







 本文探讨了对抗攻击防御的三个主要方向:改训练过程/输入数据、修改网络以及使用附加网络。具体包括蛮力对抗训练、数据压缩、深度压缩网络等训练策略,梯度正则化、Defensive distillation等网络改进方法,以及防御通用扰动、基于GAN的防御等附加网络应用。这些策略旨在提升AI模型的鲁棒性和安全性。
本文探讨了对抗攻击防御的三个主要方向:改训练过程/输入数据、修改网络以及使用附加网络。具体包括蛮力对抗训练、数据压缩、深度压缩网络等训练策略,梯度正则化、Defensive distillation等网络改进方法,以及防御通用扰动、基于GAN的防御等附加网络应用。这些策略旨在提升AI模型的鲁棒性和安全性。
目前,在对抗攻击防御上存在三个主要方向:
1)在学习过程中修改训练过程或者修改的输入样本。
2)修改网络,比如:添加更多层/子网络、改变损失/激活函数等。
3)当分类未见过的样本时,用外部模型作为附加网络。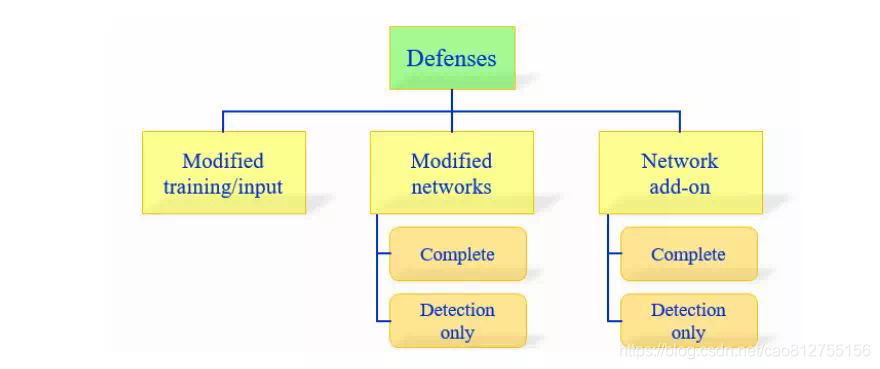
1.改训练过程/ 输入数据
1 蛮力对抗训练
通过不断输入新类型的对抗样本并执行对抗训练,从而不断提升网络的鲁棒性。为了保证有效性,该方法需要使用高强度的对抗样本,并且网络架构要有充足的表达能力。这种方法需要大量的训练数据,因而被称为蛮力对抗训练。很多文献中提到这种蛮力的对抗训练可以正则化网络以减少过拟合 [23,90]。然而,Moosavi-Dezfooli[16] 指出,无论添加多少对抗样本,都存在新的对抗攻击样本可以再次欺骗网络。
2 数据压缩
注意到大多数训练图像都是 JPG 格式,Dziugaite[123] 等人使用 JPG 图像压缩的方法,减少对抗扰动对准确率的影响。实验证明该方法对部分对抗攻击算法有效,但通常仅采用压缩方法是远远不够的,并且压缩图像时同时也会降低正常分类的准确率,后来提出的 PCA 压缩方法也有同样的缺点。
3 基于中央凹机制的防御
Luo[119] 等人提出用中央凹(foveation)机制可以防御 L-BFGS 和 FGSM 生成的对抗扰动,其假设是图像分布对于转换变动是鲁棒的,而
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









