







ROWNUMBER() OVER( PARTITION BY COL1 ORDER BY COL2)用法
今天在使用多字段去重时,由于某些字段有多种可能性,只需根据部分字段进行去重,在网上看到了rownumber()
over
(
partition
by
col1
order
by
col2)去重的方法,很不错,在此记录分享下:
row_number() OVER ( PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪列rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码.
row_number() OVER ( PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪列rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码.
- row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序).
- rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内).
- dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的.
- lag(arg1,arg2,arg3):
-
- arg1是从其他行返回的表达式
- arg2是希望检索的当前行分区的偏移量。是一个正的偏移量,是一个往回检索以前的行的数目。
- arg3是在arg2表示的数目超出了分组的范围时返回的值。
函数语法:
OPAP函数语法四部分:
1.function 本身用于对窗口中的数据进行操作;
2.partitioning clause 用于将结果集分区;
3.order by clause 用于对分区中的数据进行排序;
4.windowing clause 用于定义function在其上操作的行的集合,即function所影响的范围;
RANK()
dense_rank()
【语法】RANK ( ) OVER ( [query_partition_clause] order_by_clause )
dense_RANK ( ) OVER ( [query_partition_clause] order_by_clause )
【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
【参数】dense_rank与rank()用法相当,
【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
【说明】Oracle分析函数
ROW_NUMBER() 【语法】ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2) 【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的) row_number() 返回的主要是“行”的信息,并没有排名 【参数】 【说明】Oracle分析函数 主要功能:用于取前几名,或者最后几名等
sum(...) over ... 【功能】连续求和分析函数 【参数】具体参示例 【说明】Oracle分析函数
lag()和lead() 【语法】 lag(EXPR,<OFFSET>,<DEFAULT>) OVER ( [query_partition_clause] order_by_clause ) LEAD(EXPR,<OFFSET>,<DEFAULT>) OVER ( [query_partition_clause] order_by_clause ) 【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的) lead () 下一个值 lag() 上一个值 【参数】 EXPR是从其他行返回的表达式 OFFSET是缺省为1 的正数,表示相对行数。希望检索的当前行分区的偏移量 DEFAULT是在OFFSET表示的数目超出了分组的范围时返回的值。 【说明】Oracle分析函数
---TEST FOR ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)
DROP
TABLE
TEST_Y
CREATE
TABLE
TEST_Y(
ID
VARCHAR2
(
32
)
PRIMARY
KEY
,
NAME
VARCHAR2
(
20
),
AGE
NUMBER
(
3
),
DETAILS
VARCHAR2
(
1000
)
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'海子'
,
20
,
'面朝大海,春暖花开'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'海子'
,
30
,
'面朝大海,春暖花开'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'贝多芬'
,
43
,
'致爱丽丝'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'普希金'
,
34
,
'假如生活欺骗了你'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'杨过'
,
23
,
'黯然销魂掌'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'小龙女'
,
32
,
'神雕侠侣'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'李清照'
,
21
,
'寻寻觅觅、冷冷清清'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'周芷若'
,
18
,
'峨眉'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'赵敏'
,
18
,
'自由'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'张无忌'
,
20
,
'倚天屠龙记'
);
INSERT
INTO
TEST_Y
VALUES
(SYS_GUID(),
'张无忌'
,
30
,
'倚天屠龙记'
);
SELECT
*
FROM
TEST_Y;
----1. ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)
---查询所有姓名,如果同名,则按年龄降序
SELECT
NAME
,AGE,
DETAILS
,ROW_NUMBER()
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
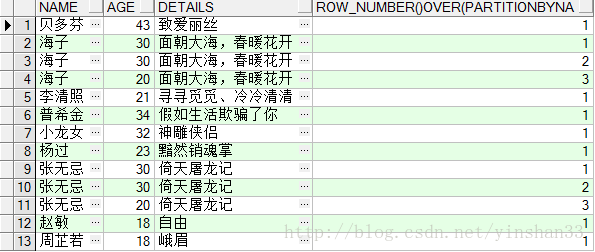
----通过上面的语句可知,ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)中是按照NAME字段分组,按AGE字段排序的。
----如果只需查询出不重复的姓名即可,则可使用如下的语句
SELECT
*
FROM
(
SELECT
NAME
,AGE,
DETAILS
,ROW_NUMBER()
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)RN
FROM
TEST_Y )
WHERE
RN=
1
;
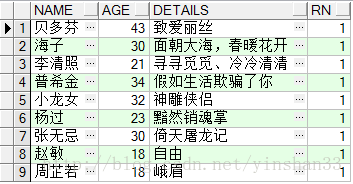
----由查询结果可知,姓名相同年龄小的数据被过滤掉了;可以使用ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)对部分子弹进行去重处理
----2.RANK() OVER(PARTITION BY COL1 ORDER BY COL2)
----跳跃排序
SELECT
NAME
,AGE,
DETAILS
,
RANK
()
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
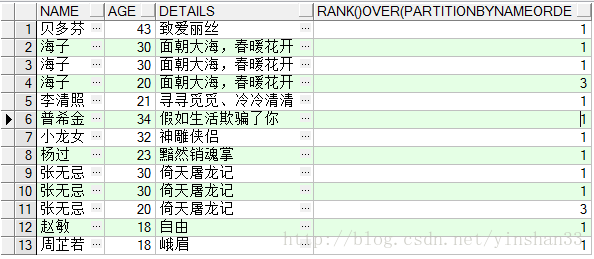
----由查询结果可知,相同的并列,下一个则跳跃到并列所替的序列后:如有两个并列1,那么下一个则直接排为3,跳过2;
----3.DENSE_RANK() OVER(PARTITION BY COL1 ORDER BY COL2)
----连续排序,当有多个并列时,下一个仍然连续有序

----由查询结果可知,当两个并列为1时,下一个仍连续有序为2,不跳跃到3
Lag和Lead函数可以在一次查询中取出同一字段的前N行的数据和后N行的值。这种操作可以使用对相同表的表连接来实现,不过使用LAG和LEAD有更高的效率.
Lag和Lead偏移量函数,其用途是:可以查出同一字段下一个值或上一个值,并作为新列存在表中.
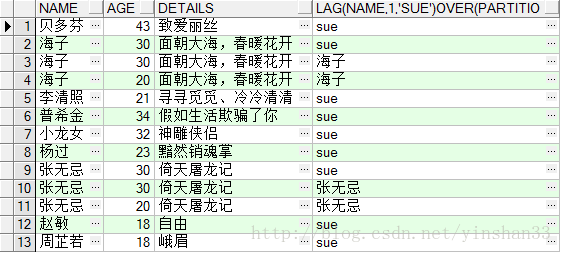
-----4.LAG(exp_str,offset,defval) OVER(PARTITION BY NAME ORDER BY AGE)
-----exp_str 返回显示的字段;offset是exp_str字段的偏移量,默认是1,如offset=1表示返回当前exp_str的下一个exp_str;defval当该函数无值可用的情况下返回该值。
(1) SELECT
NAME
,AGE,
DETAILS
,
LAG
(
NAME
,
1
,
'sue'
)
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
(2) SELECT
NAME
,AGE,
DETAILS
,
LAG
(
NAME
,
2
,
'sue'
)
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
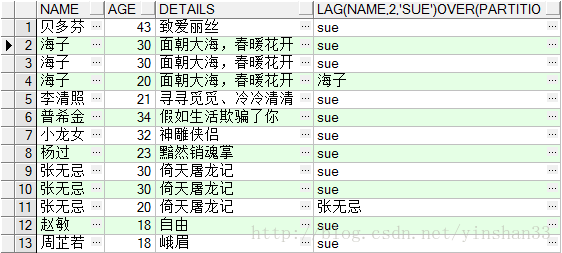
(3) SELECT
NAME
,AGE,
DETAILS
,
LAG
(
NAME
,
2
,
'sue'
)
OVER
(
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
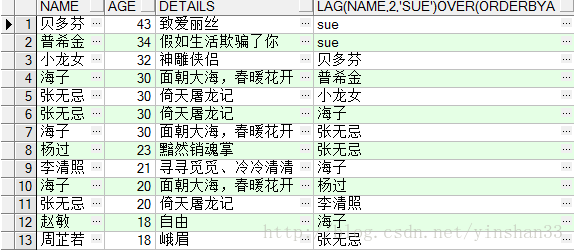
----5.LEAD(EXP_STR,OFFSET,DEFVAL) OVER(PARTITION BY NAME ORDER BY AGE)
-----exp_str 返回显示的字段;offset是exp_str字段的偏移量,默认是1,如offset=1表示返回当前exp_str的上一个exp_str;
-----defval当该函数无值可用的情况下返回该值。
(1)SELECT
NAME
,AGE,
DETAILS
,
LEAD
(
NAME
,
1
,
'sue'
)
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
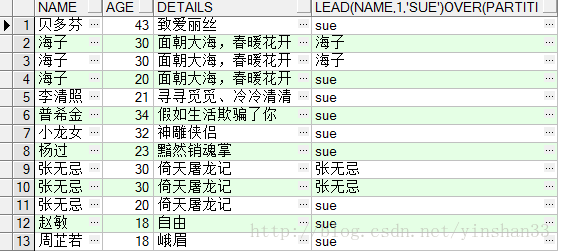
(2) SELECT
NAME
,AGE,
DETAILS
,
LEAD
(
NAME
,
2
,
'sue'
)
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
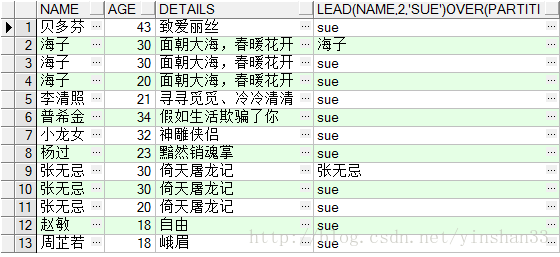
(3) SELECT
NAME
,AGE,
DETAILS
,
LEAD
(
NAME
,
1
,
'sue'
)
OVER
(
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
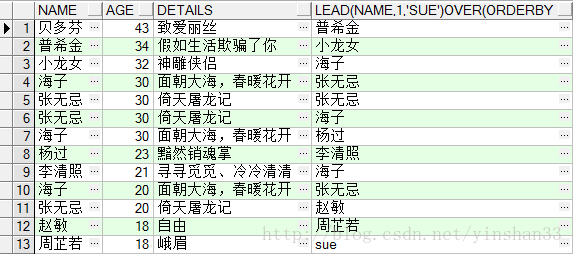
-----6.SUM(COL1) OVER([PARTITION BY COL2 ] [ORDER BY COL3])
(1) SELECT
NAME
,AGE,
DETAILS
,ROW_NUMBER()
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
),
SUM
(AGE)
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
)
FROM
TEST_Y;
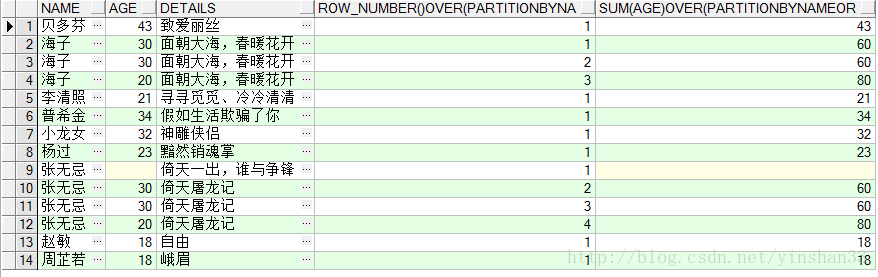
(2) SELECT
NAME
,AGE,
DETAILS
,ROW_NUMBER()
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
),
SUM
(AGE)
OVER
(
PARTITION
BY
NAME
)
FROM
TEST_Y;
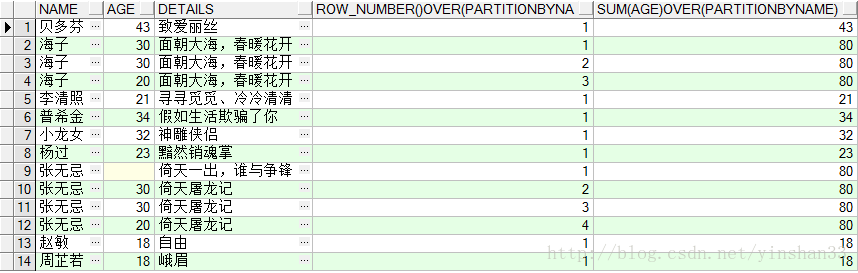
(3)
SELECT
NAME
,AGE,
DETAILS
,ROW_NUMBER()
OVER
(
PARTITION
BY
NAME
ORDER
BY
AGE
DESC
),
SUM
(AGE)
OVER
(
ORDER
BY
AGE
DESC
NULLS
LAST
)
FROM
TEST_Y;

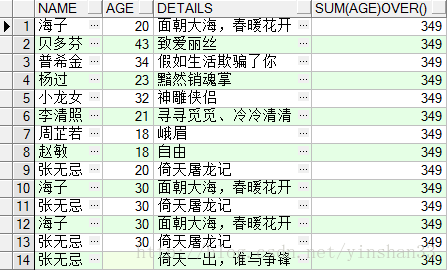
(4) SELECT
NAME
,AGE,
DETAILS
,
SUM
(AGE)
OVER
()
FROM
TEST_Y;















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









