






1.变量和常量
- 常量
- 在程序运行过程中不可以被改变的量叫做常量
- 整形常量可以理解为是直接使用的整形常数,如:123,456,-456,等
- 常量的类型
- 100:整型 int
- 100L:长整型 long
- 100LL:长长整型 long long
- 100ULL:无符号长长整型 unsigned long long
- 3.14:双精度浮点型 double
- 3.14L:长双精度浮点型 long double
- 'a':字符型 char
- "abcd":字符指针 char *
int a = 100; // a是变量,而100是常量
float f = 3.14; // f是变量,而3.14是常量
char s[] = "abcd"; // s是变量,"abcd"是常量- 变量
- 在程序运行过程中其值可以改变的量。
- 本质:变量代表内存中具有特定属性的存储单元,变量名实际是符号化的内存地址。
- 在C语言中,要求对所用到的变量使用前必须先强制定义,即:先定义,后使用。
2.数据的进制表示
- 字节(Byte):
- 计算机中数据储存的单位,也是数据读取的最小单位(按字寻址的系统除外)
- 位(bit):也叫作“比特”,计算机中数据储存的最小单位,因为在计算机中是以二进制的形式数据储存,所以每个位以“0”或“1”表示
- 字节与位的关系:1Byte=8bit
- 1KB=1024B(2^10)、1MB=1024KB、1GB=1024MB、1TB=1024GB
- 十进制:
- 由十个数码来表示的数。分别是:0、1、2、3、4、5、6、7、8、9
- 遵循的原则是:逢十进一
- 二进制:
- 由两个数码来表示的数。分别是:0、1
- 遵循的原则是:逢二进一
- 八进制:
- 由八个数码来表示的数。分别是:0、1、2、3、4、5、6、7
- 遵循的原则是:逢八进一
- 十六进制:
- 由十六个数码来表示的数。分别是:0、1、2、3、4、5、6、7、8、9、A、B、C、 D、E、F
- 遵循的原则是:逢十六进一
- 表示方法:一个数占四个比特位
- 进制转换方法:
十进制转二进制
- 短除法:
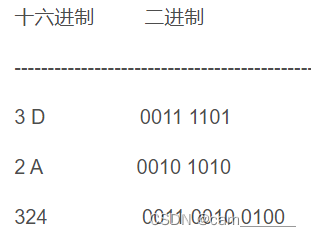
十六进制转二进制:十六进制中的任意字节码都能用四个二进制字节码表示
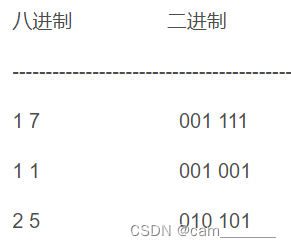
八进制转二进制:八进制中的任意字节码都能用三位个二进制字节码表示
- 二进制转十进制:2的次方形式
011100 => 0*2^5+1*2^4+1*2^3+1*2^2+0*2^1+0*2^0 = 16+8+4 = 28
- 二进制转十六进制:
00101100 => 2C
11 0010 1010 => 0011 0010 1010 => 32A
- 二进制转八进制:
001 101 011 => 153
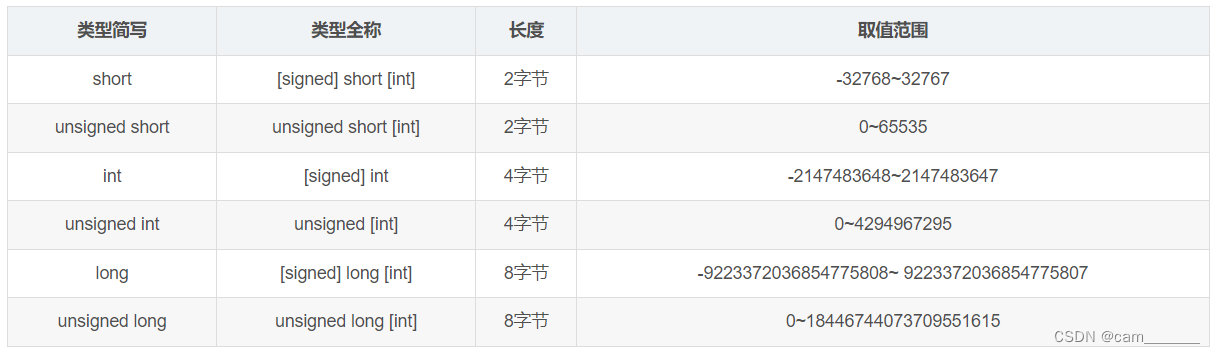
3.基本数据类型
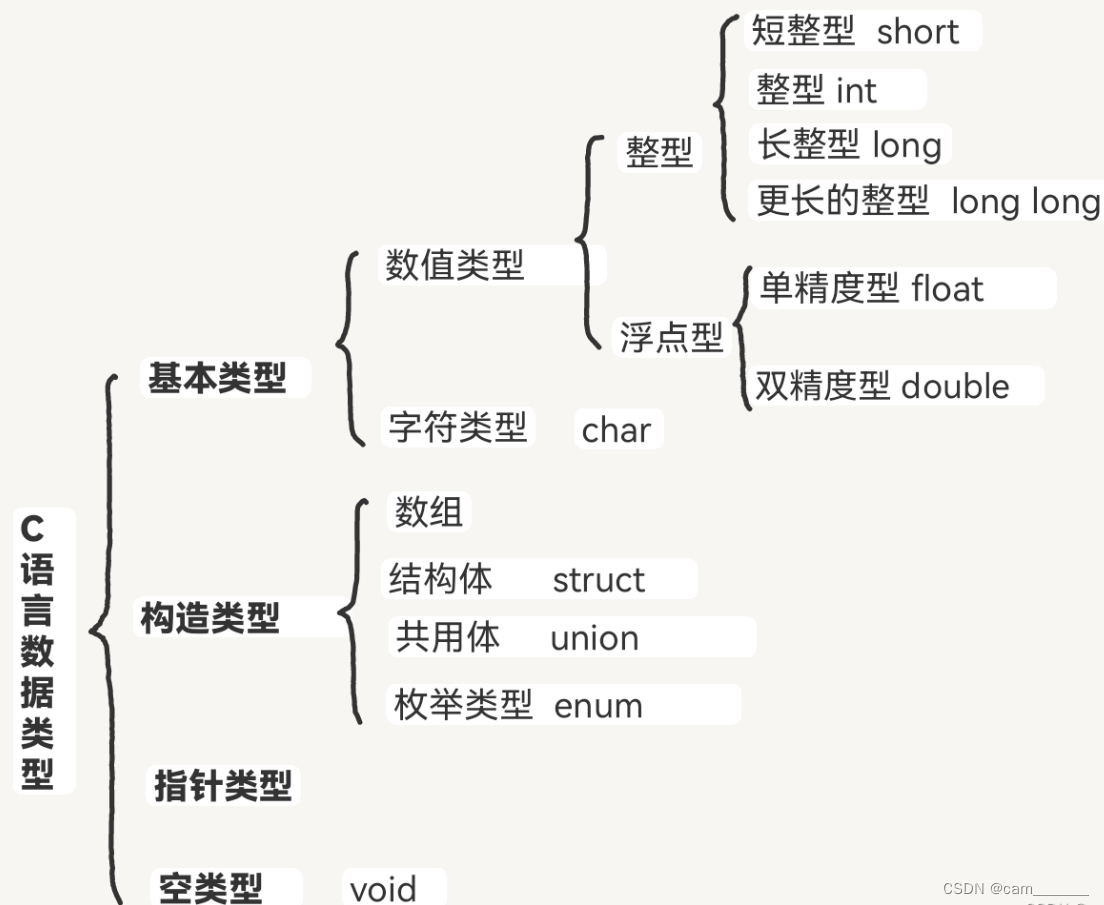
3.1 整型
- 在C语言中,整型数据一般用short、int、long三种数据类型来声明
int a = 123; // 定义了一个专门用来存储整数的变量a- int 的本意是 integer,即整数的意思
- int a 代表在内存中开辟一块小区域,称为 a,用来存放整数,a 一般被称为变量
- 变量 a 所占内存大小,在不同的系统中是不一样的,64位系统典型的大小是4个字节
- 整型修饰符
- short:用来缩短整型变量的尺寸,减少取值范围并节省内存,称为短整型
- long:用来增长整型变量的尺寸,增大取值范围并占用更多内存,称为长整型
- long long:用来增长整型变量的尺寸,增大取值范围并占用更多内存,称为长长整型
- unsigned:用来去除整型变量的符号位,使得整型变量只能表达非负整数
- 使用整型修饰符后,关键字 int 可以被省略
- 有符号数与无符号数
- 每一种基本数据类型都有两种形式:有符号数(signed)和无符号数(unsigned)
- 比如一个1字节数据,如果是无符号数,最小是0000 0000,为0,最大为1111 1111,即2^8-1,为255
- 如果是有符号数,最高位为符号位,0表示正,1表示负,0 000 0000~0 111 1111,范围为0~127;1 000 0000~1111 1111,范围则为-1~-128;所以unsigned char范围是0~255,signed char的范围是-128~127
- 如果不写signed或者unsigned,则代表默认有符号signed
3.1.1 码制
- 正数:原反补一致,均是原码本身,例如10
- 原码:0 000 1010
- 反码:0 000 1010
- 补码:0 000 1010
- 负数:比如-10
- 原码:1 000 1010
- 反码:1 111 0101 (原码除符号位不变,其余位取反)
- 补码:1 111 0110 (补码 = 反码 + 1),这也是计算机中对于数值-10最终的存放形式
- 公式:
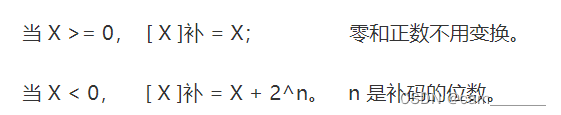
- 5 - 19 的计算过程:
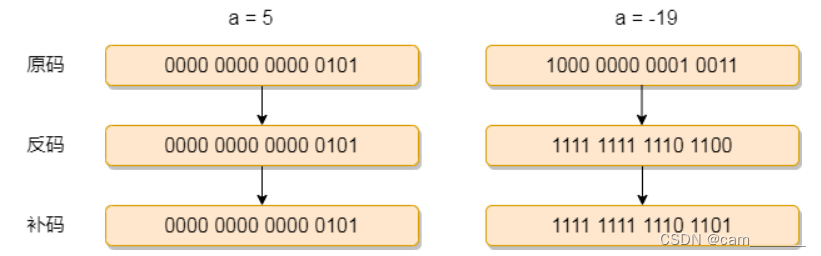
0_000 0000 0000 0101 + 1_111 1111 1110 1101 = 1_111 1111 1111 0010,1_111 1111 1111 0010 逆向转换原码是:1000 0000 0000 1110 = -14
- 数值溢出:
- 超过数据所能表达的范围,称为溢出,就像钟表,最大值和最小值是相邻的

#include <stdio.h>
int main()
{
char ch;
// 符号位溢出会导致数的正负发生改变
ch = 0x7f + 2; // 127+2
printf("%d\n", ch);
// 0111 1111
//+2后 1000 0001,这是负数补码,其原码为 1111 1111,结果为-127
// 最高位的溢出会导致最高位丢失
unsigned char ch2;
ch2 = 0xff + 1; // 255+1
printf("%u\n", ch2);
// 1111 1111
//+1后 10000 0000, char只有8位最高位的溢出,结果为 0000 0000,十进制为0
ch2 = 0xff + 2; // 255+2
printf("%u\n", ch2);
// 1111 1111
//+1后 10000 0001, char只有8位最高位的溢出,结果为 0000 0001,十进制为1
return 0;
}- 表达范围
- 在64位机中,int型变量占4字节,就是32位,
- 当表示正数时,最高位为符号位(符号位为0),最大的正数是 0111 1111 1111 1111 1111 1111 1111 1111 即2147483647
- 当表示负数时,最高位为符号位(符号位为1),最小的负数是 1000 0000 0000 0000 0000 0000 0000 0000 而在计算机中是以补码的形式存储的,即-2147483648
- 在64位机中,int型变量占4字节,就是32位,
- 计算机为什么使用补码?
- 采用补码可以简化计算机硬件电路设计的复杂度
- 解决了数字 0 在计算机中非唯一编码的问题
3.2 浮点型
- 用来表达实数的数据类型
- 单精度浮点型(float),典型尺寸是4字节
- 双精度浮点型(double),典型尺寸是8字节
- 长双精度浮点型(long double),典型尺寸是16字节
float f1; // 单精度
double f2; // 双精度
long double f3; // 长双精度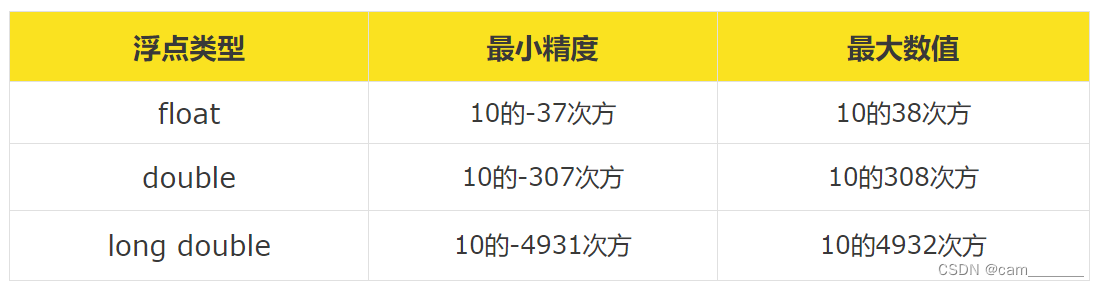
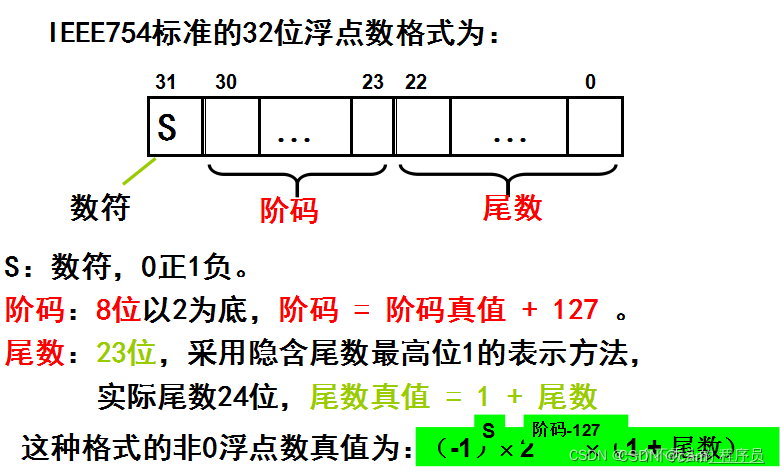
- 浮点型精度
float a = 3.1415926;
double b = 3.1415926;
printf("a:%f\nb:%f\n", a, b);- C语言中,输出float类型以及double类型时,默认输出6位小数(不足六位以 0 补齐,超过六位按四舍五入截断)
- 单精度输出:%.2f ,中间数字是保留几位小数的意思,最好不要超过6
- 双精度输出:%.8lf,中间数字是保留几位小数的意思,最好不要超过15
3.3 字符型
- 字符类型可以表示单个字符,字符类型是 char,char 是 1 个字节(可以存字母或者数字),多个字符称为字符串
- 计算机中存储的都是1和0,因此各种字符都必须被映射为某个数字才能存储到计算机中,这种映射关系形成的表称为 ASCII 码表。
| 数 值 | 字符 | 数 值 | 字符 | 数 值 | 字符 | |||
| 十进制 | 十六进制 | 十进制 | 十六进制 | 十进制 | 十六进制 | |||
| 00 | 0x00 | ‘\0’ | 20 | 0x14 | DC4 | 40 | 0x28 | ( |
| 01 | 0x01 | SOH | 21 | 0x15 | NAK | 41 | 0x29 | ) |
| 02 | 0x02 | STX | 22 | 0x16 | SYN | 42 | 0x2A | * |
| 03 | 0x03 | ETX | 23 | 0x17 | ETB | 43 | 0x2B | + |
| 04 | 0x04 | EOT | 24 | 0x18 | CAN | 44 | 0x2C | , |
| 05 | 0x05 | ENQ | 25 | 0x19 | EM | 45 | 0x2D | - |
| 06 | 0x06 | ACK | 26 | 0x1A | SUB | 46 | 0x2E | . |
| 07 | 0x07 | '\a' | 27 | 0x1B | ESC | 47 | 0x2F | / |
| 08 | 0x08 | '\b' | 28 | 0x1C | FS | 48 | 0x30 | 0 |
| 09 | 0x09 | '\t' | 29 | 0x1D | GS | 49 | 0x31 | 1 |
| 10 | 0x0A | ‘\n’ | 30 | 0x1E | RS | 50 | 0x32 | 2 |
| 11 | 0x0B | ‘\v’ | 31 | 0x1F | US | 51 | 0x33 | 3 |
| 12 | 0x0C | '\f' | 32 | 0x20 | SPACE | 52 | 0x34 | 4 |
| 13 | 0x0D | '\r' | 33 | 0x21 | ! | 53 | 0x35 | 5 |
| 14 | 0x0E | SO | 34 | 0x22 | EOT | 54 | 0x36 | 6 |
| 15 | 0x0F | SI | 35 | 0x23 | # | 55 | 0x37 | 7 |
| 16 | 0x10 | DLE | 36 | 0x24 | $ | 56 | 0x38 | 8 |
| 17 | 0x11 | DC1 | 37 | 0x25 | % | 57 | 0x39 | 9 |
| 18 | 0x12 | DC2 | 38 | 0x26 | & | 58 | 0x3A | : |
| 19 | 0x13 | DC3 | 39 | 0x27 | ' | 59 | 0x3B | ; |
ASCII码表 I
| 数 值 | 字符 | 数 值 | 字符 | 数 值 | 字符 | |||
| 十进制 | 十六进制 | 十进制 | 十六进制 | 十进制 | 十六进制 | |||
| 60 | 0x3C | 83 | 0x53 | S | 106 | 0x6A | j | |
| 61 | 0x3D | = | 84 | 0x54 | T | 107 | 0x6B | k |
| 62 | 0x3E | > | 85 | 0x55 | U | 108 | 0x6C | l |
| 63 | 0x3F | ? | 86 | 0x56 | V | 109 | 0x6D | m |
| 64 | 0x40 | @ | 87 | 0x57 | W | 110 | 0x6E | n |
| 65 | 0x41 | A | 88 | 0x58 | X | 111 | 0x6F | o |
| 66 | 0x42 | B | 89 | 0x59 | Y | 112 | 0x70 | p |
| 67 | 0x43 | C | 90 | 0x5A | Z | 113 | 0x71 | q |
| 68 | 0x44 | D | 91 | 0x5B | [ | 114 | 0x72 | r |
| 69 | 0x45 | E | 92 | 0x5C | \ | 115 | 0x73 | s |
| 70 | 0x46 | F | 93 | 0x5D | ] | 116 | 0x74 | t |
| 71 | 0x47 | G | 94 | 0x5E | ^ | 117 | 0x75 | u |
| 72 | 0x48 | H | 95 | 0x5F | _ | 118 | 0x76 | v |
| 73 | 0x49 | I | 96 | 0x60 | ` | 119 | 0x77 | w |
| 74 | 0x4A | J | 97 | 0x61 | a | 120 | 0x79 | x |
| 75 | 0x4B | K | 98 | 0x62 | b | 121 | 0x70 | y |
| 76 | 0x4C | L | 99 | 0x63 | c | 122 | 0x7A | z |
| 77 | 0x4D | M | 100 | 0x64 | d | 123 | 0x7B | { |
| 78 | 0x4E | N | 101 | 0x65 | e | 124 | 0x7C | | |
| 79 | 0x4F | O | 102 | 0x66 | f | 125 | 0x7D | } |
| 80 | 0x50 | P | 103 | 0x67 | g | 126 | 0x7E | ~ |
| 81 | 0x51 | Q | 104 | 0x68 | h | 127 | 0x7F | DEL |
| 82 | 0x52 | R | 105 | 0x69 | i | |||
ASCII码表 II
- 字符本质上就是一个单字节的整型,支持整型所有的运算。比如:
char c1 = 20;
char c2 = c1 + 'a'; // 等价于 char c2 = 20 + 97;
printf("%c\n", c2); // 以字符形式输出117,即 'u'
printf("%d\n", c2); // 以整型形式输出117- 转义字符
- 一个字符除了可以用它的实体(也就是真正的字符)表示,还可以用编码值表示。这种使用编码值来间接地表示字符的方式称为转义字符(Escape Character)
- 转义字符以\或者\x开头,以\开头表示后跟八进制形式的编码值,以\x开头表示后跟十六进制形式的编码值。对于转义字符来说,只能使用八进制或者十六进制
char b = '\141'; // 字符a
char d = '\x61'; // 字符a
printf("%c %c\n", b, d);- 对于 ASCII 编码,0~31(十进制)范围内的字符为控制字符,它们都是看不见的,不能在显示器上显示,甚至无法从键盘输入,只能用转义字符的形式来表示。不过,直接使用 ASCII 码记忆不方便,也不容易理解,所以,针对常用的控制字符,C语言又定义了简写方式
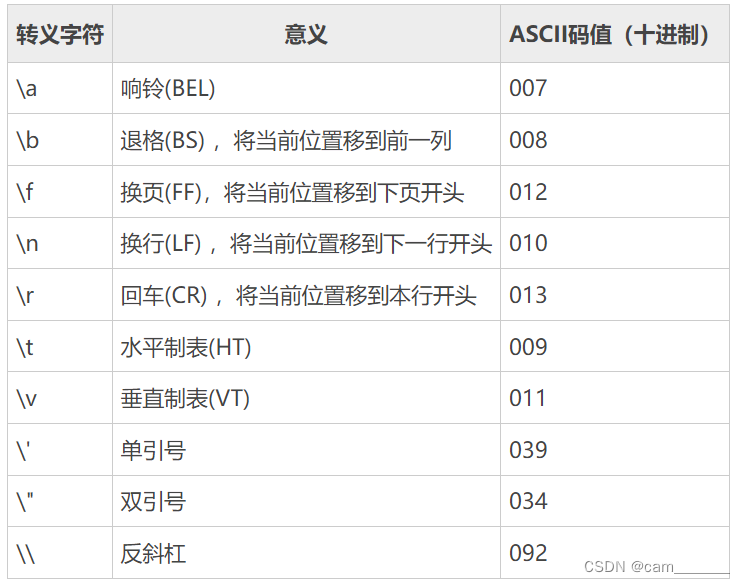
\n用来换行,让文本从下一行的开头输出,前面的章节中已经多次使用;
\t用来占位,一般相当于四个空格,或者 tab 键的功能。
- 单引号、双引号、反斜杠是特殊的字符,不能直接表示:
- 单引号是字符类型的开头和结尾,要使用\'表示,也即'\'';
- 双引号是字符串的开头和结尾,要使用\"表示,也即"abc\"123";
- 反斜杠是转义字符的开头,要使用\\表示,也即'\\',或者"abc\\123"。
3.4 布尔型
- 布尔型数据只有真、假两种取值,非零为真,零为假。
bool a = 1; // 逻辑真,此处1可以取其他任何非零数值
bool b = 0; // 逻辑假 - 逻辑真除了 1 之外,其他任何非零数值都表示逻辑真,等价于 1。
- 使用布尔型 bool 定义变量时需要包含系统头文件 stdbool.h。
- 布尔型数据常用在逻辑判断、循环控制等场合。
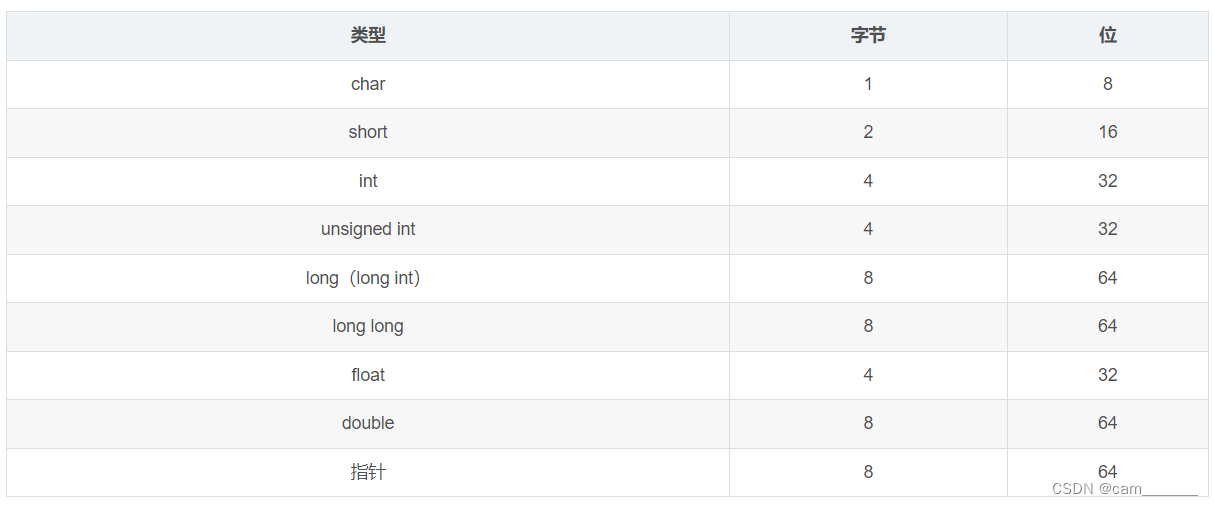
4.数据类型的尺寸
- 概念:整型数据尺寸是指某种整型数据所占用内存空间的大小
- C语言标准并未规定整型数据的具体大小,只规定了相互之间的 “ 相对大小 ” ,比如:
- short 不可比 int 长
- long 不可比 int 短
- long 型数据长度等于系统字长
- 系统字长:CPU 一次处理的数据长度,称为字长。比如32位系统、64位系统。
- 典型尺寸:
- char 占用1个字节
- short 占用2个字节
- int 在16位系统中占用2个字节,在32位和64位系统中一般都占用4个字节
- long 的尺寸等于系统字长
- long long 在32位系统中一般占用4个字节,在64位系统中一般占用8个字节
| 数据类型 | 字节大小 | 数值范围 |
| short int(短整型) | 2字节 | -32768 ~ +32767 |
| unsigned short int (无符号短整型) | 2字节 | 0 ~ +65535 |
| int(整形) | 4字节 | -2147483648 ~ +2147483647 |
| unsigned int (无符号整型) | 4字节 | 0 ~ 4294967295 |
| long int(长整型) | 8字节 | -9223372036854775808 ~ +9223372036854775807 |
| unsigned long int (无符号长整形) | 8字节 | 0 ~ 18,446,744,073,709,551,615 |
| long long int (超长整形) | 8字节 | -9223372036854775808 ~ +9223372036854775807 |
| unsigned long long int (无符号超长整形) | 8字节 | 0 ~ 18446744073709551615 |
注意:超长整形和无符号超长整形是在C++11中引入的
- 不同平台整型字节长度区别
| 平台/类型 | char | short | int | long | long long |
| 16位 | 1 | 2 | 2 | 4 | 8 |
| 32位 | 1 | 2 | 4 | 4 | 8 |
| 64位 | 1 | 2 | 4 | 8 | 8 |
5.类型转换
- 不一致但相互兼容的数据类型,在同一表达式中将会发生类型转换
- 转换模式:
- 隐式转换:系统按照隐式规则自动进行的转换
- 强制转换:用户显式自定义进行的转换
- 隐式规则:从小类型向大类型转换,目的是保证不丢失表达式中数据的精度
- 转换按数据长度增加的方向进行,以保证数值不失真,或者精度不降低。例如,int 和 long 参与运算时,先把 int 类型的数据转成 long 类型后再进行运算
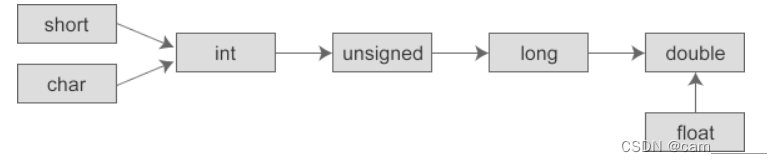
char a = 'a';
int b = 12;
float c = 3.14;
float x = a + b - c; // 在该表达式中将发生隐式转换,所有操作数被提升为float- 字符必须先转换为整数(C语言规定字符类型数据和整型数据之间可以通用) 。
- short型转换为int型(同属于整型)
- float型数据在运算时一律转换为双精度(double)型,以提高运算精度(同属于实型)
- 若两种类型的字节数相同,且一种有符号,一种无符号,则转换成无符号类型
- 若两种类型的字节数不同,转换成字节数高的类型
强制转换:用户强行将某类型的数据转换为另一种类型,此过程可能丢失精度
int sum = 103; // 总数
int count = 7; // 数目
double average; // 平均数
average = (double)sum / count;
printf("Average is %lf!\n", average);sum 和 count 都是 int 类型,如果不进行干预,那么sum / count的运算结果也是 int 类型,小数部分将被丢弃;虽然是 average 是 double 类型,可以接收小数部分,但是心有余力不足,小数部分提前就被“阉割”了,它只能接收到整数部分,这就导致除法运算的结果严重失真。既然 average 是 double 类型,为何不充分利用,尽量提高运算结果的精度呢?为了达到这个目标,我们只要将 sum 或者 count 其中之一转换为 double 类型即可。上面的代码中,我们将 sum 强制转换为 double 类型,这样sum / count的结果也将变成 double 类型,就可以保留小数部分了,average 接收到的值也会更加精确。
- 不管是隐式转换,还是强制转换,变换的都是操作数在运算过程中的类型,是临时的,操作数本身的类型不会改变,也无法改变。
















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











