







 OpenVoice是一种开源的声音克隆工具,基于深度学习实现语音风格转移。它利用音色转换器和基本说话者文本转语音模型,能精准克隆音色并控制语音风格。适用于虚拟主持人、语音助手、汽车导航等多个场景。文章详细介绍了OpenVoice的工作原理、使用方法及优势。
OpenVoice是一种开源的声音克隆工具,基于深度学习实现语音风格转移。它利用音色转换器和基本说话者文本转语音模型,能精准克隆音色并控制语音风格。适用于虚拟主持人、语音助手、汽车导航等多个场景。文章详细介绍了OpenVoice的工作原理、使用方法及优势。
引言:
在当今数字时代,人工智能技术的快速发展为我们带来了许多便利和创新。其中,声音克隆技术是人工智能中一个非常有趣和前景广阔的领域。今天,我们要介绍的就是基于深度学习的声音克隆工具——OpenVoice。通过本文,你将了解到OpenVoice的基本概念、工作原理、使用方法以及应用场景。
什么是OpenVoice?
OpenVoice是一个开源的声音克隆工具,基于深度学习模型实现对目标音频的声音克隆和转换。它利用了声学模型和语音合成技术,可以将源音频中的语音样式转移到目标音频中,从而实现与目标音频声音高度相似的声音克隆效果。
OpenVoice的工作原理
OpenVoice 框架的技术框架非常有效,而且实现起来非常简单。众所周知,克隆任何说话者的音色、添加新语言并同时实现对语音参数的灵活控制可能具有挑战性。之所以如此,是因为同时执行这三个任务需要使用大量组合数据集来使受控参数相交。此外,在常规的单扬声器文本到语音合成中,对于不需要语音克隆的任务,更容易添加对其他样式参数的控制。在此基础上,OpenVoice 框架旨在将即时语音克隆任务分解为子任务。该模型建议使用基础说话人文本转语音模型来控制语言和风格参数,并采用音色转换器将参考音色包含到生成的语音中。下图展示了该框架的架构。
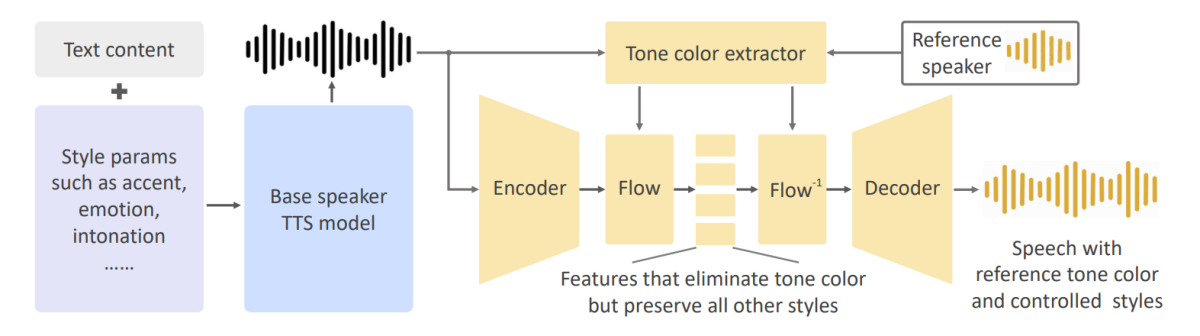
OpenVoice 框架的核心采用两个组件:音色转换器和基本说话者文本转语音或 TTS 模型。基本说话人文本转语音模型是单说话人或多说话人模型,允许精确控制风格参数、语言和口音。该模型生成语音,然后将其传递到音色转换器,将基本扬声器音色更改为参考扬声器的音色。
OpenVoice 框架在基本说话者文本到语音模型方面提供了很大的灵活性,因为它可以采用 VITS 模型,稍作修改,使其能够在其持续时间预测器和文本编码器中接受语言和风格嵌入。该框架还可以采用商业上便宜的 Microsoft TTS 等模型,或者可以部署能够接受样式提示的 InstructTTS 等模型。目前,OpenVoice框架采用VITS模型,尽管其他模型也是可行的选择。
如何使用OpenVoice?
要使用OpenVoice进行声音克隆,你需要按照以下步骤操作:
1. 准备音频数据:收集所需的源音频和目标音频,确保音频格式为wav,采样率为16kHz或22.05kHz。
2. 安装OpenVoice:在GitHub上找到OpenVoice的项目地址,按照项目文档进行安装和配置。
3. 训练模型:使用源音频和目标音频训练OpenVoice的深度学习模型,该过程可能需要几个小时甚至几天的时间。
4. 声音转换:利用训练好的模型将源音频转换为与目标音频声音相似的音频。
OpenVoice的应用场景
OpenVoice在各种场合都有广泛的应用前景,包括但不限于:
1. 虚拟主持人:使用OpenVoice可以为直播、广播等场合创建具有独特声音的虚拟主持人。
2. 语音助手:为智能语音助手提供更多的声音选择,满足用户个性化需求。
3. 汽车导航:通过OpenVoice为汽车导航提供更自然、友好的语音提示。
4. 游戏音效:为游戏角色创建独特的声音,增强玩家体验。
5. 电影配音:使用OpenVoice为电影配音,实现更自然、真实的配音效果。
OpenVoice的优势
OpenVoice为我们提供了以下三大优势,使得语音处理工作变得更为简单高效:
-
精准的音色克隆:OpenVoice能够准确地克隆参考音色,并生成多种语言和口音的语音。这意味着,无论我们想要模仿哪种特定的声音或口音,OpenVoice都能为我们提供有力的支持。
-
灵活的语音风格控制:除了基本的语音生成功能外,OpenVoice还提供了对语音风格的细致控制。无论是情绪、口音还是其他风格参数,如节奏、停顿和语调,我们都可以根据需要进行调整,从而生成出更符合我们期望的语音效果。
-
零样本跨语言语音克隆:OpenVoice的另一个显著特点是其跨语言语音克隆的能力。这意味着,无论我们想要生成哪种语言的语音,还是参考语音是哪种语言,都不需要在庞大的多语言训练数据集中预先包含这些语言。这一特性大大拓宽了OpenVoice的应用范围,使得跨语言语音处理变得更加便捷。
环境准备
conda create -n openvoice python=3.9
conda activate openvoice
git clone git@github.com:myshell-ai/OpenVoice.git
cd OpenVoice
pip install -e .数据准备
OpenVoice需要训练数据和测试数据,其中训练数据是用来训练模型的,测试数据是用来评估模型效果的。训练数据应该包含多个人的声音数据,每个人的声音数据应该包含多个音频文件,每个音频文件的长度应该在1秒到10秒之间。测试数据可以是任意人的声音数据,但是应该和训练数据不同。
语音风格控制例子:
初始化:
import os import torch from openvoice import se_extractor from openvoice.api import BaseSpeakerTTS, ToneColorConverter
ckpt_base = 'checkpoints/base_speakers/EN'
ckpt_converter = 'checkpoints/converter'
device="cuda:0" if torch.cuda.is_available() else "cpu"
output_dir = 'outputs'
base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)
base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
os.makedirs(output_dir, exist_ok=True)
获取色调嵌入
source_se是基础扬声器的音色嵌入。它是基本说话者生成的多个句子的平均值。我们在这里直接提供结果,但读者可以自行提取source_se。
source_se = torch.load(f'{ckpt_base}/en_default_se.pth').to(device)
下面的reference_speaker.mp3指向我们要克隆其声音的引用的音频短片。我们在这里提供了一个例子。如果您使用自己的参考扬声器,请确保每个扬声器都有一个唯一的文件名。se_extractor将使用音频的文件名保存targeted_se,并且不会自动覆盖。
reference_speaker = 'resources/example_reference.mp3' target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, target_dir='processed', vad=True)
推理:
save_path = f'{output_dir}/output_en_default.wav'
# Run the base speaker tts
text = "This audio is generated by OpenVoice."
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='default', language='English', speed=1.0)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
尝试不同的风格和速度:
样式可以由base_speaker_tts.tts方法中的speaker参数控制。可供选择:友好、愉快、兴奋、悲伤、愤怒、恐惧、大喊大叫、窃窃私语。注意,色调嵌入需要更新。速度可以由速度参数控制。让我们试着以0.9的速度低声说话。
source_se = torch.load(f'{ckpt_base}/en_style_se.pth').to(device)
save_path = f'{output_dir}/output_whispering.wav'
# Run the base speaker tts
text = "This audio is generated by OpenVoice."
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='whispering', language='English', speed=0.9)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
尝试使用不同的语言:
OpenVoice只需更换基本扬声器即可实现多语言语音克隆。我们在这里提供了一个以中文为母语的例子,我们鼓励读者尝试demo_part2.ipynb进行详细的演示。
ckpt_base = 'checkpoints/base_speakers/ZH'
base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)
base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')
source_se = torch.load(f'{ckpt_base}/zh_default_se.pth').to(device)
save_path = f'{output_dir}/output_chinese.wav'
# Run the base speaker tts
text = "今天天气真好,我们一起出去吃饭吧。"
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='default', language='Chinese', speed=1.0)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
技术是好的。对于将部署OpenVoice供公众使用的人:我们为您提供添加水印的选项,以避免潜在的滥用。请参阅ToneColorConverter类。无论是否添加水印,MyShell都保留检测音频是否由OpenVoice生成的能力。


















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











