






前言
模型保存是模型训练整个流程不可缺少的一环。
在模型训练结束时我们需要保存,从而方便我们进行部署使用,或者未来用来继续训练,例如迁移学习或者增量学习;
在训练过程中我们往往也会定期保存,因为机器训练时间过长,难免会出现出现一些意想不到的故障需要重启。有了这些定期保存的模型,我们能够进行断点恢复;
还有时我们希望导出仅仅对于部署有用的部分,删掉不必要的部分,例如和优化器 (optimizer) 相关的一些参数。
Tensorflow 从 TF 1 到 TF 2 一个较为重大的改变就是模型的导出和加载方式。虽然体现在 API 上的变动并不大,甚至说 TF 1 导出的模型 (SavedModel)依然可以通过 TF 2 进行加载和执行,但其实内部的实现还是有较大的区别的。本文将从模型参数和整体模型的这两个方面,来聊一聊当我们保存模型时我们到底在保存什么。
图文无关。搬出自家狗子看能不能吸引点人气,惭愧惭愧。
保存模型时我们在保存什么
当我们保存模型时,往往有两种情况,一种是我们保存所有和模型相关的参数,例如卷积神经网络里所有的 weights 和 bias 参数;一种是保存整个模型,也就是说除了模型的参数,我们还会保存模型的结构。用 TF 的语言来说,一种是导出 Checkpoint,第二种是导出 SavedModel。
一般来说,Checkpoint 能够较为方便我们进行断点继续训练,以及进行迁移学习,但是使用Checkpoint 需要我们先使用原始代码构建模型,然后再读入参数;SavedModel 本身包含了进行模型推断的全部信息,非常便于部署执行,但是并不易于进行迁移学习或是重新训练。
什么是模型 (Model)
在讨论如何保存模型之前,我们不妨先来看看在训练的时候我们是怎么构建一个模型的。

在 TF 1 里,严格来说是没有模型这个概念的。我们直接和计算图进行交互,首先写出计算图,然后开启一个 Session,在进行保存的时候,我们直接保存 Session 里的所有的变量。
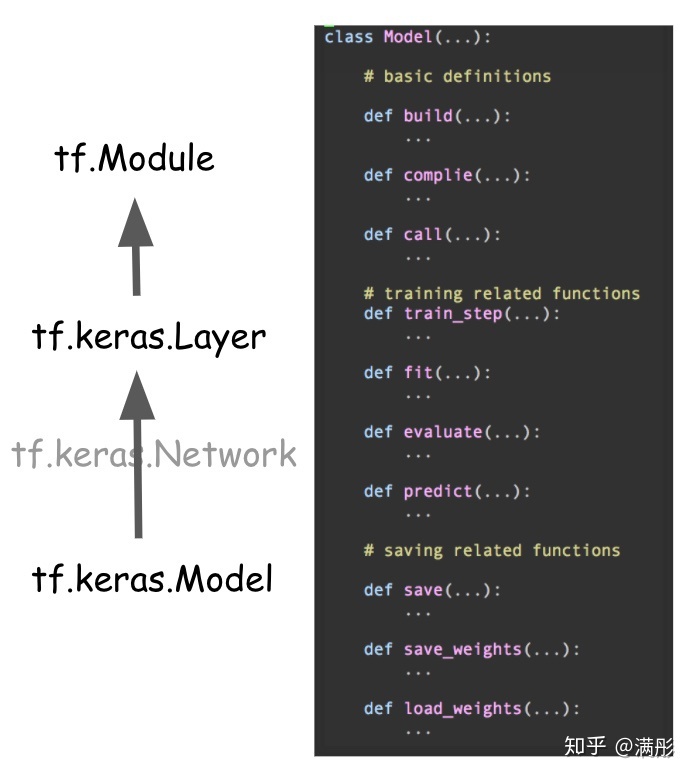
在 TF 2 里,模型可以有三种方式来进行搭建,Sequential API / Funtional API / Subclassing。无论哪种情况,我们构造出来的模型都拥有图 2中的结构。
从类的继承关系来讲,Model 继承于 Layer,Layer 继承于 Module。Module 可以看做是最基本的类,它可以设置变量 (tf.Variable) 为它的 attribute,还可以将可调用的 function (例如前向计算函数)设置为它的方法。所以我们可以把 Module 可以看做能够进行图计算的最小单元。
Model 在 Module 之上添加了更多的方法从而方便我们进行推断,训练和保存。如图 2 右侧所示。大致上来说,这些方法可以分为三类:第一类用来构造模型,编译模型和调用模型;第二类用来训练模型;第三类是和保存载入相关的。
在 TF 2.3 之前,Model 和 Layer 之间还有一层 Network Class。和模型结构相关的方法都是在 Network 中实现,TF 2.3 去掉了这个中间层。
我们可以看到,模型的实现方式在 TF 1 和 TF 2 里是很不一样的。自然的,模型的保存方式也是有差别的。
从词典到对象图 - 当我们保存 checkpoint 时我们在保存什么
前面我们说过,保存模型第一种方法是 checkpoint,也就是只保存模型的参数。
TF 1 里,由于我们直接和计算图以及变量打交道,所以我们保存的 checkpoint 就像是一个词典 (dictionary),里面保存了每个变量和值的对应关系,词典里变量的名字就是我们生成变量时指定的名字,所见即所得。
def 如上例子所示( TF1.14 环境下运行),我们生成一个两层的分类网络,然后保存为 checkpoint 文件。我们来看看 checkpoint 文件里有什么。
ckpt 我们在屏幕上看到如下输出:
var name: W1, shape: [32, 64]
var name: W2, shape: [64, 10]
var name: b1, shape: [64]
var name: b2, shape: [10]我们可以看到,checkpoint 里变量的名字和初始化变量时候的名字完全一致。这样看上去是一个很好的表示方式,所见即所得。可是这样有什么问题吗?
TF 1 之所以可以这样存储变量,因为在 TF 1 里,我们只有一个默认的计算图。所有的变量都是和这个图相关的全局变量。虽然我们可以通过 name_scope 来控制变量的命名空间和复用,但变量始终都是属于一个图的。这种非模块化的设计,让模型很难被复用。
TF 2 采用了一种模块化的设计。上一节我们提到,TF 2 里的模型是一个 Model 对象,相关的变量是 Model 对象的 attribute。 和 TF 1 不一样的是,在 TF 2 中,在存储变量的时候,我们会生成一张对象图 (object graph),存储和读入参数的时候,我们会从这个对象图的根节点出发,遍历整张图来完成匹配。
def 我们依然通过一个例子来看发生了什么,如上所示,我们通过 functional API 的方式构造一个模型,并保存其变量到一个 checkpoint 文件中。首先我们看一下模型里面参数的名字:
for 我们得到如下输出:
l1/kernel:0
l1/bias:0
l2/kernel:0
l2/bias:0在两个 dense 层我们分别生成了对应的 kernel 变量和 bias 变量,变量的名字和我们在生成模型时指定的名字是一致的。接下来我们来看一些 checkpoint 里存储的变量,我们依然采用 tf.train.list_variables(...) 来打印出变量名:
var name: _CHECKPOINTABLE_OBJECT_GRAPH, shape: []
var name: layer_with_weights-0/bias/.ATTRIBUTES/VARIABLE_VALUE, shape: [64]
var name: layer_with_weights-0/kernel/.ATTRIBUTES/VARIABLE_VALUE, shape: [32, 64]
var name: layer_with_weights-1/bias/.ATTRIBUTES/VARIABLE_VALUE, shape: [10]
var name: layer_with_weights-1/kernel/.ATTRIBUTES/VARIABLE_VALUE, shape: [64, 10]有意思的事情就发生了。我们可以看到 checkpoint 里保存的变量和模型里的变量的名字不一致!原因是,TF 2 在保存模型的 checkpoint 时,不再是按照模型里变量的名字来保存,而是首先将模型里所有的对象 (object) 组织成一个对象图(具体来说是一个有向图,根据模型内变量的生成顺序依次添加节点),然后存储该对象图相关的变量节点。图3是上面例子中对象图的结构。
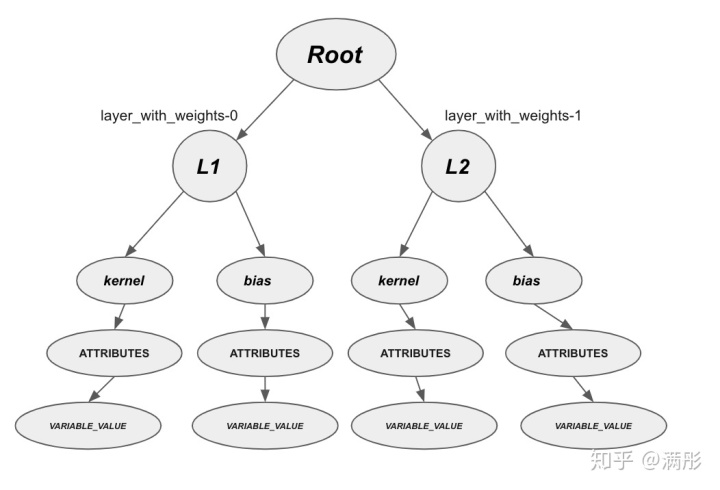
这样做的好处是,变量不再是名字唯一的一个全局变量,而是与模型的对象图相关的一个局部变量。这种设定使得模型的复用变得很容易,因为只要模型的结构没有变化,无论变量的全局名字如何变化 (例如分布式训练将模型拷贝到不同的设备上变量的全局名称会发生变化),模型的对象图始终是不变的。只要我们用相同的代码初始化 Model,我们永远都可以导入之前保存的 checkpoint。
从 Session 到 Function - 当我们在保存 SavedModel 时我们在保存什么
为什么需要 SavedModel?
模型的训练环境与实际生产环境往往是不同的。比如说,训练时我们往往使用 python 语言,而实际部署环境中可能根本就没有 python 环境。SavedModel 的出发点就是用一种与编程语言还有计算平台无关的一种方式来表示模型。从而我们能够方便的进行模型分发,模型部署。
实际应用中 HDF5 也是一种常见的存储类型,它和 SavedModel 的主要区别在于它直接存储模型的配置文件 configs 而非计算图,但本质上来说,它们的目的都是一样的:将模型进行序列化(serialization)。
SavedModel 是什么?
抽象的说,SavedModel 是一个完整的 TF 程序,它包含进行模型推断的所有信息,如计算图结构,所有相关的参数变量等。
技术上理解,SavedModel = Graphs + Checkpoints。
其中第一部分是由 Protocol buffers 定义的与模型相关的计算图,第二部分是完成计算所需要的相关的参数变量,也就是上一节提到的 checkpoint。
Protocol Buffer 是一种编程语言平台无关的序列化工具。类似于 XML。它可以用来将对象序列化,从而方便在不同的软硬件平台下迁移。 https:// developers.google.com/p rotocol-buffers
无论是 TF 1 还是 TF 2 导出的 SavedModel,文件结构都是一样的。一个典型的结构如下:
saved_model.pb
variables
--variables.index
--variables.data-00000-of-00001即使看上去一样,TF 1 和 TF 2 的 SavedModel 内部还是有区别的。其中最重要的一点我们在上一节已经有提到。TF 2 里读入 checkpoint 时我们需要模型的对象图,所以 TF 2 的 proto buffers 里不仅有计算图,还有对象图。
TF 1 生成的 SavedModel,TF 2 也可以载入。TF 2 的 load API 在读入 SavedModel 时会检查 pb 文件的 graphs 里是否有对象图 (object_graph_def),如果有就会采用 TF 2 的方式读入 SavedModel,如果没有就会还是采用旧的方式(load_v1_in_v2)。具体可参考此处: https:// github.com/tensorflow/t ensorflow/blob/885a34acbf0e67dd19aa9ad1c446e952bf066c20/tensorflow/python/saved_model/load.py#L658
需要注意的是,在 TF 2中,除了一般意义上的 SavedModel ,还有 Keras SavedModel 。Keras SavedModel 中除了基本计算图,对象图,参数之外,还有与 Keras 相关的一些实现。我们需要使用 Keras 对应的 API 来存储和读取才能实现全部的功能。具体请参考: https://www. tensorflow.org/guide/ke ras/save_and_serialize
殊途如何同归?
我们已经知道了 SavedModel 主要由两部分组成,一部分是计算图,一部分是 checkpoint。TF 1 里,我们直接和计算图打交道,每个 Session 有一个相关的默认计算图,我们能够直接存储。
但是 TF 2 里,我们并不和计算图接触,而是直接对 Model 对象操作,那我们是如何将计算图存入进 SavedModel 的呢?
这个时候,TF 2 的一个非常重要的特性,tf.function 就要登场了。
每个 Model 对象中都有一个或者多个可调用的函数,例如最基本的前向传播函数 call 。每个函数都定义了一个计算过程。tf.function 的作用就是,从可调用的函数中跟踪 (trace)出计算图。我们先看下面的这个例子:
@tf.function
这是 tf.function 的使用方式。可以看到操作很简单,就是给我们用 python 定义好的函数加一个装饰器。那么到底发生了什么呢?
def 运行以上代码我们可以得到如下输出:
<function my_function at 0x7f1c69d2fa70>
<tensorflow.python.eager.def_function.Function object at 0x7f1c69d6ef10>我们可以看到,tf.function 将一个 python 函数转变为了一个 Function 对象。这个时候我们需要引入一个新的概念,ConcerteFunction。Function 对象通过 ConcerteFunction 来和底层的计算图进行交互。
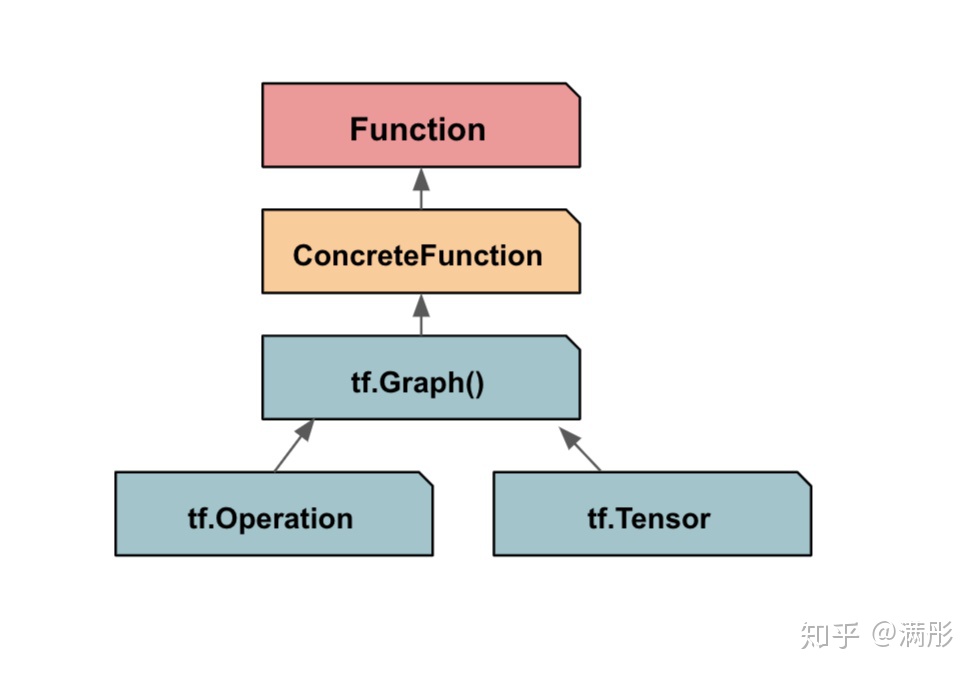
图 4 表示了 Function / ConcreteFunction / Graph 之间的结构关系。计算图是底层的计算单元,ConcreteFunction 是在计算图上的一个封装。每一个计算图对应于一个 ConcreteFunction。每一个 Function 对象中可以有一个或者多个 ConcreteFunction。通过调用不同的 ConcreteFunction,Function 对象可以调用不同的计算图。
ConcreteFunction 可以通过 Function 对象来生成,一般来说有两种方式,一种是被动式的生成方式,Function 对象会管理一个存储 ConcreteFunction 的 Cache,每次调用 Function 对象时,会先从 Cache 里查找是否有符合输入类型的计算图,如果有就直接调用,如果没有就生成相应的 ConcreteFunction 并存进 Cache,如下所示:
@tf.function
我们可以得到如下的输出:
concrete_functions: []
concrete_functions: [<tensorflow.python.eager.function.ConcreteFunction object at 0x7f7a0c404d10>]
concrete_functions: [<tensorflow.python.eager.function.ConcreteFunction object at 0x7f7a0c404d10>, <tensorflow.python.eager.function.ConcreteFunction object at 0x7f7a0c3962d0>]
concrete_functions: [<tensorflow.python.eager.function.ConcreteFunction object at 0x7f7a0c404d10>, <tensorflow.python.eager.function.ConcreteFunction object at 0x7f7a0c3962d0>]可以看到,一开始我们没有任何 ConcreteFunction,第一次调用 Function 输入两个整数型的 Tensor 时,我们会生成一个 ConcreteFunction;第二次调用输入两个浮点型的 Tensor 时,我们会添加一个新的 ConcreteFunction;第三次我们再次输入两个整数型 Tensor,由于 Cache 里已经有了相关 ConcreteFunction,我们不会再添加新的,而是直接调用以前的 ConcreteFunction。
这段代码是在 TF 2.2 环境下执行的,如果 TF 2.3 请调用 _list_all_concrete_functions 函数来打印所有的 ConcreteFunctions。
第二种是主动的生成方式,我们通过添加 input_signature 指定输入的类型和形状,直接生成对应的 ConcreteFunction,这种在实际中更常用。
@tf.function输出:
concrete_functions: [<tensorflow.python.eager.function.ConcreteFunction object at 0x7f128c00ed50>]自此,我们终于可以回答标题里的问题了。
当我们保存模型的时候我们在保存什么?
一般来说,保存模型有两种情况,一种是保存模型的参数变量,一种是保存整个模型:
- 保存变量时我们最常使用的是 checkpoint ,checkpoint 文件本质是一个变量名-变量值的词典,词典的 Key 在 TF 1 中是变量初始化的名字,在 TF 2 中是和模型对象图相关的名字;
- 保存模型时我们常用的是 SavedModel 格式,SavedModel 主要由两部分组成,模型相关的计算图,以及模型的变量词典(checkpoint)。TF 2 中,我们无法直接存储计算图,模型会通过 tf.function 方法,从 python 定义的函数中抽取出计算图然后进行保存。
总结
- TF 1 里的训练模型是计算图,TF 2 里的训练模型是 Model 对象;
- 保存模型时我们可以选择单独保存变量 (Checkpoint),或是保存整个模型(SavedModel);
- 保存 Checkpoint 时,我们是在保存与模型相关的变量值,保存完成后,加载 Checkpoint 需要我们重新构建模型;
- SavedModel 能够保存一个独立的不依赖原始代码,直接调用 TF 引擎进行推断的模型;
- 虽然保存的文件结构相似,但 TF1 和 TF2 保存的机制是很不相同的。
参考文献:
- TF 官方文档
- Inside Tensorflow, functions not sessions
---------------------------------------------------------------------------------
谢谢你的阅读。下一次我会谈一谈分布式训练,从最常见的例子出发,具体来看一看 TF 是怎么实现 MirroredStrategy 从而在多个 GPU 上进行数据并行训练的。















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









