







法一:运用open()函数
该方法使用最基本的open函数进行读取,此处将会把数据读取到一个列表中,这个方法一般就是open打开文件、read读取文件、close关闭文件3个步骤,主要代码如下:
f = open(文件路径,读模式)
f.read() #将文件中的内容以字符串的形式输出
f.readline() #读取一行内容;
f.readlines() #读取所有行,以列表的方式返回;
f.close() #关闭输入流
with open(文件路径,读模式) as f:
f.read() #readline()、readlines()
tmp_list =字符串.split(',') #按‘,'切分每行的数据
tmp_list[-1] = tmp_list[-1].replace('\n',',') #去掉换行符
f.read() 和f.readlines() 后再读就=' ',因为一次全流完了。 f.readline()则可以逐行读完为止。
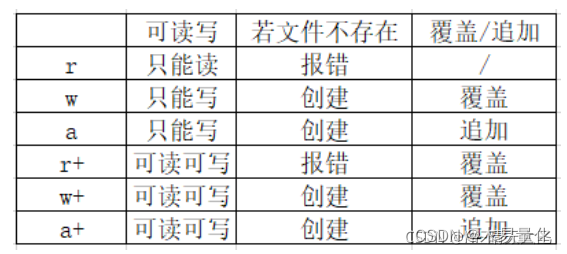
方法二:使用numpy包的loadtxt方法
这里要求的数据必须是数字,不能是字母等字符,不然会报错,因为numpy本身是做计算的,所以读取的数据已经转化为数值类型,非字符串,这种方法在处理实验数据中经常会用到,简单快捷)
import numpy as np
data = np.loadtxt(filename,dtype=np.float32,delimiter=',')方法三:使用pandas的read_table方法进行读取
pandas提供了现成的读取各种文件的方法,像csv/txt文件的read_csv方法,excel文件的read_excel方法等,(这里不必要是数值的数据,且不需要先打开文件指令,data是PD类型)︰
data = pd.read_csv(r"c:/aaa.txt", header=None, sep=' ') #读取TXT:空格分隔,默认是‘,’
data.to_csv("c:/bbb.txt",sep=',',header=False,index=False) #将PD类型data保存到bbb文件Pandas 写入读出EXCEL
data = {'名字': ['张三','李四'],
'分数': [100, 100]
}
a= pandas.DataFrame(data)
a.to_excel('1.xlsx', sheet_name='Sheet1',index=False)# index = False表示不写入索引
data= pandas.read_excel("t.xlsx", 'Sheet1')
data= pandas.read_excel("t.xlsx", ['Sheet1', 'Sheet2'])














 5570
5570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









