









Benchmarks of the Lockless Memory Allocator
To show how fast the Lockless memory allocator is compared to others, we use the t-test1 benchmark. This benchmark is given a total amount of memory to use, and a maximum size of allocation to make. The benchmark chooses random sizes of memory below this maximum to call malloc(), calloc(), free(), realloc() and memalign(). The memory space is split into bins, and a specified number of parallel threads are used to access each bin. When a thread is done with a bin, it releases it, and acquires another. This causes the benchmark to test memory allocated on one thread, and freed in another.
Linux
We test how the memory allocation libraries vary with average allocation size, and total number of threads. We use an Opteron 280 system running Linux kernel version 2.6.38, with a total of 4 processor cores and 11GiB of ram to run this test. The test is run with 1,2,3,4,5,8,12,16, and 20 threads. Note that above 4 threads, the performance will be limited by the lack of processors. We vary the maximum allocation in the benchmark by powers of 2 from 64bytes up to 1MiB.
The resulting data is plotted below by number of threads, and maximum allocation size running from smallest to largest for each thread. We compare the Lockless memory allocator to the eglibc 2.11 allocator (a variant of ptmalloc), nedmalloc 1.06, hoard 3.8, jemalloc 2.2.1, and tcmalloc 1.7 The total time taken for each benchmark run is shown.

The resulting shapes are a series of distorted parabolas, one for each thread total. All allocators take more time in the small-size case. This is due to the design of the benchmark, where the total number of allocations performed serially is inversely proportional to their maximum size and total number of threads to keep the total amount of memory allocated bounded. When the size is small, the number of bins is large, and doesn't fit inside the processor's L2 cache.
When the allocation sizes become large, again the results tend to slow down. This is due to the conflicting desire to lower total memory usage and fragmentation. Allocators, in general, need to return memory to the operating system and this can result in contention within the kernel. In addition, the data structures that handle small allocations may not be able to handle (or be well optimized to handle) larger allocations. Thus memory allocators tend to switch between differing algorithms based on allocation size. This can appear as changes in the performance graph slope.
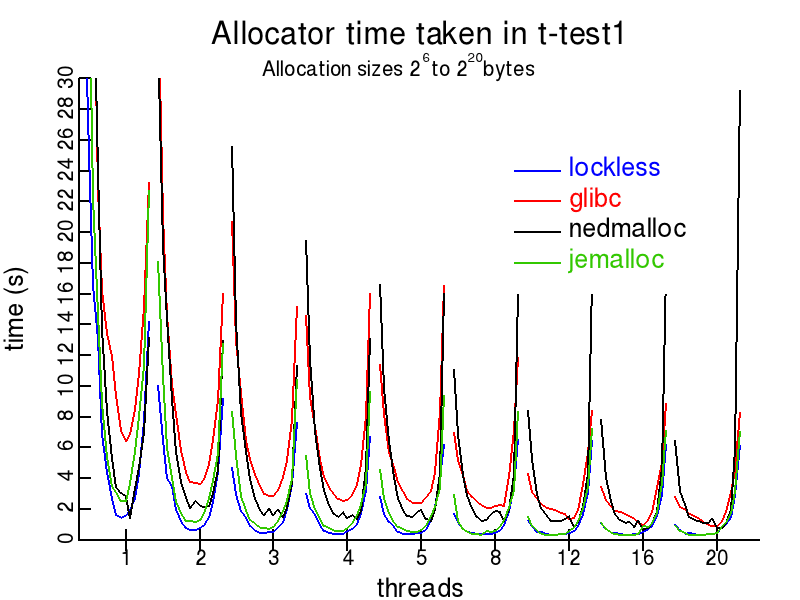
As can be seen, some of the allocators have extreme slowdowns in some cases. The hoard allocator becomes very slow if the average allocation size exceeds 64KiB. This appears to be due to thread contention in accessing a process-global pool. Conversely, the nedmalloc is slow for small allocations. This may be due to it not using a slab-based algorithm for small sizes.
Note that some allocators have increased in speed dramatically in the past few months (some by a factor of two or more). This means that most old benchmark results should probably be ignored, particularly ones published more than a year ago. It would be nice to think that this webpage, with its clear performance comparisons has been the catalyst for this recent change.
Glibc allocator
The standard allocator in Linux systems is that in the glibc library. This allocator is based on the ptmalloc2 library, with tweaks added over time. The allocator uses mutually exclusive "arenas". A thread will try to lock an arena to do the work it needs. If another thread is using that arena, then the first thread either waits, or creates a new arena. This contention between threads reduces performance and increases fragmentation in multithreaded applications. In addition, if one thread allocates memory, and a second frees it in a producer-consumer pattern, then large amounts of memory may be wasted. As can be seen below, the Lockless memory allocator performs much faster, with the performance gap dropping once the number of threads exceeds the number of cpus. When four threads are used (equal to the number of processor cores), the Lockless allocator is up to seven times faster.

Tcmalloc allocator
The tcmalloc allocator is designed with threading in mind, and as a result gives consistently good performance. Its one weakness is that it doesn't return memory to the operating system. For long-running server processes, this may be a problem. As can be seen below, this allocator is comparable to the Lockless memory allocator in the single threaded case. As more threads are used, the advantage of using lock-free algorithms shows, and tcmalloc drops behind. For allocation sizes above 64KiB, tcmalloc becomes has a noticable hump in the graph. This appears to be due to extra locking on chunks of this size or larger. For the very common small allocation sizes, the Lockless memory allocator is everywhere faster than this allocator, averaging about twice as fast for four threads on this four-cpu machine.

Hoard allocator
The hoard allocator used to be one of the best. However, time has not been kind to it, and other allocators now greatly outperform it. For small allocaitons, it still performs similarly to tcmalloc. However, beyond about 64KiB, it drops drastically in performance. It uses a central "hoard" to redistribute memory between threads. This presents a bottle-neck as only one thread at a time can be using it. As the number of threads increases, the problem gets worse and worse. The effects of excess contention can be seen in the "noise" in the performance graph. Since scheduling between threads is basically random, this randomness appears as rapid fluctuations in performance. Again, it can be seen that the Lockless memory allocator is everywhere faster than this allocator, sometimes by more than an order of magnitude, or even more.

Nedmalloc allocator
By request, we have benchmarked the nedmalloc allocator. This allocator is quite efficient, on average performing between the the glibc allocator and tcmalloc. It is extremely good for allocations of a few tens of KiB. However, for small allocations, which tend to be the most common in applications, it doesn't perform nearly as well as the competition. It also suffers slowdowns for large allocations once the total number of threads exceeds the cpu count. For small allocations, the Lockless Memory allocator is several times faster. For medium to large allocations, the Lockless Memory allocator ranges from about the same speed to two to three times faster.

Jemalloc allocator
This is a very good allocator when there is a large amount of contention, performing similarly to the Lockless memory allocator as the number of threads grows larger than the number of processors. However, when the number of allocating threads is smaller than the total number of cpus, it isn't quite as fast. The disadvantage of the jemalloc allocator is its memory usage. It uses power-of-two sized bins, which leads to a greatly increased memory footprint compared to other allocators. This can affect real-world performance due to excess cache and TLB misses.

Microsoft Windows
We test how the Lockless memory allocator compares to the in-build memory allocator in Microsoft Windows. The problem here is that Microsoft is continually changing how it implements its allocator. To make things simple, we choose the Windows Vista allocator as a baseline. That allocator is much better than the Windows XP one and optimized for multithreaded applications, thus making a fairer comparison.
We test how the total time taken varies with average allocation size, and total number of threads. We use an AMD Phenom system with a total of 4 processor cores to run this test. (Note that this is a different machine to the Linux tests above, so results between Linux and Windows should not be directly compared.) The test is run with 1,2,3,4,5,8,12,16, and 20 threads. Note that above 4 threads, the performance will be limited by the lack of processors. We vary the maximum allocation in the benchmark by powers of 2 from 32bytes up to 128KiB.

As can be seen, the Windows Vista allocator has a similar performance profile to the Hoard allocator. It, however, is slightly faster than Hoard and more comparable in speed to the Lockless memory allocator for small to mid-range sized allocations. For large allocations, the Vista allocator suffers from catastrophic performance loss. It appears that it either calls into the kernel far too much, or uses a very heavy-weight synchronization method. In nearly all situations, the Lockless memory allocator is quite a bit faster.
MySQL
An important load for many businesses is that of their database servers. The speed of memory allocators may greatly change your server's performance. The following graph describes read-only performance on a 8 core Xeon machine when different allocators are used.
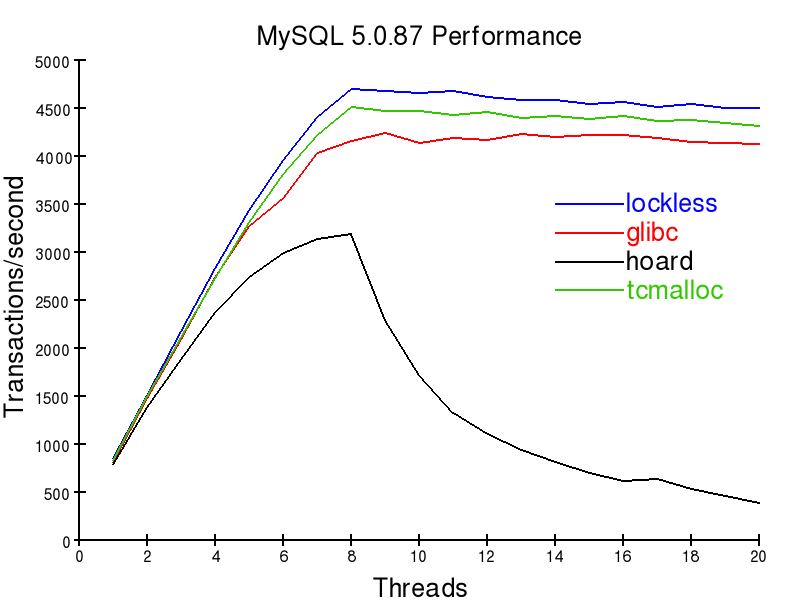
Write latency is also affected by the allocator choice. By switching to a different allocator, a large decrease in cpu usage and request latency may be obtained. More on this is at theMySQL Performance article.
Summary
The Lockless allocator is typically much faster than the best memory allocators developed to date, in both a single and multithreaded context. The Lockless allocator can be an order of magnitude faster in some situations, for example server loads. However, note that the amount of performance gain will be application-specific. Modern applications written in high level languages like C++ and Python tend to spend a significant amount of their time dealing with memory. It is expected that the performance increase for mission-critical applications may be as much as a couple of cpu speed grades. By purchasing the Lockless memory allocator, you may be able to save much more than what would be needed to be spent for extra hardware.















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









