






 文章探讨了电话银行推广的基于语音的生物识别技术,以及使用生成式AI如何轻易地克隆语音。作者详细描述了如何利用Python库如tortoise-tts和相关依赖进行语音克隆实验,警示了潜在的安全威胁。
文章探讨了电话银行推广的基于语音的生物识别技术,以及使用生成式AI如何轻易地克隆语音。作者详细描述了如何利用Python库如tortoise-tts和相关依赖进行语音克隆实验,警示了潜在的安全威胁。
最近给电话银行打电话,鼓励我“将我的声音用作密码”。他们说这样更快更安全。你只需要说一些类似“我的声音是我的密码”的话,你就能通过安全验证。这让我想到了生成式AI和语音克隆,它究竟有多容易做到以及有多大的风险。我花了几个小时的时间,就能够从WhatsApp的语音留言中克隆出某人的声音!理论上来讲,你只需要至少三个大约10秒的样本,就能够克隆出某人的声音。语音样本可以来自任何地方。微信语音、电话记录、播客、视频、演讲…
需求
一台安装了Python 3.8的系统。我使用的是带有Python 3.11的iMac,但它没有工作。我必须专门使用Python 3.8。
你将需要PIP,这是一个Python包管理器。
您将需要设置一个Python虚拟环境。我使用的是“venv”,如果您还没有安装它,可以使用PIP安装它。
你需要安装“git”。
你需要一个名为“tortoise-tts”的Python库。你不能只是“pip install”它。你需要以一种非常特定的方式安装它,我一会儿会介绍。
你需要安装一些依赖项。我在我的iMac上使用Homebrew安装了“lapack”和“hiredis”。只需简单的“brew install”即可。您可能已经安装了它们,也可能没有,因此尝试安装“tortoise-tts”时可能会有问题。如果遇到问题,很可能是因为这个原因。
您需要使用PIP安装一个名为“six”的库。
您将需要获取一些音频文件。我登录WhatsApp Web并找到了一些来自某人的语音笔记。我能够将其下载为*.ogg文件到我的桌面。
你需要一个音频编辑器,我用的是Audacity。它是免费的,功能强大。
安装
克隆“tortoise-tts”存储库
% git clone https://github.com/neonbjb/tortoise-tts使用“venv”设置虚拟环境。
% python3 -m venv tortoise-tts
% source tortoise-tts/bin/activate
(venv) % cd tortoise-tts
(venv) tortoise-tts %正如我之前提到的,对于这个,你将需要Python 3.8。我已经在我的iMac上安装了它,所以我只需精确地使用路径引用它。
升级PIP、setuptools和wheel
(venv) tortoise-tts % python3.8 -m pip --upgrade pip
(venv) tortoise-tts % python3.8 -m pip install --upgrade setuptools wheel我需要使用Homebrew在我的iMac上安装“lapack”和“hiredis”。在你的系统中,可能不需要这一步,但在我的系统中,我必须这样做。
(venv) tortoise-tts % brew install lapack
(venv) tortoise-tts % brew install hiredis预先安装“six”和“python-dateutil”
(venv) tortoise-tts % python3.8 -m pip install six python-dateutil安装应用程序依赖包
(venv) tortoise-tts % python3.8 -m pip install -r requirements.txt安装“tortoise-tts”
(venv) tortoise-tts % python3.8 setup.py install希望一切都能顺利安装。我的安装有点棘手,但使用Python 3.8并重新安装上面提到的依赖项有所帮助。
测试“tortoise-tts”
“tortoise-tts”应用程序附带了许多预置的声音。进行简单的测试以确保它正常工作是值得的。
(venv) tortoise-tts % ls -la tortoise/voices
total 16
drwxr-xr-x 34 user group 1088 16 Jun 17:48 .
drwxr-xr-x 15 user group 480 16 Jun 16:30 ..
-rw-r--r--@ 1 user group 6148 16 Jun 18:20 .DS_Store
drwxr-xr-x 5 user group 160 16 Jun 15:42 angie
drwxr-xr-x 5 user group 160 16 Jun 15:42 applejack
drwxr-xr-x 3 user group 96 16 Jun 15:42 cond_latent_example
drwxr-xr-x 6 user group 192 16 Jun 15:42 daniel
drwxr-xr-x 6 user group 192 16 Jun 15:42 deniro
drwxr-xr-x 5 user group 160 16 Jun 15:42 emma
drwxr-xr-x 5 user group 160 16 Jun 15:42 freeman
drwxr-xr-x 5 user group 160 16 Jun 15:42 geralt
drwxr-xr-x 5 user group 160 16 Jun 15:42 halle
drwxr-xr-x 6 user group 192 16 Jun 15:42 jlaw
drwxr-xr-x 4 user group 128 16 Jun 15:42 lj
drwxr-xr-x 4 user group 128 16 Jun 15:42 mol
drwxr-xr-x 5 user group 160 16 Jun 15:42 myself
drwxr-xr-x 6 user group 192 16 Jun 15:42 pat
drwxr-xr-x 6 user group 192 16 Jun 15:42 pat2
drwxr-xr-x 7 user group 224 16 Jun 15:42 rainbow
drwxr-xr-x 5 user group 160 16 Jun 15:42 snakes
drwxr-xr-x 6 user group 192 16 Jun 15:42 tim_reynolds
drwxr-xr-x 6 user group 192 16 Jun 15:42 tom
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_atkins
drwxr-xr-x 5 user group 160 16 Jun 15:42 train_daws
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_dotrice
drwxr-xr-x 5 user group 160 16 Jun 15:42 train_dreams
drwxr-xr-x 5 user group 160 16 Jun 15:42 train_empire
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_grace
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_kennard
drwxr-xr-x 7 user group 224 16 Jun 15:42 train_lescault
drwxr-xr-x 4 user group 128 16 Jun 15:42 train_mouse
drwxr-xr-x 5 user group 160 16 Jun 15:42 weaver
drwxr-xr-x 6 user group 192 16 Jun 15:42 william或许是这样:
(venv) tortoise-tts % python3.8 tortoise/do_tts.py --text "I'm going to say this" --voice random --preset fast这将随机使用上述列表中的一种声音来说:“我将说这个”。请注意,处理需要一些时间。我有一台性能相对强大的机器,生成这个单句大约花费了20-30分钟。
结果将存储在以下目录:
(venv) tortoise-tts % ls -la results
total 3272
drwxr-xr-x 8 user group 256 16 Jun 18:48 .
drwxr-xr-x 25 user group 800 16 Jun 16:30 ..
-rw-r--r--@ 1 user group 178234 16 Jun 16:29 random_0_0.wav
-rw-r--r--@ 1 user group 182330 16 Jun 16:29 random_0_1.wav
-rw-r--r--@ 1 user group 186426 16 Jun 16:29 random_0_2.wav您还可以将一个文本文件传递给它,但我希望您有一个用于处理的GPU,否则您将等待几个小时。
克隆声音
在Audacity中打开您的音频文件。
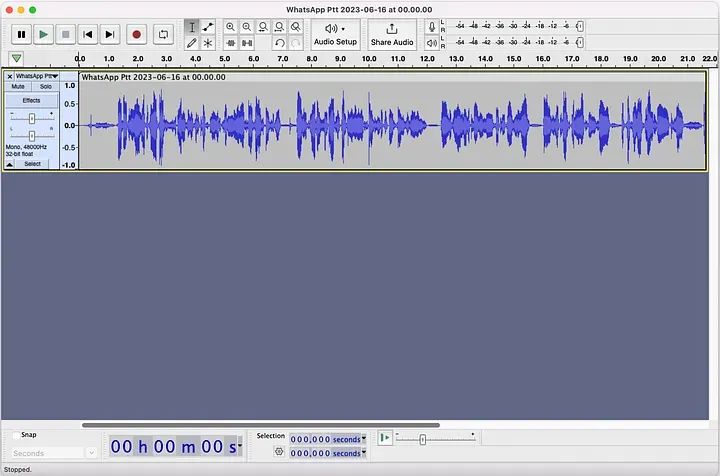
您只需要至少三个大约10秒的样本。我假设提供的越多,结果就越好,但花费的时间就越长。
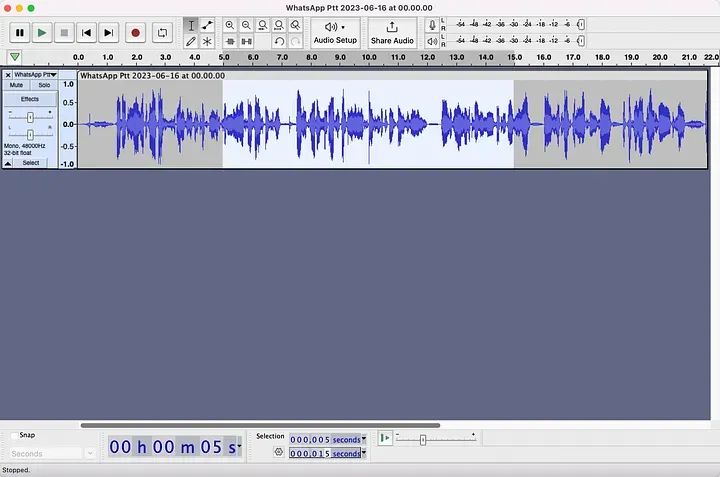
查看底部的“选择”。我设置为从第5秒到第15秒选择。您真的希望您的样本包含尽可能多的语音。
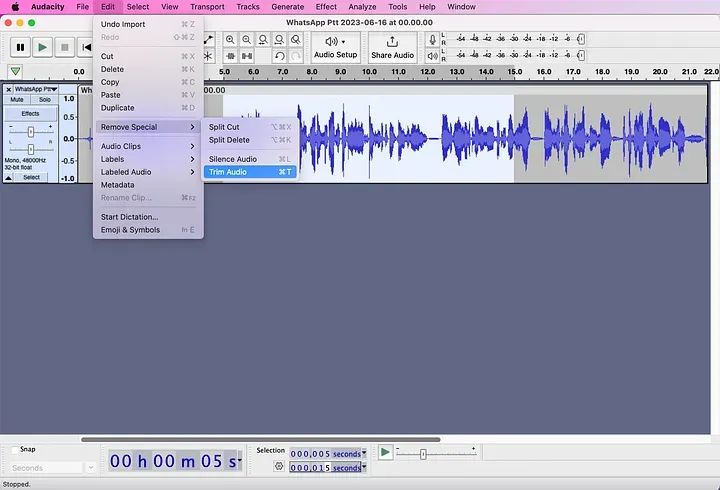
您将看到图像已被剪裁为我选择的10秒。
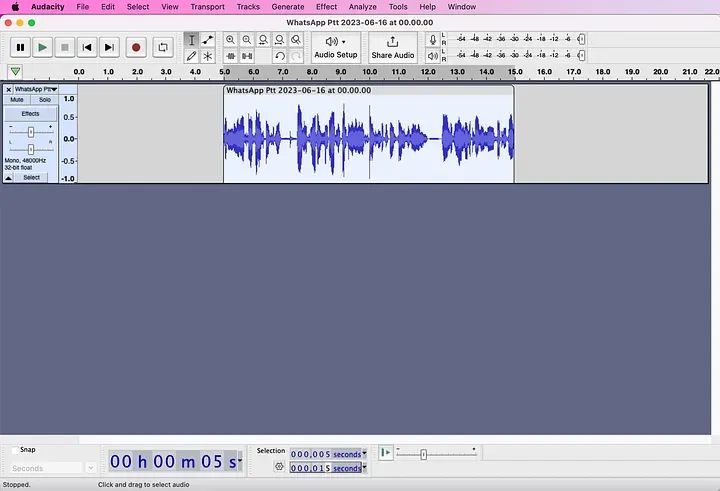
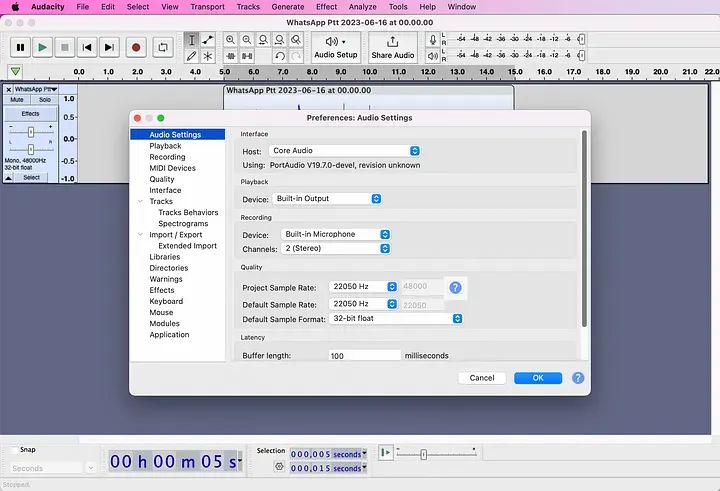
您会注意到左边写着样本是48000 Hz,但它需要是22050 Hz。进入Audacity的首选项,在“音频设置”下,确保“项目采样率”和“默认采样率”都是22050 Hz。请注意,当您点击“确定”时,左侧不会更新。它仍然会显示48000 Hz,但我认为那是一个错误。它实际上已经更新。
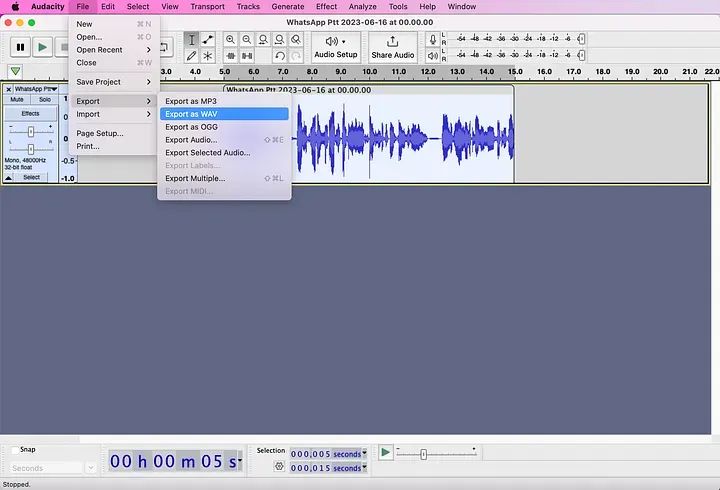
现在,您需要将准备好的文件导出为WAV文件。
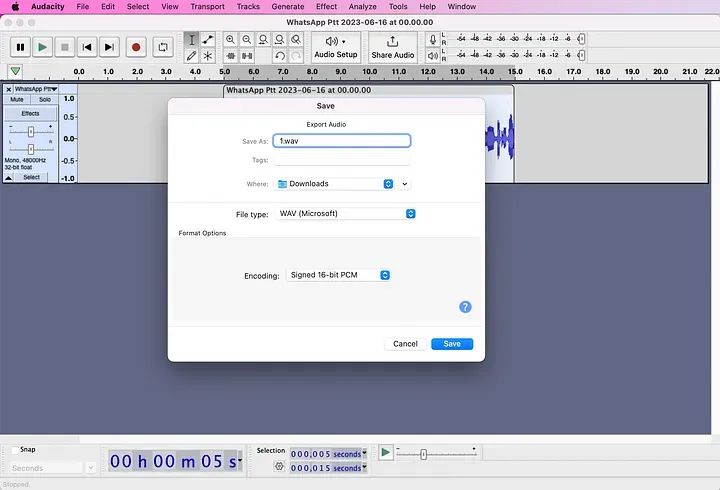
您将要重复此过程,创建三个分别命名为1.wav、2.wav和3.wav的单独样本。在“voices”下创建一个目录并将三个文件复制到那里。我取名叫“mytest”。
(venv) tortoise-tts % ls -la tortoise/voices/mytest
total 4064
drwxr-xr-x 5 user group 160 16 Jun 22:15 .
drwxr-xr-x 34 user group 1088 16 Jun 22:15 ..
-rw-r--r-- 1 user group 661544 16 Jun 22:11 1.wav
-rw-r--r-- 1 user group 485144 16 Jun 22:13 2.wav
-rw-r--r-- 1 user group 928518 16 Jun 22:14 3.wav然后您可以这样运行它:
(venv) tortoise-tts % python3.8 tortoise/do_tts.py --text "This is an A.I. generated voice, what do you think?" --voice mytest --preset fast在显示任何进展之前,它需要一段时间,但完成后将如下所示。
venv) tortoise-tts % python3.8 tortoise/do_tts.py --text "This is an AI generated voice, what do you think?" --voice mytest --preset fast
Generating autoregressive samples..
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 96/96 [12:54<00:00, 8.07s/it]
Computing best candidates using CLVP
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 96/96 [03:53<00:00, 2.43s/it]
Transforming autoregressive outputs into audio..
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 80/80 [04:19<00:00, 3.24s/it]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 80/80 [02:57<00:00, 2.22s/it]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 80/80 [02:41<00:00, 2.02s/it]和以前一样,结果将存储在“results”中。重复这个过程两次才能找到三个正确捕捉声音的样本,但效果非常好。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除

















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









