,就静静的躺在某个服务器上,存放在某个文件或特殊的数据库里,将长期保存邮件的地方称为电子邮箱
同普通邮件类似,email不会直接到达对方的电脑,因为对方电脑不一定开机,开机也不一定联网,对方要取到邮件,必须通过MUA从MDA上把邮件取到自己的电脑上
编写程序来发送和接收邮件,本质上就是:
1 编写MUA把邮件发到MTA
2 编写MUA从MDA上收邮件
发邮件时,MUA和MTA使用的协议就是SMTP:simple mail transfer protocol,后面的MTA到另一个mta也是用SMTP协议
收邮件时,mua和mda使用的协议有两种:POP:post office protocol,IMAP:internet message access protocol,优点是不但能取邮件们还可以直接操作mda上存储的邮件,比如从收件箱移到垃圾箱
邮件客户端软件再发邮件时,会让你先配置SMTP服务器,也就是要发到哪个MTA上。
假设你正在使用163的邮箱,就不能直接发到新浪的mta上,因为他只服务新浪的用户,所以,要填163提供的smtp服务器地址smtp.163.com,为了整明你是163的用户,smtp服务器还要求你填写邮箱地址和邮箱口令,这样mua才能正常的把email通过SMTP协议发送到mta
类似的盲从MDA收邮件时,MDA服务器也要求验证你的邮箱口令,确保不会有人冒充你收取你的邮件,所以,outlook之类的邮件客户端会要求你填写POP3或者IMAP服务器地址,邮箱地址和口令,mua才能顺利的通过pop或imap协议从mda取到邮件
在使用python收发邮件前,准备好至少两个电子邮件,如xxx@163.com,xxx@sina.com等,两个邮箱不要用同一家邮件服务商
目前大多数邮件服务商都需要手动打开smtp发信和pop收信的功能,否则只允许再网页登录
SMTP发送邮件
SMTP是发送邮件的协议,python内置对SMTP的支持可以发送纯文本邮件,HTML邮件以及带附件的邮件
python对smtp支持有smtplib和email两个模块,email负责构造邮件,smtplib负责发送邮件
构造一个最简单的纯文本邮件:
from email.mime.text import MIMEText
msg = MIMEText('hello, send by Python...', 'plain', 'utf-8')沟造MIMEText对象时,第一个参数就是邮件正文,第二个参数时MIME的subtype,传入’plain’表示纯文本,最终的MIME就是‘text/plain’,最后一定要用utf-8编码保证多语言兼容性
通过SMTP发出去:
# 输入Email地址和口令:
from_addr = input('From: ')
password = input('Password: ')
# 输入收件人地址:
to_addr = input('To: ')
# 输入SMTP服务器地址:
smtp_server = input('SMTP server: ')
import smtplib
server = smtplib.SMTP(smtp_server, 25) # SMTP协议默认端口是25
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()用set_debuglevel(1)就可以打印出和SMTP服务器交互的所有信息。
SMTP协议就是简单的文本命令和响应
login()方法用来登录SMTP服务器,sendmail()方法就是发邮件,由于可以一次发给多个人,所以传入一个list,邮件正文是一个str,as_string()把MIMEText对象变成str
如果顺利 就可以在收件人信箱中收到刚发送的email:
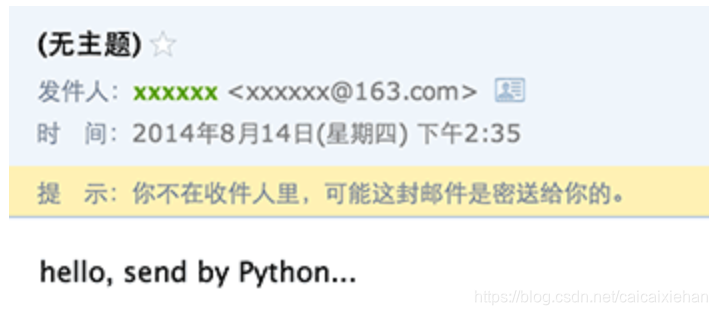
1 邮件没有主题
2 收件人的名字没有显示为好友的名字
3 命名收到了邮件,却提示不在收件人中
因为邮件主题,如何显示发件人,收件人等信息并不是通过SMTP协议发给MTA,而是包含在发给MTA的文本中的,所以,必须把From,To和Subject添加到MIMEText中,才是一封完整的邮件:
from email import encoders
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, 'utf-8').encode(), addr))
from_addr = input('From: ')
password = input('Password: ')
to_addr = input('To: ')
smtp_server = input('SMTP server: ')
msg = MIMEText('hello, send by Python...', 'plain', 'utf-8')
msg['From'] = _format_addr('Python爱好者 <%s>' % from_addr)
msg['To'] = _format_addr('管理员 <%s>' % to_addr)
msg['Subject'] = Header('来自SMTP的问候……', 'utf-8').encode()
server = smtplib.SMTP(smtp_server, 25)
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()编写了一个函数_format_addr()来格式化一个邮件地址。不能简单地传入nameaddr@example.com,如果包含中文,需要通过Header对象进行编码。
msg[‘To’]接收的是字符串而不是list,如果有多个邮件地址,用,分割。
查看email的原始内容,可以看到经过编码的邮件头:
From: =?utf-8?b?UHl0aG9u54ix5aW96ICF?= <xxxxxx@163.com>
To: =?utf-8?b?566h55CG5ZGY?= <xxxxxx@qq.com>
Subject: =?utf-8?b?5p2l6IeqU01UUOeahOmXruWAmeKApuKApg==?=这是经过Header对象编码的文本,包含utf-8编码信息和Base64编码的文本。
发送HTML邮件
如果发送HTML邮件,并不是普通的纯文本,在构造MIMEText对象时,把HTML字符串传进去,再把第二个参数由plain变为html
msg = MIMEText('<html><body><h1>Hello</h1>' +
'<p>send by <a href="http://www.python.org">Python</a>...</p>' +
'</body></html>', 'html', 'utf-8')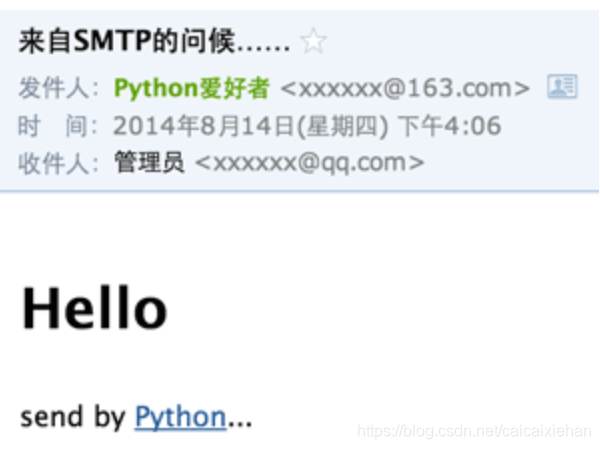
发送邮件
如果email中要加上附件,带附件的邮件可以看作包含若干部分的邮件:文本和各个附件本身。可以构造一个MIMEMultipart对象代表邮件本身,然后往里面加上一个MIMEText作为邮件正文,再继续往里面加上表示附件的MIMEBase对象:
# 邮件对象:
msg = MIMEMultipart()
msg['From'] = _format_addr('Python爱好者 <%s>' % from_addr)
msg['To'] = _format_addr('管理员 <%s>' % to_addr)
msg['Subject'] = Header('来自SMTP的问候……', 'utf-8').encode()
# 邮件正文是MIMEText:
msg.attach(MIMEText('send with file...', 'plain', 'utf-8'))
# 添加附件就是加上一个MIMEBase,从本地读取一个图片:
with open('/Users/michael/Downloads/test.png', 'rb') as f:
# 设置附件的MIME和文件名,这里是png类型:
mime = MIMEBase('image', 'png', filename='test.png')
# 加上必要的头信息:
mime.add_header('Content-Disposition', 'attachment', filename='test.png')
mime.add_header('Content-ID', '<0>')
mime.add_header('X-Attachment-Id', '0')
# 把附件的内容读进来:
mime.set_payload(f.read())
# 用Base64编码:
encoders.encode_base64(mime)
# 添加到MIMEMultipart:
msg.attach(mime)然后按正常发送流程把msg(类型已变为MIMEMultipart)发送出去
发送图片
把一个图片嵌入到邮件正文中,或者直接在Html邮件中连接图片地址。大部分邮件服务商都会自动屏蔽带有外链的图片,因为不知道这些链接是否指向恶意网站
要把图片嵌入到邮件正文中,只需要按照发送附件的方式,先把邮件作为附件添加进去,然后再Html中通过引用src=”cid:0“就可以把附件作为图片嵌入了。如果有多个图片,给他们依次编号,然后引用不同的cid:x即可
把上面代码加入MIMEMultipart的MIMEText从plain改为html,然后在适当的位置引用图片:
msg.attach(MIMEText('<html><body><h1>Hello</h1>' +
'<p><img src="cid:0"></p>' +
'</body></html>', 'html', 'utf-8'))同时支持HTML和Plain格式
如果发送html邮件,收件人通过浏览器或者outlook之类的软件是可以正常浏览邮件内容的,但是如果收件人使用的设备太古老,查看不了html邮件就是在发送html的同时再附加一个纯文本,如果收件人无法查看html格式的邮件,就可以自动降级查看纯文本邮件
利用MIMEMultipart就可以组合一个html和plain,指定的subtype是alternative:
msg = MIMEMultipart('alternative')
msg['From'] = ...
msg['To'] = ...
msg['Subject'] = ...
msg.attach(MIMEText('hello', 'plain', 'utf-8'))
msg.attach(MIMEText('<html><body><h1>Hello</h1></body></html>', 'html', 'utf-8'))
# 正常发送msg对象...加密SMTP
使用标准的25端口连接SMTP服务器时,使用的是明文传输,发送邮件的整个过程可能会被窃听。要更安全的发送邮件,可以加密smtp会话,实际上就是先创建ssl安全连接,然后再使用smtp协议发送邮件
某些邮件服务商,例如Gmail,提供的SMTP服务必须要加密传输
Gmail的SMTP端口是587:
smtp_server = 'smtp.gmail.com'
smtp_port = 587
server = smtplib.SMTP(smtp_server, smtp_port)
server.starttls()
# 剩下的代码和前面的一模一样:
server.set_debuglevel(1)
...只需要在创建smtp对象后,立刻调用starttls()方法,就创建了安全连接。后面的代码和前面的发送邮件代码完全一样
如果因为网络问题无法连接Gmail的SMTP服务器,需要对网络设置做调整
使用python的smtplib发送邮件十分简单,掌握了各种邮件类型的构造方法,正确设置好邮件头,就可以顺利发出
构造一个邮件对象就是一个messag对象,如果构造一个MIMEText对象,就表示一个文本邮件对象,如果构造一个MIMEImage对象,就表示一个作为附件的图片,要把多个对象组合起来,就用MIMEMultipart对象,而MIMEBase可以表示任何对象
继承关系:
Message
+- MIMEBase
+- MIMEMultipart
+- MIMENonMultipart
+- MIMEMessage
+- MIMEText
+- MIMEImagePOP3收取邮件
收取邮件就是编写一个MUA作为客户端,从MDA把邮件获取到用户的电脑或者手机上
收取邮件最常用的协议是POP协议
python内置一个poplib模块,实现了POP3协议,可以直接用来收邮件
pop3协议收取的不是一个已经可以阅读的邮件本身,而是邮件的原始文本,这和SMTP协议很像,SMTP发送的也是经过编码后的一大段文本。
要把pop3收取的文本变成可以阅读的邮件,还需要用Email模块提供的各类来解析原始文本,变成可阅读的邮件对象
收取邮件分两步:
1 用poplib把邮件的原始文本下载到本地
2 用email解析原始文本,还原为邮件对象
通过POP3下载邮件
POP3协议本身很简单,以下面的代码为例,获取最新的一封邮件内容:
import poplib
# 输入邮件地址, 口令和POP3服务器地址:
email = input('Email: ')
password = input('Password: ')
pop3_server = input('POP3 server: ')
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 可以打开或关闭调试信息:
server.set_debuglevel(1)
# 可选:打印POP3服务器的欢迎文字:
print(server.getwelcome().decode('utf-8'))
# 身份认证:
server.user(email)
server.pass_(password)
# stat()返回邮件数量和占用空间:
print('Messages: %s. Size: %s' % server.stat())
# list()返回所有邮件的编号:
resp, mails, octets = server.list()
# 可以查看返回的列表类似[b'1 82923', b'2 2184', ...]
print(mails)
# 获取最新一封邮件, 注意索引号从1开始:
index = len(mails)
resp, lines, octets = server.retr(index)
# lines存储了邮件的原始文本的每一行,
# 可以获得整个邮件的原始文本:
msg_content = b'\r\n'.join(lines).decode('utf-8')
# 稍后解析出邮件:
msg = Parser().parsestr(msg_content)
# 可以根据邮件索引号直接从服务器删除邮件:
# server.dele(index)
# 关闭连接:
server.quit()用pop3获取邮件其实很简单,要获取所有邮件,只需要循环使用retr()把每一封邮件内容拿到即可。
解析邮件
解析邮件的过程和构造邮件正好相反
先导入必要的模块:
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
import poplib
msg = Parser().parsestr(msg_content)把邮件内容解析为Message对象
但是这个Message对象本身可能是一个MIMEMutipart对象,即包含嵌套的其他MIMEBase对象,嵌套可能还不止一层。
递归的打印出Message对象的层次结构:
# indent用于缩进显示:
def print_info(msg, indent=0):
if indent == 0:
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header=='Subject':
value = decode_str(value)
else:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
print('%s%s: %s' % (' ' * indent, header, value))
if (msg.is_multipart()):
parts = msg.get_payload()
for n, part in enumerate(parts):
print('%spart %s' % (' ' * indent, n))
print('%s--------------------' % (' ' * indent))
print_info(part, indent + 1)
else:
content_type = msg.get_content_type()
if content_type=='text/plain' or content_type=='text/html':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
print('%sText: %s' % (' ' * indent, content + '...'))
else:
print('%sAttachment: %s' % (' ' * indent, content_type))邮件的Subject或者Email中包含的名字都是经过编码后的str,要正常显示,就必须decode:
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return valuedecode_header()返回一个list,因为像Cc,Bcc这样的字段可能包含多个邮件地址,所以解析出来的会有多个元素。
文本邮件的内容也是str,还需要检测编码,否则,非UTF-8编码的邮件都无法正常显示:
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset收取一封邮件,先往自己的邮箱发一封邮件,然后用浏览器登录邮箱看看邮件收到没,如果收到了,就用python程序把它收到本地
运行程序,结果:
+OK Welcome to coremail Mail Pop3 Server (163coms[...])
Messages: 126. Size: 27228317
From: Test <xxxxxx@qq.com>
To: Python爱好者 <xxxxxx@163.com>
Subject: 用POP3收取邮件
part 0
--------------------
part 0
--------------------
Text: Python可以使用POP3收取邮件……...
part 1
--------------------
Text: Python可以<a href="...">使用POP3</a>收取邮件……...
part 1
--------------------
Attachment: application/octet-stream从打印的结构可以看出,这封邮件室一个MIMEMultipart,包含两部分:第一部分就是一个MIMEMultipart,第二部分是一个附件。内嵌的MIMEMultipart是一个alternative类型,包含一个纯文本格式的MIMEText和一个HTML格式的MIMEText
访问数据库
程序运行的时候,数据都是在内存中的。当程序终止的时候,通常都需要将数据保存到磁盘上,无论是保存到本地磁盘还是通过网络保存到服务器上,最终都会将数据写入磁盘文件。
定义数据的存储格式
可以用一个文本文件保存:
Michael,99
Bob,85
Bart,59
Lisa,87还可以用JSON格式保存
[
{"name":"Michael","score":99},
{"name":"Bob","score":85},
{"name":"Bart","score":59},
{"name":"Lisa","score":87}
]还可以定义各种保存格式
存储和读取需要自己实现,JSON还是标准,自己定义的格式就各式各样了
不能做快速查询,只有把数据全部读到内存中才能自己遍历,但有时候,数据的大小远远超过了内存,根本无法全部读入内存
为了便于程序保存和读取数据,而且,能直接通过条件快速查询到指定的数据,就出现了数据库(database)这种专门用于几种存储和查询的软件
数据库经历了网状数据,层次数据库,到现在的关系数据库
在关系数据库中,基于表的一对多的关系就是关系数据库的基础
查询语句在关系数据库中称为SQL语句:
SELECT * FROM classes WHERE grade_id = '1';结果也是一个表:
---------+----------+----------
grade_id | class_id | name
---------+----------+----------
1 | 11 | 一年级一班
---------+----------+----------
1 | 12 | 一年级二班
---------+----------+----------
1 | 13 | 一年级三班
---------+----------+----------NoSQL
数据库类别
付费的商用数据库:
Oracle
SQL Server 微软产品,windows定制专款
DB2,IBM的产品
Sybase
这些数据库都是不开源而且付费,最大的好处是花了钱除了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,所以无论是Google,Facebook,还是国内的Bat都选择了免费的开源数据库
MySQL
PostgreSQL
sqlite 嵌入式数据库,适合桌面和移动应用
使用SQLite
SQLite是一种嵌入式数据库,它的数据库就是一个文件。
由于sqlite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的app中都可以集成
python内置了SQLite3,在python中使用SQLite不需要安装任何东西,可以直接使用
表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,表和表之间通过外键关联
要操作关系数据库,首先需要连接到数据库,一个数据库连接称为connection
连接到数据库后,需要打开游标,称之为cursor,通过cursor执行SQL语句,然后获得执行结果
python定义了一套操作数据库的API接口,任何数据库要连接到python,只需要提供符合python标准的数据库驱动即可
交互式命令行实践:
# 导入SQLite驱动:
>>> import sqlite3
# 连接到SQLite数据库
# 数据库文件是test.db
# 如果文件不存在,会自动在当前目录创建:
>>> conn = sqlite3.connect('test.db')
# 创建一个Cursor:
>>> cursor = conn.cursor()
# 执行一条SQL语句,创建user表:
>>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
<sqlite3.Cursor object at 0x10f8aa260>
# 继续执行一条SQL语句,插入一条记录:
>>> cursor.execute('insert into user (id, name) values (\'1\', \'Michael\')')
<sqlite3.Cursor object at 0x10f8aa260>
# 通过rowcount获得插入的行数:
>>> cursor.rowcount
1
# 关闭Cursor:
>>> cursor.close()
# 提交事务:
>>> conn.commit()
# 关闭Connection:
>>> conn.close()查询记录:
>>> conn = sqlite3.connect('test.db')
>>> cursor = conn.cursor()
# 执行查询语句:
>>> cursor.execute('select * from user where id=?', ('1',))
<sqlite3.Cursor object at 0x10f8aa340>
# 获得查询结果集:
>>> values = cursor.fetchall()
>>> values
[('1', 'Michael')]
>>> cursor.close()
>>> conn.close()使用python的DB-API时,只要搞清楚connection和cursor对象,打开后一定记得关闭,就可以放心的使用
使用cursor对象执行insert,update,delete语句时,执行结果rowcount返回影响的行数,就可以拿到执行结果
使用cursor对象执行select语句时,通过fetchall()可以拿到结果集。结果是一个list,每个元素都是一个tuple,对应一行记录
如果sql语句带有参数,那么需要把参数按照位置传递给execute()方法,有几个?占位符就必须对应几个参数:
cursor.execute('select * from user where name=? and pwd=?', ('abc', 'password'))SQLite支持常见的标准SQL语句以及几种常见的数据类型
python操作数据库时,要先导入数据库对应的驱动,然后通过connection对象和cursor对象操作数据
要确保打开的connection对象和cursor对象都正确的被关闭,否则资源就会泄露
(练习)
使用Mysql
MySQL时web世界中最广泛使用的数据库服务器。SQLite的特点时轻量级,可嵌入,但不能承受高并发访问,适合桌面和移动应用。
MySQL是为服务器端设计的数据库,能承受高并发访问,同时占用的内存也远远大于SQLite
MySQL内部有多种数据库引擎,最常用的引擎室支持数据库事务的InnoDB
安装MySQL
可以直接从MySQL官方网站下载。MySQL室跨平台的,选择对应的平台下载安装文件
安装时MySQL会提示输入root用户的口令
mac/linux上,需要编辑mysql的配置文件,把数据库默认的编码全部改为UTF-8
配置文件默认存放在/etc/my.cnf或者/etc/mysql/my.cnf:
[client]
default-character-set = utf8
[mysqld]
default-storage-engine = INNODB
character-set-server = utf8
collation-server = utf8_general_ci重启mysql后,可以通过mysql的客户端命令检查编码:
$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor...
...
mysql> show variables like '%char%';
+--------------------------+--------------------------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql-5.1.65-osx10.6-x86_64/share/charsets/ |
+--------------------------+--------------------------------------------------------+
8 rows in set (0.00 sec)如果mysql的版本>5.5.3可以把编码设置为utf8mb4,支持最新的Unicode标准,可以显示emoji字符
安装MySQL驱动
由于mysql服务器以独立的进程运行,并通过网络对外服务,所以,需要支持python的MySQL驱动来连接到MySQL服务器。
MySQL官方提供了mysql-connector-python驱动,但是安装的时候需要给pip命令加上参数–allow-external:
$ pip install mysql-connector-python --allow-external mysql-connector-python
#或者
$ pip install mysql-connector连接到MySQL服务器:
# 导入MySQL驱动:
>>> import mysql.connector
# 注意把password设为你的root口令:
>>> conn = mysql.connector.connect(user='root', password='password', database='test')
>>> cursor = conn.cursor()
# 创建user表:
>>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
# 插入一行记录,注意MySQL的占位符是%s:
>>> cursor.execute('insert into user (id, name) values (%s, %s)', ['1', 'Michael'])
>>> cursor.rowcount
1
# 提交事务:
>>> conn.commit()
>>> cursor.close()
# 运行查询:
>>> cursor = conn.cursor()
>>> cursor.execute('select * from user where id = %s', ('1',))
>>> values = cursor.fetchall()
>>> values
[('1', 'Michael')]
# 关闭Cursor和Connection:
>>> cursor.close()
True
>>> conn.close()由于python的DB-API定义都是通用的,所以操作MySQL的数据库代码和SQLite类似
执行insert等操作后要调用commit()提交事务
MySQL的sql占位符是%s
使用sqlAIchemy
数据库表是一个二维表,包含多行多列。把一个表的内容用python的数据结果表示出来的话,可以用一个list表示多行,list的每个元素是tuple,表示一行记录
[
('1', 'Michael'),
('2', 'Bob'),
('3', 'Adam')
]python的DB-API返回的数据结构就是像上面这样表示的
但是用tuple表示一行很难看出表的结构。
把一个tuple用class实例来表示,就可以更容易的看出表的结构:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User('1', 'Michael'),
User('2', 'Bob'),
User('3', 'Adam')
]ORM技术:object-relational mapping,把关系数据库的表结构映射到对象上
在python中,最有名的ORM框架是
通过pip安装SQLAlchemy:
$ pip install sqlalchemy导入SQLAlchemy,并初始化DBSession:
# 导入:
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类:
Base = declarative_base()
# 定义User对象:
class User(Base):
# 表的名字:
__tablename__ = 'user'
# 表的结构:
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库连接:
engine = create_engine('mysql+mysqlconnector://root:password@localhost:3306/test')
# 创建DBSession类型:
DBSession = sessionmaker(bind=engine)以上代码完成SQLAlchemy的初始化和具体每个表的class定义。
如果有多个表,就继续定义其他class:
class School(Base):
__tablename__ = 'school'
id = ...
name = ...create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'只需要根据需要替换掉用户名,口令等信息
向数据库表中添加一行记录,可以视为添加一个user对象:
# 创建session对象:
session = DBSession()
# 创建新User对象:
new_user = User(id='5', name='Bob')
# 添加到session:
session.add(new_user)
# 提交即保存到数据库:
session.commit()
# 关闭session:
session.close()关键是获取session,然后把对象添加到session,最后提交并关闭。
DBSession对象可视为当前数据库连接。
从数据库表中查询数据,有了ORM,查询出来的可以不再是tuple,而是user对象。
查询接口:
# 创建Session:
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
user = session.query(User).filter(User.id=='5').one()
# 打印类型和对象的name属性:
print('type:', type(user))
print('name:', user.name)
# 关闭Session:
session.close()运行结果:
type: <class '__main__.User'>
name: BobORM就是把数据库表的行与相应的对象建立关联,互相转换
由于关系的数据库的多个表还可以用外键实现一对多,多对多等关联,相应的,ORM框架也可以提供两个对象之间的一对多,多对多功能
user拥有多个book,就可以定义一对多关系:
class User(Base):
__tablename__ = 'user'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 一对多:
books = relationship('Book')
class Book(Base):
__tablename__ = 'book'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# “多”的一方的book表是通过外键关联到user表的:
user_id = Column(String(20), ForeignKey('user.id'))当查询一个user对象时,该对象的books属性将返回一个包含若干个Book对象的list
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









