







相关概念
正则表达式(regular expression)描述了一种字符串的模式
模式:一种特定的字符串模式,这个模式是通过一些特殊符号组成的
正则表达式的功能
1-数据验证
2-数据检索
正则表达式的特点
可读性差
通用性强
Python中正则表达式模块:import re
匹配方式
示例:
# 导包
import re
# 1-match匹配:只能匹配字符串开头
my_str = "鸡不宁,狗不叫,小小牛马,收到收到"
"""
re.match(pattern='学习', string=my_str, flags=)
pattern:正则表达式
string:被匹配的内容
flags:标准位
"""
result = re.match(pattern='牛马', string=my_str)
if result is not None:
print(f"匹配成功,结果为{result.group()}")
else:
print("匹配失败")
# 2-search匹配:可以查找整个字符串,但是只能返回第一个匹配到的内容
"""
re.search(pattern='牛马', string=my_str, flags=)
pattern: 正则表达式
string: 被匹配的内容
flags: 标志位
"""
result = re.search(pattern='牛马', string=my_str)
if result is not None:
print(f"匹配成功,结果为{result.group()}")
else:
print("匹配失败")
# 3-findall匹配:以列表的形式返回所有匹配到的内容
"""
re.search(pattern='牛马', string=my_str, flags=)
pattern: 正则表达式
string: 被匹配的内容
flags: 标志位
"""
result = re.findall(pattern='牛马', string=my_str)
print(result)
"""
if 对象变量
等同于
if 对象变量 is not None or len(对象变量) == 0
"""
if result is not None:
print(f"匹配成功,结果为{result}")
else:
print("匹配失败")总结:
match方式:
格式:re.match(正则表达式, 要匹配的字符串, 标志位)
功能:只能从起始位置开始匹配,如果匹配成功返回匹配到的位置和内容,如果匹配不到返回None
search方式
格式:re.search(正则表达式, 要匹配的字符串, 标志位)
功能:直接扫描整个字符串,如果匹配成功只返回第一个匹配到的位置和内容,如果匹配失败返回None
findall方式
格式:re.findall(正则表达式, 要匹配的字符串, 标志位)
功能:直接扫描整个字符串,如果匹配成功会将所有匹配到的内容封装到列表中返回,如果匹配失败返回空列表
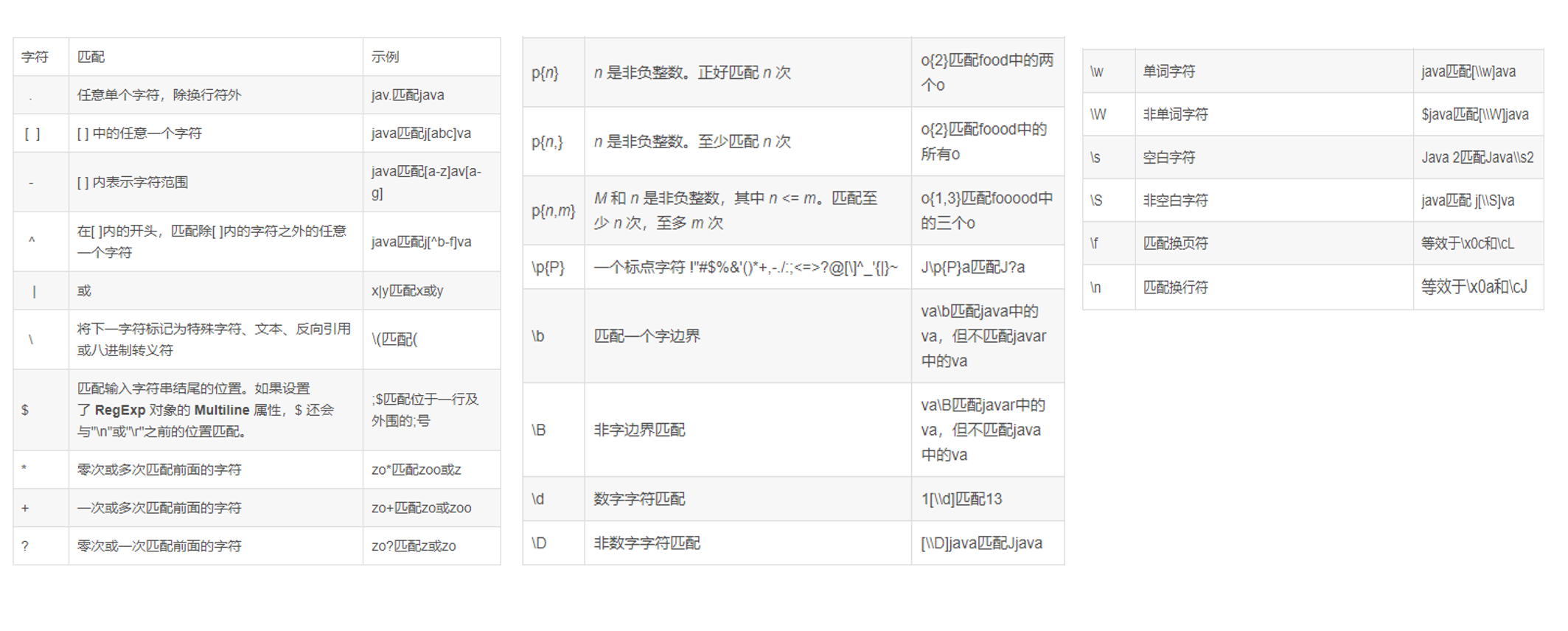
匹配规则
示例:
import re
def show(result):
"""
定义函数进行结果查看
:param result:被查看的结果
:return:
"""
if result:
print(f"匹配成功,结果为:{result.group()}")
else:
print(f"匹配失败")
print('-' * 30 + '匹配单个字符' + '-' * 30)
# .: 匹配任意一个字符(字母、数字、特殊符号以及汉字),除了\n换行符 次数==1
result = re.match(pattern='......', string='ykl_6&\n牛')
show(result)
# []: 匹配括号中的任意一个字符
result = re.match(pattern='[a-zA-Z0-9_&][a-zA-Z0-9_&][a-zA-Z0-9_&][a-zA-Z0-9_&]', string='ykl_6&\n牛')
show(result)
# \w:匹配任意一个正常单词(字母、数字、下划线、汉字)
result = re.match(pattern='\w', string='张0ykl_6&\n牛')
show(result)
# \d:匹配任意一个数字
result = re.match(pattern='\d', string='0ykl_6&\n牛')
show(result)
# \s:匹配任意一个空白字符(\t制表符或者空格和\n换行符)
result = re.search(pattern='\s', string='0yk\tl_6\n&')
show(result)
print('-' * 30 + '匹配多个字符' + '-' * 30)
# *:匹配前一个字符出现0次或者多次 次数>=0
result = re.match(pattern='https://.*', string='https://www.baidu.com')
show(result)
# ?:匹配前一个字符出现0次或者1次 次数=0或者=1
result = re.match(pattern='https?://.*', string='http://www.baidu.com')
show(result)
# +:匹配前一个字符出现1次或者多次 次数 >= 1
result = re.match(pattern='https://.+', string='https://www.baidu.com')
show(result)
# |:x或者y
result = re.match(pattern='http://.*|.*', string='https://www.baidu.com')
show(result)
print('-'*30+'匹配指定字符次数'+'-'*30)
# {x}:匹配前一个字符正好出现x次
result = re.match(pattern='\d{7}',string='1234526')
show(result)
# {x,}:匹配前一个字符至少出现x次,比如:密码至少为6位(只能是大小写字母、数字和下划线)
result = re.match(pattern='[a-zA-Z0-9_]{6,}', string='asdASB12_')
show(result)
# {x, y}: 匹配前一个字符至少出现x次,最多出现y次,比如:密码至少为6位,最多为8位(只能是大小写字母、数字和下划线)
# 可以使用$表示结尾和^表示开头配合固定字符个数进行限制
result = re.search(pattern='^[a-zA-Z0-9_]{6,9}$', string='asdASB12_')
show(result)
# 当^在[]里面时,表示除了这个[]中所有字符之外的所有字符
result = re.match(pattern='[^0-9a-zA-Z]', string='_+_asbasdfsda16516515')
show(result)
# result = re.match(pattern='J{P}a', string='J?a')
# show(result)总结:
加强案例
import re
def show(result):
"""
定义函数进行结果查看
:param result: 被查看的结果
:return:
"""
if result:
print(f"匹配成功,结果为:{result.group()}")
else:
print(f"匹配失败")
print('-' * 30 + 'match方式匹配' + '-' * 30)
# 1.匹配出微博中的所有话题,举例:#幸福是奋斗出来的#
result = re.match(pattern='#.+#', string='#幸福是奋斗出来的#')
show(result)
# 2.匹配出1开头的所有11位手机号码,举例:18866668888
result = re.match(pattern='^1\d{10}', string='18866668888')
show(result)
# 3.匹配出163的邮箱地址,且@符号之前有4到10位字母数字下划线,举例: binzi@163.com
result = re.match(pattern='[a-zA-Z0-9_]{4,10}@163\.com', string='binzi@163.com')
show(result)
print('-' * 30 + 'findall方式匹配' + '-' * 30)
# 1.匹配出微博中的所有话题, 举例: #幸福是奋斗出来的#
"""
贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
正则中的量词:*和+,默认都是贪婪模式的匹配,可以在他们后面加?将其变为非贪婪模式。
常用贪婪模式如: .*
常用非贪婪模式如: .*?
"""
result = re.findall(pattern='#.+?#',
string="此处省略很多内容#幸福是奋斗出来的#此处省略很多内容#北京奥运会#此处省略很多内容#国足出线了#此处省略很多内容#幸福是奋斗出来的#此处省略很多内容#幸福是奋斗出来的#魂牵梦萦魂牵梦萦")
print(result)
result = re.findall(pattern='#.+#',
string="此处省略很多内容#幸福是奋斗出来的#此处省略很多内容#北京奥运会#此处省略很多内容#国足出线了#此处省略很多内容#幸福是奋斗出来的#此处省略很多内容#幸福是奋斗出来的#魂牵梦萦魂牵梦萦")
print(result)
# 2.匹配出1开头并且第二位不是1、2、4、0的所有11位手机号码,举例:18866668888
result = re.findall(pattern='1[^1240]\d{9}',
string="此处省略很内容18866668888此处省略很内容15866668888此处省略很内容13866668888此处省略很内容18966668888此处省略很内容15066668888")
print(result)
# 3.匹配出163的邮箱地址,且@符号之前有4到10位字母数字下划线,举例: binzi@163.com
result = re.findall(pattern='[a-zA-Z0-9_]{4,10}@163\.com', string='此处省略很内容binzi@163.com此处省略很内容binzi@qq.com此处省略很内容binzi@126.com')
print(result)
# 4.编写正则表达式匹配格式为:YYYY-MM-DD的日期字符串
text="我们计划结婚的日期是2024-08-27和计划离婚的日期是2024-08-28"
result = re.findall(pattern='\d{4}-\d{2}-\d{2}', string=text)
print(result)匹配分组
import re
# 需求:匹配出0~100之间的所有数字字符结果:
result = re.match(pattern='100|[1-9]?[0-9]', string='100')
print(result.group())
# 需求:匹配出含有163、126、qq、foxmail、gmail的邮箱且用户名位数为4到12位和域名后缀为com、cn、net的所有邮箱
# 比如:helloykl@qq.com
# 比如:helloykl@163.com
# 比如:helloykl@163.cn
# 比如:helloykl@126.net
# 可以使用(xxx)的形式对匹配项进行分组,匹配成功后可以从下标1开始获取对应分组匹配到的内容,超出分组下标会报错
result = re.match(pattern='(\w{4,12})@(qq|163|126|gmail)\.(com|cn|net)', string='helloykl@163.cn').group()
result = re.match(pattern='(\w{4,12})@(qq|163|126|gmail)\.(com|cn|net)', string='helloykl@163.cn').group(0)
result = re.match(pattern='(\w{4,12})@(qq|163|126|gmail)\.(com|cn|net)', string='helloykl@163.cn').group(1)
result = re.match(pattern='(\w{4,12})@(qq|163|126|gmail)\.(com|cn|net)', string='helloykl@163.cn').group(2)
result = re.match(pattern='(\w{4,12})@(qq|163|126|gmail)\.(com|cn|net)', string='helloykl@163.cn').group(3)
print(result)匹配替换
import re
# 编写一个正则表达式用于去除HTML标签,保留纯文本,比如:<p><b>欢迎</b>您的加入</p>
result = re.findall(pattern='<.*?>', string='<p><b>欢迎</b>您的加入</p>')
print(result)
"""
re.sub(pattern='<.*>',repl="",string="<p><b>欢迎</b>您的加入</p>")
pattern:正则表达式
repl:要替换的字符串
string:要被替换的字符串
"""
clean_text = re.sub(pattern='<.*?>', repl="", string="<p><b>欢迎</b>您的加入</p>")
print(clean_text)匹配切分
# 导包
import re
# 需求:将将"18203987777、ainaoteng@foxmail、192.168.88.166"
"""
re.split(pattern="、", string=user_str, maxsplit=10)
pattern:正则表达式
string:要被切分的字符串
maxsplit:最大切分次数,如果设置了最大次数,则最多切分maxsplit次数,如果字符串没有被切分完,剩余部分会作为一整个字符串返回
"""
user_str = "18203987777、ainaoteng@foxmail、192.168.88.166"
split_str = re.split(pattern="、",string=user_str, maxsplit=2)
print(split_str)匹配标志位
# 导包
import re
# 需求,已知验证码为:A1Da,要求用户输入匹配正确的验证码,不区分
yzm = 'A1Da'
# 从键盘用户输入验证码
user_yzm = input("请输入验证码:")
# 验证用户输入的是否正确
# if yzm.lower() == user_yzm.lower():
# print("登录成功!!!")
# else:
# print("验证失败!!!")
# 使用正则表达式实现需求
# flags = re.I表示不区分大小写
result = re.match(pattern=yzm, string=user_yzm, flags=re.I)
if result:
print("匹配成功")
else:
print("匹配失败")
# 需求:真正地匹配任意字符串
my_str = "黑马\n程序员"
# flags = re.S表示换行符也能被匹配到
result = re.match(pattern=".*", string=my_str, flags=re.S)
if result:
print(f"匹配成功:{result.group()}")
else:
print("匹配失败")














 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









