







张量:多维数组(列表):
0阶:也叫标量,就是一个元素,或一个数。
1阶:也叫向量,就是一个一维列表。
2阶:也叫矩阵,不是一个二维列表。
N阶:张统称张量(tensor),N维数组(列表),开始处有N个“ [ ”。
张量类型必须一致;
偏导数--任何函数,都有对应各个自变量的偏导数。也叫局部导数
tf2用tf1时: 在tf.xxx中插入.compat.v1.例:tf.compat.v1.xxx
激活函数是区别于多层感知机与神经网络的依据。
1.sigmoid

x=0时等于0.5,这时最线性,-2至2之间较线性,越向外压缩越厉害。
它的作用:把最终输出归一化到0-1之间。并且在0附近正常映射,正负偏离过大的压缩为1或0限制,即有忽视正负2后面的值。
2.sofmax
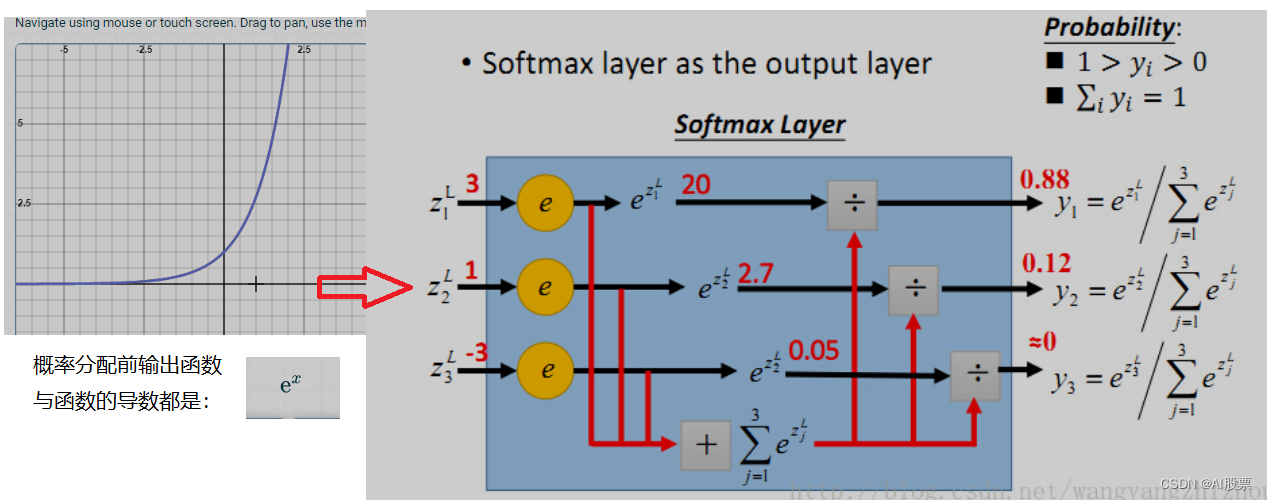
1) 将前级各点输出e^x => 各点得分。x=0得分为1,x越大得分会剧增。意义:把前级输出最大与 最小差距放大,主要得到最大值的那个为概率最大分。
而sigmoid输出概率是根据前级输出值平等求分,两端部分不但没放大,相反被压缩到1或0。
2)softmax会根据所有输出标签总值来分配每一个输出标签的概率值,总概率和等于1。
而sigmoid只会对每一个输出标签得到单独概率值,它可不管其它输出和总概率。
3) 如果输出全为正时,
如果用sigmoid:得到的y_将是0.5*1之间绝对概率,且越大越被压缩严重变形的结果。
如果用softmax:由于此函数中间还会统计某点得分/全部点总分。是个比较值,得到0-1概率
--------------------------所以sigmoid不可用于全正的地方。
图片卷积笔记——改变卷积核
正负相反时:凹凸变换效果;
中间列数越近右正时:图像接近原图,接近左负时:黑色越白。
只有一个输出的训练,输出标签可以是只有一列的二维的表格;也可以是一维series数组;还可以是只有一列的二维数组
多标签(multi-label)和多分类(multi-class):
多标签分类:每个标签都可能从0-1概率,因为多标签间不是同一分类。
采用sigmoid做输出层的激活函数,这里没有采用softmax,就是希望sigmoid 对每一个 节点的值做一次激活,从而输出每个节点分别是 1 概率;
采用binary_crossentropy损失函数函数,这样使得模型在训练过程中不断降低output和 label之间的交叉熵。其实就相当于模型使label为1的节点的输出值更靠近1,label为0的节点 的输出值更靠近0。最终模型的输出就是一个结构序列。
多分类分类:所有标签概率和必须=1,因为它们是同一分类,取概率最大者为正确分类。
激活函数经验性的总结
对于分类任务的输出层,二分类的输出层的激活函数常选择sigmoid,
多分类的输出层的激活函数常选择softmax;
对于回归任务根据输出值确定激活函数或者不使用激活函数???
对于隐藏层的激活函数通常会选择使用ReLU函数。
tf.显示张量变量的值
如果直接print(x1)显示的是张量类型等信息
方法1. 利用tf.compat.v1.Session会话显示X1值。
tf.compat.v1.disable_eager_execution()
tf.compat.v1.reset_default_graph()
x1=tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
print(x1)
with tf.compat.v1.Session() as sess:
#sess.run(tf.compat.v1.global_variables_initializer())
print('x1=',sess.run(x1))
out:
Tensor("softmax_cross_entropy_with_logits_15/Reshape_2:0", shape=(2,), dtype=float32)
x1= [0.02215516 3.0996735 ]方法2:
import keras.backend as K
print(K.eval(xxx))tf.张量运算
- tf.multiply() ------------矩阵元素对应相乘,双方维数必须一样
- tf.matmul( [[a,b], [c,d]] , [[1,2], [3,4]] ) [[a*1+b*2],[a*3+b*4],[c*1+d*2],[c*3+d*4]] -----------3维以上先算里面2维矩阵;双方总元素数量必须相等。
tf.maximum() tf.math.log() tf.exp() tf.abs()














 1778
1778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









