








一个简单的半监督少样本学习方法
引用:Wei, Xiu-Shen, et al. “An embarrassingly simple approach to semi-supervised few-shot learning.” Advances in Neural Information Processing Systems 35 (2022): 14489-14500.
论文地址:下载地址
Abstract
半监督小样本学习旨在训练一个分类器,使其能够适应新任务,尽管只有有限的标记数据和一定量的未标记数据。为了解决这一问题,已经提出了许多复杂的方法。在本文中,我们提出了一种简单但非常有效的方法,从间接学习的角度出发,预测未标记数据的准确负伪标签,进而增强小样本分类任务中极为受限的支持集。我们的方法只需几行代码即可实现,且仅使用现成的操作,尽管如此,它仍能够在四个基准数据集上超越现有的最先进方法。
1 Introduction
深度学习 1 使得由多个处理层组成的计算模型能够学习具有多层次抽象的数据表示,已经在许多计算机视觉任务中展示了其强大的能力,例如物体识别 2、细粒度分类 3、物体检测 4 等。然而,基于深度学习的模型通常需要大量的监督数据才能获得良好的泛化性能。小样本学习(FSL)5 作为一种缓解标签依赖的重要技术,近年来受到了广泛关注。它形成了几种学习范式,包括基于度量的方法 6 7 8、基于优化的方法 9 10 11 和基于迁移学习的方法 12 13。
最近,值得注意的是,在小样本学习(FSL)领域,已经有大量研究探讨如何利用未标记数据在少量监督下提升模型性能,这就是半监督小样本学习(SSFSL)14 15 16 17 18 19。SSFSL 最流行的方式是通过精心设计定制的策略,预测未标记数据的伪标签,然后增强小样本分类任务中极为有限的标记数据支持集,例如 14 15 18。在本文中,我们遵循这一方式,提出了一种简单但非常有效的SSFSL方法,即逐步排除法(MUSIC),参见图 1。
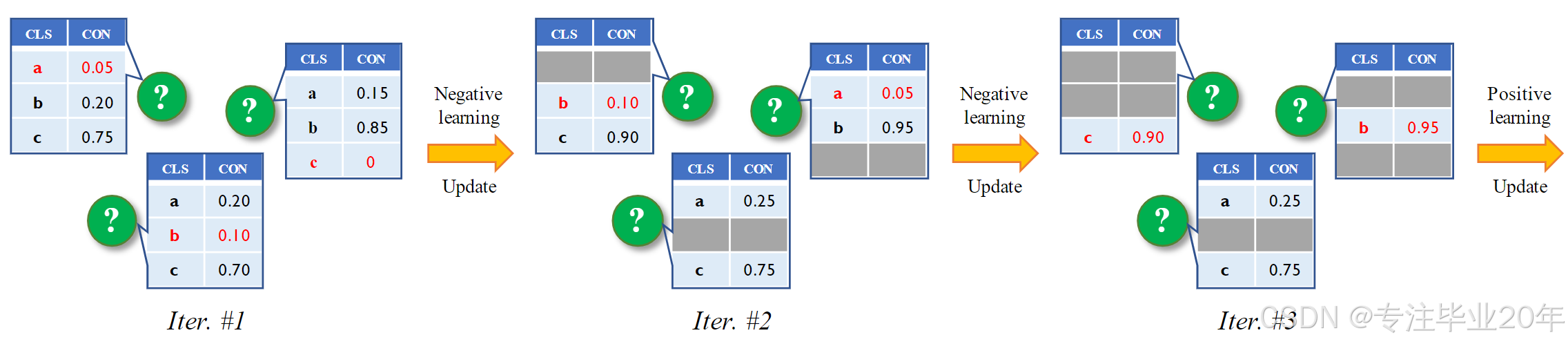 图 1. 我们提出的 MUSIC 方法的流程,以 3 类少样本分类为例:具体来说,绿色的数据点(带有问号标记)是 SSFSL 中的未标记数据,“CLS” 表示数据的类别,“CON” 代表对应伪标签的预测置信度。在每次迭代中,我们用红色高亮显示被选中的(负/正)伪标签,并在后续迭代中排除该类别。需要注意的是,底部的未标记数据由于我们的拒绝选项策略(
δ
=
0.2
\delta = 0.2
δ=0.2,参见公式 (4))未被返回为最终的正类标签。
图 1. 我们提出的 MUSIC 方法的流程,以 3 类少样本分类为例:具体来说,绿色的数据点(带有问号标记)是 SSFSL 中的未标记数据,“CLS” 表示数据的类别,“CON” 代表对应伪标签的预测置信度。在每次迭代中,我们用红色高亮显示被选中的(负/正)伪标签,并在后续迭代中排除该类别。需要注意的是,底部的未标记数据由于我们的拒绝选项策略(
δ
=
0.2
\delta = 0.2
δ=0.2,参见公式 (4))未被返回为最终的正类标签。
正如你所想,在这样的标签受限任务中,例如 1-shot 分类,学习一个好的分类器将会非常困难,因此无法获得足够准确的伪标签。因此,我们反过来思考这个问题,并将半监督小样本学习(SSFSL)中的伪标签过程看作一系列逐步排除操作。具体而言,由于很难标注未标记数据属于哪个类别,相反,根据最低置信度的预测分数,预测它不属于哪个类别应该相对容易。因此,如果我们将之前传统方法中预测的伪标签视为标记的正标签,那么我们的排除操作就是将负伪标签分配给未标记数据。接下来,我们可以使用负学习范式 20 来更新分类器参数,并继续通过排除上一轮预测的负标签来进行负伪标签过程,直到所有负伪标签都被获得。此外,显然可以发现,当未标记数据的所有负标签被顺序排除并标记时,它们的正伪标签也会被获得。通过这种方式,我们最终可以使用正伪标签来增强小支持集,并充分利用SSFSL中来自标记的基类数据和未标记的新类数据的辅助信息。此外,在我们的 MUSIC 方法中,为了进一步提高小样本分类的准确性,我们在逐步排除操作中加入了最小熵损失,以增强正负标签的预测置信度。
总之,本文的主要贡献如下:
- 我们提出了一种简单但有效的方法,即 MUSIC,来处理半监督小样本分类任务。据我们所知,MUSIC 是第一个利用负学习作为一种直接方式,在这种极为受限的标签场景中提供尽可能高置信度伪标签的方法。
- 我们可以仅使用现成的深度学习计算操作来实现所提出的方法,并且只需几行代码即可实现。此外,我们还提供了 MUSIC 方法中超参数的默认值推荐,并通过多种 SSFSL 任务进一步验证了其强大的实用性和泛化能力。
- 我们在四个小样本基准数据集上进行了全面的实验,分别是 miniImageNet、tieredImageNet、CIFAR-FS 和 CUB,展示了我们的方法优于现有的最先进 FSL 和 SSFSL 方法。此外,我们还进行了系列消融实验和讨论,探讨了我们方法中每个组件的工作机制。
2 Related Work
2.1 Few-shot learning
小样本学习的研究 9 6 7 21 8 旨在探索赋予学习系统快速学习新类别的能力,从少量样本中学习。在文献中,小样本学习方法大致可以分为两类:1)基于元学习的方法,2)基于迁移学习的方法。
关于基于元学习的方法,也称为“学习如何学习”,有两种流行的学习范式,即基于度量的方法 6 7 8 和基于优化的方法 9 10 11。更具体地,Prototypical Networks 6 作为一种经典的基于度量的方法,旨在生成一个嵌入空间,在其中数据点围绕每个类别的单一原型表示进行聚类。DeepEMD 8 提出了采用地球移动者距离(Earth Mover’s Distance)作为度量,计算密集图像表示之间的结构距离,以确定图像在小样本学习中的相关性。对于基于优化的方法,MAML 9 学习了一种优化方法,沿着快速梯度方向快速学习新类别的分类器。在 10 中,它将参数更新重新表述为LSTM,并通过元学习器实现。
关于基于迁移学习的方法,预计它们利用技术通过在基类的大量数据上进行预训练模型,而无需使用 episodic training 策略。预训练的模型随后用于识别小样本分类中的新类别。具体来说,13 提出了在小样本学习过程中直接设置新训练样本的最终层权重作为权重印记过程。在 12 中,作者研究并表明,这些基于迁移学习的方法可以与元学习方法达到竞争性表现。
2.2 Semi-supervised few-shot learning
半监督小样本学习(Semi-Supervised Learning,SSL)是一种机器学习方法,它在训练过程中结合了少量的标记数据和大量的未标记数据 22 23。在深度学习时代,SSL 通常从以下角度利用未标记数据,例如,考虑一致性正则化 24,采用移动平均策略 25,应用对抗扰动正则化 26 等等。
近年来,利用未标记数据提高小样本学习准确性的问题受到了越来越多的关注 14 15 16 17 18 19,这催生了半监督小样本学习(SSFSL)方法的研究。然而,直接将SSL方法应用于小样本监督场景通常会导致较差的结果,原因在于标记数据极为稀少,例如 1-shot 分类。更具体地,为了应对具有挑战性的SSFSL,Ren 等人 27 扩展了 Prototypical Networks 6,在生成原型时使用未标记样本。TPN 16 被开发用来通过学习一个图来传播标签,将标记数据的标签传播到未标记数据,利用数据的流形结构。最近,提出了最先进的SSFSL方法,例如 14 15 18,通过伪标签对未标记数据进行预测,并进一步增强小样本分类中的标签受限支持集。与以前的工作不同,据我们所知,我们是第一个探索在SSFSL中利用互补标签(即负学习)来对未标记数据进行伪标签化的研究。
2.3 Negative learning
负学习(Negative Learning,NL)作为一种间接学习方法,用于训练卷积神经网络(CNN),在典型的监督学习(即正学习,Positive Learning,PL)中提出了一种新的学习范式 20。更具体地,PL表示“输入图像属于该标签”,而NL表示“输入图像不属于该互补标签”。与PL中收集普通标签相比,收集NL中的互补标签会更轻松 20。因此,NL不仅可以轻松与普通分类相结合 28 20,还可以辅助各种视觉应用,例如,利用NL处理噪声标签 29,使用不可靠的像素进行语义分割 30 等等。本文中,我们尝试利用NL通过从未标记数据中预测负伪标签来增强小样本标记集,从而获得更准确的伪标签,辅助在标签受限的场景下进行分类器建模。
3 Methodology
3.1 Problem Formulation
3.1.1 定义
在半监督小样本学习(Semi-Supervised Few-Shot Learning,SSFSL)中,我们有一个大规模的数据集 D base D_{\text{base}} Dbase,其中包含来自每个基类 C base C_{\text{base}} Cbase 的多个标记数据;以及一个小规模的数据集 D novel D_{\text{novel}} Dnovel,该数据集由作为支持集 S S S 的少量标记数据构成,类别集为 C novel C_{\text{novel}} Cnovel,并且包含一定数量的未标记数据 U U U,这些数据同样来自 C novel C_{\text{novel}} Cnovel。需要注意的是,为了进行泛化测试, D novel D_{\text{novel}} Dnovel 与 D base D_{\text{base}} Dbase 是不重叠的。SSFSL 的任务是基于支持集 S S S 和未标记数据 U U U 学习一个鲁棒的分类器 f ( ⋅ ; θ ) f(\cdot; \theta) f(⋅;θ),以便对来自 D novel D_{\text{novel}} Dnovel 的新查询 Q Q Q 进行预测,其中 D base D_{\text{base}} Dbase 被用作辅助数据。
3.1.2 设置
关于基本的半监督小样本分类设置,它通常面临
N
N
N -way-
K
K
K -shot 问题,其中每个类别只有
K
K
K 个标记数据来自
S
S
S,以及来自
U
U
U 的未标记数据。根据该设置,
Q
Q
Q 中的查询是相互独立的,并且在
U
U
U 中没有观察到。这被称为归纳推理(inductive inference)。
在SSFSL的另一个重要设置,即转导推理(transductive inference)中,查询集
Q
Q
Q 也在训练期间被观察到,并与
U
U
U 共同处理。
3.2 MUSIC:一种简单的逐步排除方法用于SSFSL
我们的 MUSIC 的基本思想是通过预测“负”(即“表示不属于”)伪标签来增强少样本标记集(支持集)
S
S
S,尤其适用于标签约束的场景,即未标记数据
U
U
U的伪标签。
给定一张图像
I
I
I,我们可以通过训练一个深度网络
F
(
⋅
;
Θ
)
F(\cdot; \Theta)
F(⋅;Θ),基于辅助数据
D
base
D_{\text{base}}
Dbase,来获得它的表示:
x
=
F
(
I
;
Θ
)
∈
R
d
,
(1)
x = F(I; \Theta) \in \mathbb{R}^d, \tag{1}
x=F(I;Θ)∈Rd,(1) 其中
Θ
\Theta
Θ是网络的参数。之后,
F
(
⋅
;
Θ
)
F(\cdot; \Theta)
F(⋅;Θ) 被视为其他图像的通用特征嵌入函数,并且
Θ
\Theta
Θ也被固定31。
然后,考虑到
c
c
c类分类任务,前述的分类器
f
(
⋅
;
θ
)
f(\cdot; \theta)
f(⋅;θ)将输入空间映射到
c
c
c维得分空间:
p
=
softmax
(
f
(
x
;
θ
)
)
∈
R
c
,
(2)
p = \text{softmax}(f(x; \theta)) \in \mathbb{R}^c, \tag{2}
p=softmax(f(x;θ))∈Rc,(2)
其中
p
p
p实际上是属于
c
c
c维单纯形
Δ
c
−
1
\Delta_{c-1}
Δc−1的预测概率得分,
softmax
(
⋅
)
\text{softmax}(\cdot)
softmax(⋅)是softmax归一化,
θ
\theta
θ是参数。
在SSFSL中,
θ
\theta
θ是随机初始化的,并且只通过
S
S
S中的
N
N
N个标记数据中的
K
K
K个标签进行微调,使用交叉熵损失函数:
L
(
f
,
y
)
=
−
∑
k
y
k
log
p
k
,
(3)
L(f, y) = - \sum_k y_k \log p_k, \tag{3}
L(f,y)=−k∑yklogpk,(3)
其中
y
∈
R
c
y \in \mathbb{R}^c
y∈Rc是一个one-hot向量,表示与
x
x
x相关的真实标签,
y
k
y_k
yk和
p
k
p_k
pk分别是
y
y
y和
p
p
p中第
k
k
k个元素。
为了增强 S S S中的有限标记数据,我们提出从间接学习的角度预测未标记图像(例如, I u I_u Iu)的伪标签,具体方法是排除负标签。具体来说,考虑一个常规的分类任务,真实标签 y k = 1 y_k = 1 yk=1表示其数据 x x x属于类别 k k k,这可以称为正向学习(Positive Learning)。与此相对,我们定义另一个one-hot向量 y ∈ R c y \in \mathbb{R}^c y∈Rc作为补充标签[10, 12],其中 y k = 1 y_k = 1 yk=1表示 x x x不属于类别 k k k,即负向学习(Negative Learning)。由于在少样本学习场景中标记数据非常有限,分类器 f ( ⋅ ; θ ) f(\cdot; \theta) f(⋅;θ)无法准确地给 I u I_u Iu分配正确的正标签。然而,相反地,通过赋予一个负伪标签来描述 I u I_u Iu不属于类别 k k k,即分配 y k u = 1 y_k^u = 1 yku=1,这将相对容易且准确。因此,我们通过获取基于最低概率得分的最有信心的负伪标签来实现“排除”这一思想。
该过程可形式化为:
y k u = { 1 , if k = arg min ( p u ) and p k u ≤ δ rejection , rejection , otherwise . (4) y_k^u = \begin{cases} 1, & \text{if } k = \arg\min(p_u) \text{ and } p_k^u \leq \delta_{\text{rejection}}, \\ \text{rejection}, & \text{otherwise}. \end{cases} \tag{4} yku={1,rejection,if k=argmin(pu) and pku≤δrejection,otherwise.(4)
其中 p u p_u pu表示 I u I_u Iu的预测概率, δ \delta δ是一个拒绝阈值,用于确保只有在具有足够强信心时才会分配伪标签。如果所有 p k u p_k^u pku都大于 δ \delta δ,则在此迭代中不会返回 I u I_u Iu的负伪标签。
因此,在获得样本和负伪标签对 ( I u , y u ) (I_u, y_u) (Iu,yu)后, f ( ⋅ ; θ ) f(\cdot; \theta) f(⋅;θ)可以通过以下损失函数进行更新:
L ( f , y u ) = − ∑ k y k u log ( 1 − p k u ) . L(f, y_u) = - \sum_k y_k^u \log(1 - p_k^u). L(f,yu)=−k∑ykulog(1−pku).
在下一次迭代中,我们从剩余的候选类别中排除第 k k k类,即上一轮迭代中的负伪标签。之后,更新后的分类器被用来给 I u I_u Iu分配概率得分 p u ∖ k ∈ R c − 1 p_u \setminus k \in \mathbb{R}^{c-1} pu∖k∈Rc−1,不再考虑类别 k k k。类似的伪标签预测过程以连续排除的方式进行,直到根据式(4)预测出所有的负伪标签,或者无法以足够强的信心预测负伪标签。
最后,在最后一次迭代中,对于那些在 U U U中负标签已经全部标记的样本,其正伪标签自然可以获得。我们可以根据最终的正标签,按照式(3)进一步更新分类器。然后,更新后的分类器 f ( ⋅ ; θ ) f(\cdot; \theta) f(⋅;θ)可以用于预测 Q Q Q作为评估。
此外,为了进一步提高概率置信度并促进伪标签预测,我们建议在
p
u
pu
pu上添加最小熵损失(MinEnt),通过优化以下目标:
L
(
f
,
p
u
)
=
−
∑
k
p
k
u
log
p
k
u
.
L(f, p_u) = - \sum_k p_k^u \log p_k^u.
L(f,pu)=−k∑pkulogpku.
这将加深
p
u
pu
pu的分布,从而区分正负标签的置信度。算法3.2提供了我们MUSIC的伪代码。

4 Experiments
4.1 Datasets and Empirical Settings
我们在四个广泛使用的少样本学习基准数据集上进行了实验,这些数据集用于通用物体识别和精细分类,包括 miniImageNet 10、tieredImageNet 27、CIFAR-FS 32 和 CUB 33。具体来说,miniImageNet 包含 100 个类别,每个类别有 600 个样本,分辨率为 84 × 84,这些样本是从 ILSVRC-2012 34 中选取的。tieredImageNet 是从 ILSVRC-2012 中选取的一个更大的子集,具有 608 个类别,采用人工层次结构,其中的样本也是 84 × 84 的图像分辨率。CIFAR-FS 是 CIFAR-100 35 的变体,分辨率较低,包含 100 个类别,每个类别有 600 个样本,尺寸为 32 × 32。关于 CUB,它是一个精细分类数据集,包含 200 种不同的鸟类,共有 11,788 张图像。
为了公平比较,我们遵循了 14 15 18 中的数据划分协议,以训练特征嵌入函数并进行 SSFSL 的评估实验。我们选择了常用的 ResNet12 2 作为骨干网络,网络配置遵循 14 15 18。对于预训练,我们只是遵循 36 的方式进行预训练,但不在预训练期间使用任何伪标签。对于优化,采用带动量的随机梯度下降(SGD),动量为 0.9,权重衰减为 5 × 10−4,作为优化器来从头开始训练特征提取器。初始学习率为 0.1,并在第 60、70 和 80 轮时分别衰减为 6 × 10−3、1.2 × 10−3 和 2.4 × 10−4,遵循 36。关于 MUSIC 中的超参数,公式 (4) 中的拒绝选项 δ 设置为 1c,公式 (6) 中的权衡参数设置为默认值 1,适用于所有实验和迭代,证明其实用性和不复杂性。在评估期间,预训练模型的最后一层被替换为一个 2-归一化层和一个 c 维的全连接层作为分类器。我们还使用 SGD 进行优化。我们的 MUSIC 和所有基准方法在 600 个回合上进行评估,每个类别有 15 个测试样本。所有实验在 MindSpore 上进行,使用 GeForce RTX 3060 GPU。
4.2 Main Results
我们在以下四种设置中报告了实证结果。所有结果均为平均准确率,并且在 600 次实验中进行的对应 95% 置信区间也已计算。
4.2.1 基本半监督少样本设置
我们在表 1 中将我们的 MUSIC 与文献中的最先进方法进行了比较。如图所示,我们的简单方法在不同少样本任务上,跨所有数据集,明显优于现有的通用少样本学习和半监督少样本学习方法。除此之外,我们还报告了仅使用由我们的 MUSIC 生成的伪标记负样本或正样本的结果,分别在表格中标记为 “Ours (only neg)” 或 “Ours (only pos)”。显而易见,即使仅使用负伪标签,MUSIC 仍然优于其他现有的 FSL 方法。而且,与仅使用正伪标签的结果相比,单独使用负标签的结果较差。这表明,准确的正标签仍然比负标签提供更多的信息 20。
表 1. 基本半监督少样本设置下的 5 类少样本分类比较:这些结果分别在 5 类 1-shot 和 5 类 5-shot 任务中使用 30/50 个未标记样本进行测试。浅蓝色块表示这些方法在归纳设置(inductive setup)下测试,浅黄色块表示在基本半监督设置下测试。最高的准确率用红色标记,第二高的准确率用蓝色标记。
| METHOD | BACKBONE | miniImageNet 1-shot 5-shot | tieredImageNet 1-shot 5-shot | CIFAR-FS 1-shot 5-shot | CUB 1-shot 5-shot |
|---|---|---|---|---|---|
| MatchingNet [33] | 4 CONV | 43.56 55.31 | - - | - - | - - |
| MAML [4] | 4 CONV | 48.70 63.11 | 51.67 70.30 | 58.90 71.50 | 54.73 75.75 |
| ProtoNet [29] | 4 CONV | 49.42 68.20 | 53.31 72.69 | 55.50 72.00 | 50.46 76.39 |
| LEO [28] | WRN-28-10 | 61.76 77.59 | 66.33 81.44 | - - | - - |
| CAN [8] | ResNet-12 | 63.85 79.44 | 69.89 84.23 | - - | - - |
| DeepEMD [45] | ResNet-12 | 65.91 82.41 | 71.16 86.06 | 74.58 86.92 | 75.65 88.69 |
| FEAT [43] | ResNet-12 | 66.78 82.05 | 70.80 84.79 | - - | 73.27 85.77 |
| RENet [11] | ResNet-12 | 67.60 82.58 | 71.61 85.28 | 74.51 86.60 | 82.85 91.32 |
| FRN [40] | ResNet-12 | 66.45 82.83 | 72.06 86.89 | - - | 83.55 92.92 |
| COSOC [21] | ResNet-12 | 68.12 82.71 | 73.57 87.57 | - - | 79.60 90.48 |
| SetFeat [1] | ResNet-12 | 68.32 82.71 | 73.62 87.59 | - - | 85.63 93.18 |
| MCL [20] | ResNet-12 | 69.31 85.11 | 73.62 87.56 | - - | 84.01 93.18 |
| STL DeepBDC [41] | ResNet-12 | 67.83 85.45 | 73.82 89.00 | - - | 84.01 94.02 |
| TPN [19] | 4 CONV | 52.78 66.42 | 55.74 71.01 | - - | - - |
| TransMatch [44] | WRN-28-10 | 60.02 79.30 | 72.19 82.12 | - - | - - |
| LST [17] | ResNet-12 | 70.01 78.70 | 77.70 85.20 | - - | - - |
| EPNet [23] | ResNet-12 | 70.50 80.20 | 75.90 82.11 | - - | - - |
| ICI [36] | ResNet-12 | 69.66 80.11 | 84.01 89.00 | 76.51 84.32 | 89.58 92.48 |
| iLPC [15] | ResNet-12 | 70.99 81.06 | 85.04 89.63 | 78.57 85.84 | 90.11 92.46 |
| PLCM [9] | ResNet-12 | 72.06 83.71 | 84.78 90.11 | 77.62 86.13 | - - |
| Ours | ResNet-12 | 74.96 85.99 | 85.40 90.79 | 78.96 87.25 | 90.76 93.27 |
| Ours (only neg) | ResNet-12 | 73.86 85.11 | 84.91 90.29 | 78.26 86.53 | 89.91 92.46 |
| Ours (only pos) | ResNet-12 | 74.44 85.86 | 85.33 90.62 | 78.81 87.11 | 90.27 93.11 |
4.2.2 传递半监督少样本设置
在传递设置中,可以在推理阶段访问查询数据。我们也在这样的设置下进行了实验,并在表 2 中报告了结果。如所见,我们的方法仍然可以在所有四个数据集上获得最优的准确率,这证明了我们的 MUSIC 的有效性。关于仅使用负伪标签和正伪标签的比较,其观察结果与表 1 中相似。
表 2:在转导设置下的 5 类少样本分类比较。最高的准确率用红色标记,第二高的准确率用蓝色标记。
| METHOD | BACKBONE | miniImageNet 1-shot 5-shot | tieredImageNet 1-shot 5-shot | CIFAR-FS 1-shot 5-shot | CUB 1-shot 5-shot |
|---|---|---|---|---|---|
| TPN [19] | 4 CONV | 55.51 69.86 | 59.91 73.30 | - - | - - |
| EPNet [23] | ResNet-12 | 66.50 81.06 | 76.53 87.32 | - - | 88.06 92.53 |
| ICI [36] | ResNet-12 | 66.80 79.26 | 80.79 87.92 | 73.97 84.13 | 89.00 92.74 |
| iLPC [15] | ResNet-12 | 69.79 79.82 | 83.49 89.48 | 77.14 85.23 | - - |
| PLCM [9] | ResNet-12 | 70.92 82.74 | 82.61 89.47 | - - | - - |
| Ours | ResNet-12 | 72.01 83.49 | 83.57 89.81 | 77.56 85.49 | 89.40 92.91 |
| Ours (only neg) | ResNet-12 | 71.46 83.04 | 83.20 89.33 | 77.26 85.10 | 88.73 92.51 |
| Ours (only pos) | ResNet-12 | 71.83 83.31 | 83.44 89.57 | 77.42 85.33 | 89.31 92.78 |
4.2.3 干扰半监督少样本设置
在实际应用中,收集一个干净的未标记数据集而不混入其他类别的数据可能并不现实。为了进一步验证 MUSIC 的鲁棒性,我们进行了干扰设置实验,即未标记集包含了支持集之外的干扰类。在这种情况下,正伪标签更容易出错,而负伪标签的出错风险较低。表 3 展示了比较结果,表明我们的方法在所有干扰半监督少样本分类任务中表现为最优解。
表 3:在干扰性半监督设置下的 5 类少样本分类比较。

4.3 消融实验与讨论
我们通过在两个数据集(即 miniImageNet 和 CUB)上进行消融实验,分析并讨论了我们的 MUSIC 方法,回答以下问题:
4.3.1 在 SSFSL 下,负伪标签是否比正伪标签更容易预测?
如前所述,在这种极其受限标签的场景中,例如 1-shot 学习,可能很难学习一个准确的分类器来正确预测正伪标签。在本小节中,我们通过交替执行负伪标签和正伪标签的标注,进行消融实验以验证这一假设。在表 4 中,不同的设置表示 SSFSL 中负伪标签和正伪标签的不同标注顺序。例如,"neg → pos → · · · " 表示我们首先通过我们的 MUSIC 方法获得负伪标签(不使用最终的正伪标签)并更新模型,然后获得正伪标签并更新模型,依此类推。关于迭代次数,它与 K 类分类中的 K 值相关。具体来说,对于 5 类分类,我们的 MUSIC 在当前迭代中返回最有信心的负伪标签,并将其排除在下一次迭代之外。因此,在四次 “neg → pos” 后,所有负伪标签的标注工作完成,结果可以报告。类似地,"pos → neg → · · · " 意味着我们首先获得正伪标签,然后是负伪标签。正如表 4 中的结果所示,首先获得负伪标签显然比正伪标签的顺序更能获得更好的结果,这表明首先标注负伪标签可以为模型训练奠定更好的基础,进一步回答了本小节中的问题:“YES”。
表 4:针对未标记数据,不同正负伪标签排序下的 5 类少样本分类比较。

4.3.2 最小熵损失是否有效?
在我们的 MUSIC 方法中,为了进一步提高概率置信度,从而促进伪标签的生成,我们引入了最小熵损失(MinEnt)。我们在此测试其有效性,并将结果报告在表 5 中。结果显示,使用 MinEnt(即所提的 MUSIC 方法)训练,相较于不使用 MinEnt 的训练,能够带来 0.2 % ∼ 0.3 % 0.2\%∼0.3\% 0.2%∼0.3% 的提升。
表 5:无最小熵损失(MinEnt)和有最小熵损失(MinEnt,参见公式 (6))情况下的 5 类少样本分类比较。

4.3.3 拒绝选项 δ \delta δ 是否有效?
我们在此验证了 MUSIC 中拒绝选项 δ \delta δ 的有效性和必要性。在我们的 approach 中, δ \delta δ 作为一种保障机制,确保所获得的负伪标签具有尽可能高的置信度。我们在表 6 中展示了相关结果,可以观察到,带有 δ \delta δ 的 MUSIC 方法在少样本分类精度上明显优于不带 δ \delta δ 的 MUSIC 方法。此外,即使没有 δ \delta δ,我们的方法仍然能够表现良好,且结果与现有最先进方法的结果相当或甚至更优。
表 6:无拒绝选项
δ
\delta
δ 和有拒绝选项
δ
\delta
δ(参见公式 (4))情况下的 5 类少样本分类比较。

4.3.4 迭代方式在 MUSIC 中的效果是什么?
如前所述,我们的方法以连续排除的方式工作,直到所有负伪标签被预测出来,最终获得正伪标签。在伪标签标注过程中,值得研究的是随着迭代的推进,性能如何变化。我们在图 3 中报告了相应的结果。如图所示,在这两个数据集的每个任务上,我们的方法都表现出相对稳定的增长趋势,即每次迭代相较上一次提升 0.5 % ∼ 2 % 0.5\%∼2\% 0.5%∼2%。

图 3:我们在 5 类少样本分类中随迭代次数增加的结果。
4.3.5 MUSIC 中伪标签标注的表现如何?
在本小节中,我们明确地调查了我们的 approach 所预测的负伪标签和正伪标签的错误率。我们以 miniImageNet 和 CUB 上的 5-way-5-shot 分类任务为例,首先在表 7 中展示了负伪标签的伪标签错误率。由于任务是 5 类预测,MUSIC 方法中共有四次负伪标签标注迭代。在该表中,我们不仅报告了错误率,还详细报告了每次迭代中错误标注样本的数量以及标注的总样本数。需要注意的是,在负伪标签的第三和第四次迭代中,标注的总样本数少于未标注数据的数量(即 250 250 250),这是由于 MUSIC 中的拒绝选项所致。也就是说,这些样本无法以非常高的置信度进行伪标签标注。与此同时,我们还看到,随着伪标签的进行,错误率缓慢上升,但负标签的最终错误率仍然不高于 6.7 % 6.7\% 6.7%。这从直观上证明了我们方法的有效性。
表 7:5 类 5-shot 分类中每次迭代负标签的伪标签错误率。

另一方面,表 8 比较了正伪标签的错误率,并且还报告了标注样本在所有未标注样本中的比例。对于 ICI 18 和 iLPC 15,尽管它们设计了专门的策略来确保伪标签的正确性,如实例可信度推理 18 和标签清理 15,这些方法的伪标签错误率仍然较高(超过
25
%
25\%
25%)。与之相比,我们的方法显著降低了错误率,即约为
10
%
10\%
10%。同时,我们还注意到,我们的 MUSIC 只对约
80
%
80\%
80% 的未标注数据进行预测,这可以看作是相对保守的。然而,这也表明我们的 approach 仍然具有很大的性能提升空间。此外,表 8 还显示,即使我们的方法去除了拒绝选项策略,其错误率仍然低于最先进方法。
表 8:5 类 5-shot 分类中伪标签的错误率和正标签的比例。

此外,我们通过 t-SNE 37 可视化了高置信度的正伪标签(图 4)。与这些方法相比,我们可以明显看到,MUSIC 预测的高置信度正样本更加集中且更加明显。这也从定性角度解释了我们的 approach 在使用正伪标签时的满意表现,并且在仅使用正伪标签时(参见表 1 和表 2)的良好结果。
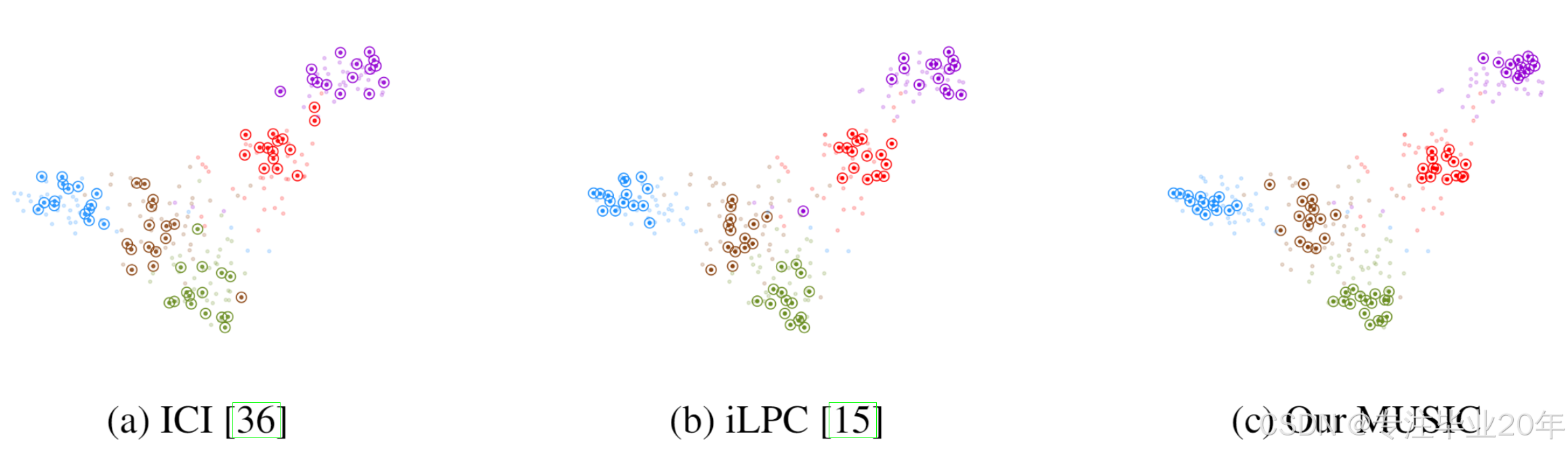
图 4:5 类 5-shot 50 未标记任务的 t-SNE [32] 可视化结果。不同颜色表示不同类别。对于 ICI 和 iLPC,圈出的数据点代表被选中的样本。对于我们提出的 MUSIC 方法,圈出的样本表示在最终迭代中具有高置信度正伪标签的样本。
4.3.6 MUSIC 的伪标签是否是平衡分布?
在本小节中,我们仍然有兴趣研究伪标签样本的分布情况,以进一步分析我们的方法为何能够取得较好的效果。如表 9 所示,我们展示了在 miniImageNet 上进行的 5-way-5-shot 分类任务中,所有 600 600 600 轮次的负伪标签和正伪标签样本的平均数量。可以明显看到,伪标签样本呈现出非常明显的平衡分布,这有助于在 SSFSL 中跨不同类别建模分类器。
表 9:在我们提出的 MUSIC 方法中,不属于(属于)不同类别的负(正)伪标记样本的平均数量。

5. Conclusion
在本文中,我们通过提出一种简单但有效的方法,称为 MUSIC,来处理半监督少样本分类问题。我们的 MUSIC 方法采用连续排除的方式,在极其标签受限的任务中尽可能地预测负伪标签,并在获得这些负伪标签后,通过基于负学习的方式更新模型,直到所有的负伪标签被返回。最后,结合附带的正伪标签,我们增强了用于在 SSFSL 中评估的小型标注数据支持集。在实验中,全面的实证研究验证了 MUSIC 的有效性,并揭示了其工作机制。未来,我们希望研究关于 MUSIC 的理论分析,特别是在其收敛性和估计误差界限方面,以及其在传统的半监督学习任务中的表现。
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521:436–444, 2015. ↩︎
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 770–778, 2016. ↩︎ ↩︎
Xiu-Shen Wei, Yi-Zhe Song, Oisin Mac Aodha, Jianxin Wu, Yuxin Peng, Jinhui Tang, Jian Yang, and Serge Belongie. Fine-grained image analysis with deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell., DOI: 10.1109/TPAMI.2021.3126648, 2021. ↩︎
Li Liu, Wanli Ouyang, Xiaogang Wang, Paul Fieguth, Jie Chen, Xinwang Liu, and Matti Pietikäinen. Deep learning for generic object detection: A survey. Int. J. Comput. Vision, 128:261–318, 2020. ↩︎
Yaqing Wang, Quanming Yao, James T. Kwok, and Lionel M. Ni. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surveys, 53(63):1–34, 2021. ↩︎
Jake Snell, Kevin Swersky, and Richard S. Zemel. Prototypical networks for few-shot learning. In Advances in Neural Inf. Process. Syst., pages 4077–4087, 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Matching networks for one shot learning. In Advances in Neural Inf. Process. Syst., pages 3637–3645, 2016. ↩︎ ↩︎ ↩︎
Chi Zhang, Yujun Cai, Guosheng Lin, and Chunhua Shen. DeepEMD: Few-shot image classification with differentiable earth mover’s distance and structured classifiers. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 12203–12213, 2020. ↩︎ ↩︎ ↩︎ ↩︎
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proc. Int. Conf. Mach. Learn., pages 1126–1135, 2017. ↩︎ ↩︎ ↩︎ ↩︎
Sachin Ravi and Hugo Larochelle. Optimization as a model for few-shot learning. In Proc. Int. Conf. Learn. Representations, 2017. ↩︎ ↩︎ ↩︎ ↩︎
Andrei A. Rusu, Dushyant Rao, Jakub Sygnowski, Oriol Vinyals, Razvan Pascanu, Simon Osindero, and Raia Hadsell. Meta-learning with latent embedding optimization. In Proc. Int. Conf. Learn. Representations, 2019. ↩︎ ↩︎
Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira, Yu-Chiang Wang, and Jia-Bin Huang. A closer look at few-shot classification. In Proc. Int. Conf. Learn. Representations, 2019. ↩︎ ↩︎
Hang Qi, Matthew Brown, and David G. Lowe. Low-shot learning with imprinted weights. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 5822–5830, 2018. ↩︎ ↩︎
Kai Huang, Jie Geng, Wen Jiang, Xinyang Deng, and Zhe Xu. Pseudo-loss confidence metric for semi-supervised few-shot learning. In Proc. IEEE Int. Conf. Comp. Vis., pages 8671–8680, 2021. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Michalis Lazarou, Tania Stathaki, and Yannis Avrithis. Iterative label cleaning for transductive and semi-supervised few-shot learning. In Proc. IEEE Int. Conf. Comp. Vis., pages 8751–8760, 2021. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sung Ju Hwang, and Yi Yang. Learning to propagate labels: Transductive propagation network for few-shot learning. In Proc. Int. Conf. Learn. Representations, 2019. ↩︎ ↩︎ ↩︎
Rodríguez Pau, Issam Laradji, Alexandre Drouin, and Alexandre Lacoste. Embedding propagation: Smoother manifold for few-shot classification. In Proc. Eur. Conf. Comp. Vis., pages 121–138, 2020. ↩︎ ↩︎
Yikai Wang, Chengming Xu, Chen Liu, Li Zhang, and Yanwei Fu. Instance credibility inference for few-shot learning. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 12836–12845, 2020. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Zhongjie Yu, Lin Chen, Zhongwei Cheng, and Jiebo Luo. TransMatch: A transfer-learning scheme for semi-supervised few-shot learning. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 12856–12864, 2020. ↩︎ ↩︎
Takashi Ishida, Gang Niu, Weihua Hu, and Masashi Sugiyama. Learning from complementary labels. In Advances in Neural Inf. Process. Syst., pages 5644–5654, 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Han-Jia Ye, Hexiang Hu, and De-Chuan Zhan. Learning adaptive classifiers synthesis for generalized few-shot learning. Int. J. Comput. Vision, 129(6):1930–1953, 2021. ↩︎
Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in Neural Inf. Process. Syst., pages 529–536, 2005. ↩︎
Zhi-Hua Zhou and Ming Li. Semi-supervised learning by disagreement. Knowl. and Inf. Syst., 24(3):415–439, 2010. ↩︎
Samuli Laine and Timo Aila. Temporal ensembling for semisupervised learning. In Proc. Int. Conf. Learn. Representations, 2017. ↩︎
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Inf. Process. Syst., pages 1195–1204, 2017. ↩︎
Takeru Miyato, Andrew M. Dai, and Ian Goodfellow. Adversarial training methods for semisupervised text classification. In Proc. Int. Conf. Learn. Representations, 2017. ↩︎
Mengye Ren, Eleni Triantafillou, Sachin Ravi, Jake Snell, Kevin Swersky, Joshua B. Tenenbaum, Hugo Larochelle, and Richard S. Zemel. Meta-learning for semi-supervised few-shot classification. In Proc. Int. Conf. Learn. Representations, 2018. ↩︎ ↩︎
Yi Gao and Min-Ling Zhang. Discriminative complementary-label learning with weighted loss. In Proc. Int. Conf. Mach. Learn., pages 3587–3597, 2021. ↩︎
Youngdong Kim, Junho Yim, Juseung Yun, and Junmo Kim. NLNL: Negative learning for noisy labels. In Proc. IEEE Int. Conf. Comp. Vis., pages 101–110, 2019. ↩︎
Yuchao Wang, Haochen Wang, Yujun Shen, Jingjing Fei, Wei Li, Guoqiang Jin, Liwei Wu, Rui Zhao, and Xinyi Le. Semi-supervised semantic segmentation using unreliable pseudo-labels. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2022. ↩︎
Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B. Tenenbaum, and Phillip Isola. Rethinking few-shot image classification: A good embedding is all you need? In Proc. Eur. Conf. Comp. Vis., pages 266–282, 2020. ↩︎
Luca Bertinetto, Joao F. Henriques, Philip Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. In Proc. Int. Conf. Learn. Representations, 2019. ↩︎
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The Caltech-UCSD birds-200-2011 dataset. Technical report, California Institute of Technology, 2011. ↩︎
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet large scale visual recognition challenge. Int. J. Comput. Vision, 115(3):211–252, 2015. ↩︎
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009. ↩︎
Yikai Wang, Li Zhang, Yuan Yao, and Yanwei Fu. How to trust unlabeled data instance credibility inference for few-shot learning. IEEE Trans. Pattern Anal. Mach. Intell., DOI: 10.1109/TPAMI.2021.3086140, 2021. ↩︎ ↩︎
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE. J. Mach. Learn. Res., 9:2579–2605, 2008. ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









