







数据预处理——数据变换
数据类型的一致性处理方法
数据类型的一致性处理方法可以从多个角度考虑。首先,可以在数据库设计阶段使用约束来确保数据类型的一致性。这包括指定数据字段的数据类型和长度,以及设置非空约束、默认值约束和检查约束。通过这些约束,可以限制数据字段接受的数据类型和取值范围,从而保证数据类型的一致性。
此外,还可以在开发和部署阶段采取措施来确保数据类型的一致性。例如,可以使用数据转换工具或ETL工具来处理数据导入和导出的过程中的数据类型转换。这样可以确保将不同数据源中的数据正确地映射到目标数据库中,并保持数据类型的一致性。
另外,通过建立数据口径规范和统一的数据公共层,可以在使用阶段实现数据类型的一致性。这包括避免重复建设和指标冗余建设,确保数据口径的规范和统一。通过统一的数据输出和标准化的数据格式,可以保证数据类型的一致性,并提供具有一致性的数据指标。
综上所述,数据类型的一致性处理方法包括在数据库设计阶段使用约束、在开发和部署阶段使用数据转换工具和ETL工具进行数据类型转换,以及在使用阶段通过建立数据口径规范和统一的数据公共层来实现数据类型的一致性。这些方法可以确保数据类型的一致性,从而提高数据的质量和可靠性。

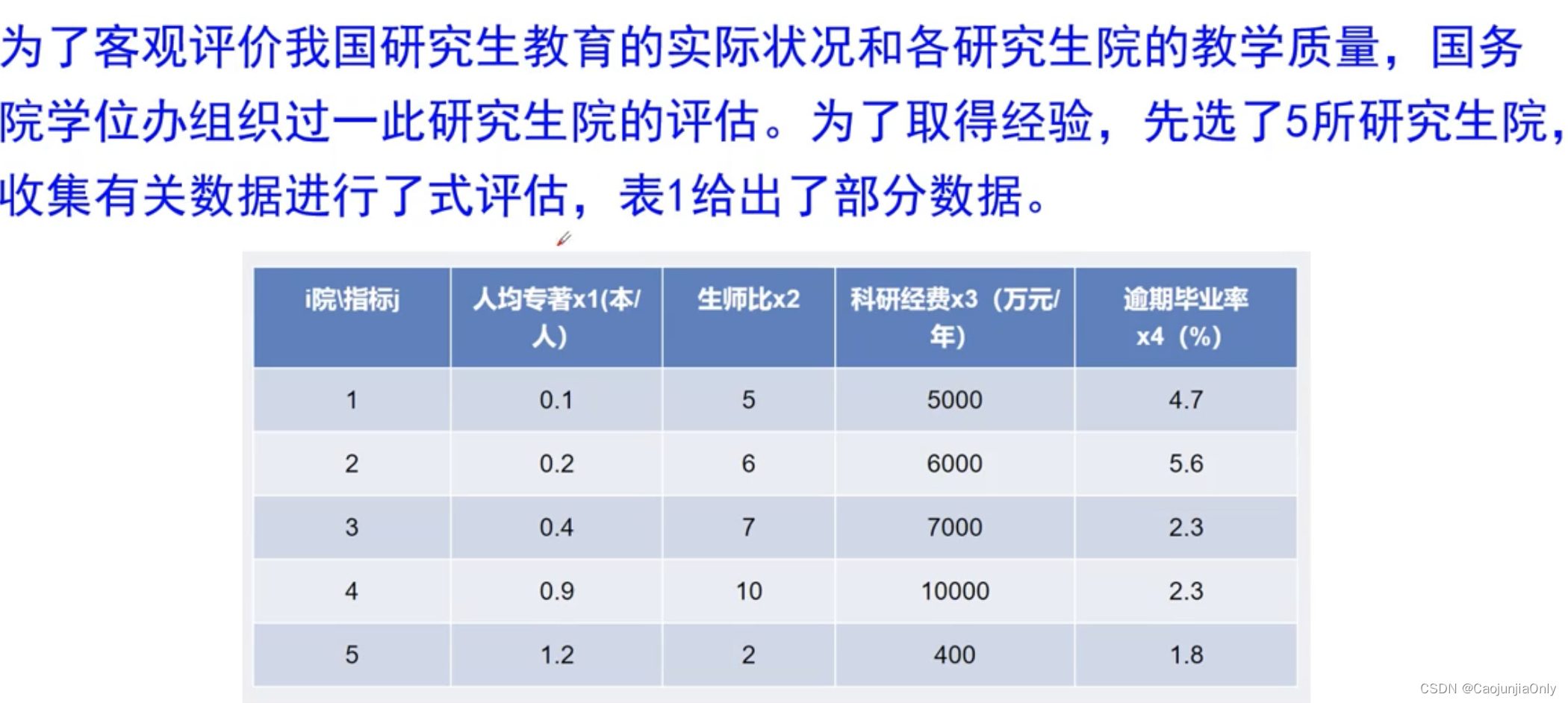


数据指标的无量纲化处理

数据指标的无量纲化处理是为了消除指标之间的量纲影响,以解决数据指标之间的可比性。一种常用的无量纲化处理方法是数据标准化。数据标准化的目标是使数据呈现出一种特征,即数据的平均值为0。具体来说,可以通过两种方式进行数据标准化处理。
第一种方式是Z-score标准化。在Z-score标准化中,首先计算数据集的平均值和标准差,然后对每个数据点进行如下变换:将数据点减去平均值,再除以标准差。这样处理后的数据集的平均值一定为0,标准差一定是1。
第二种方式是最小-最大标准化,也称为归一化。在最小-最大标准化中,首先找到数据集的最小值和最大值,然后对每个数据点进行如下变换:将数据点减去最小值,再除以最大值减最小值。这样处理后的数据集的取值范围一定在0到1之间,且不同数据点之间的比例关系得以保持。
综上所述,数据指标的无量纲化处理可以通过Z-score标准化或最小-最大标准化来实现,这样可以消除指标之间的量纲影响,使得数据具有可比性。



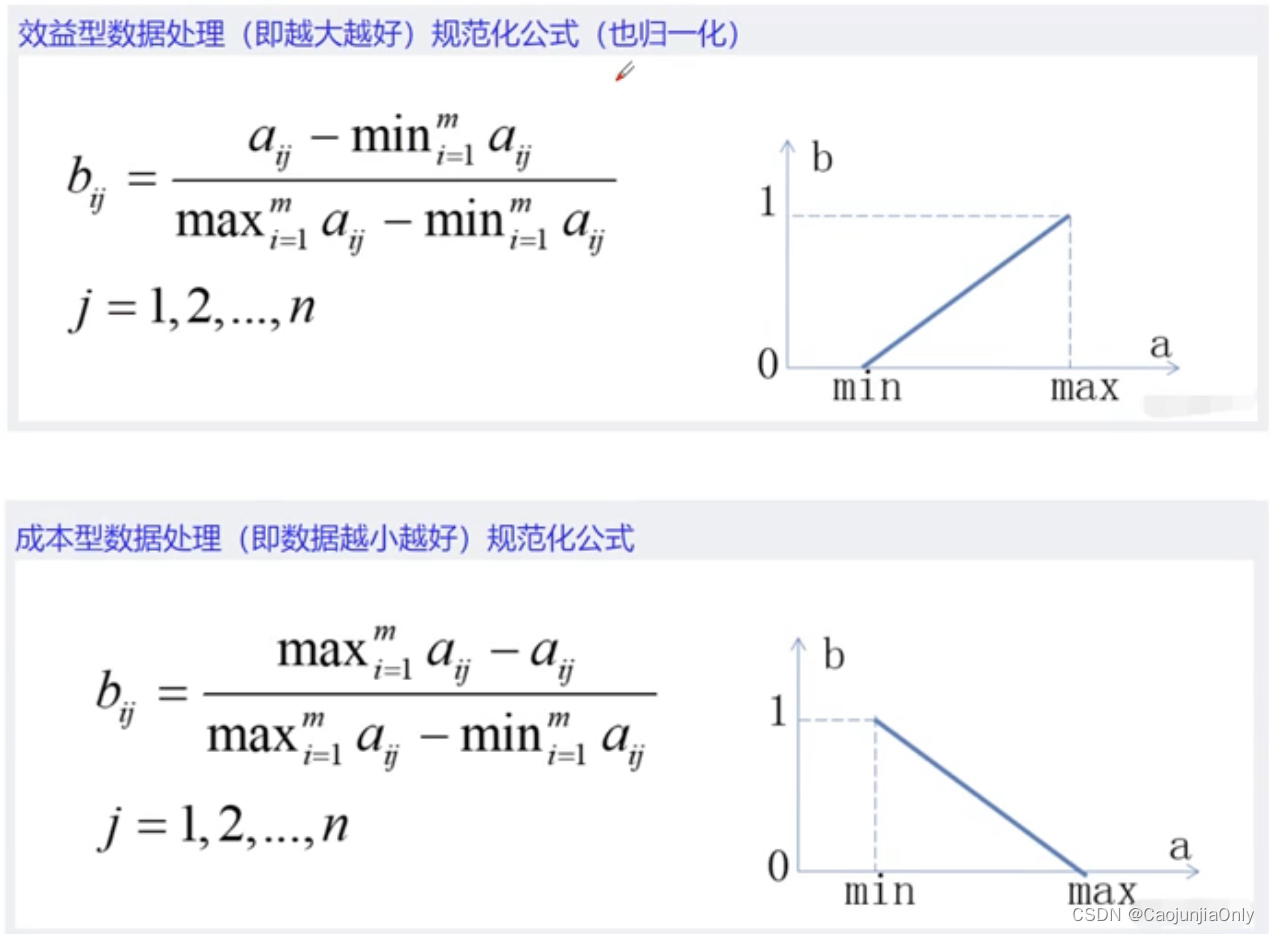
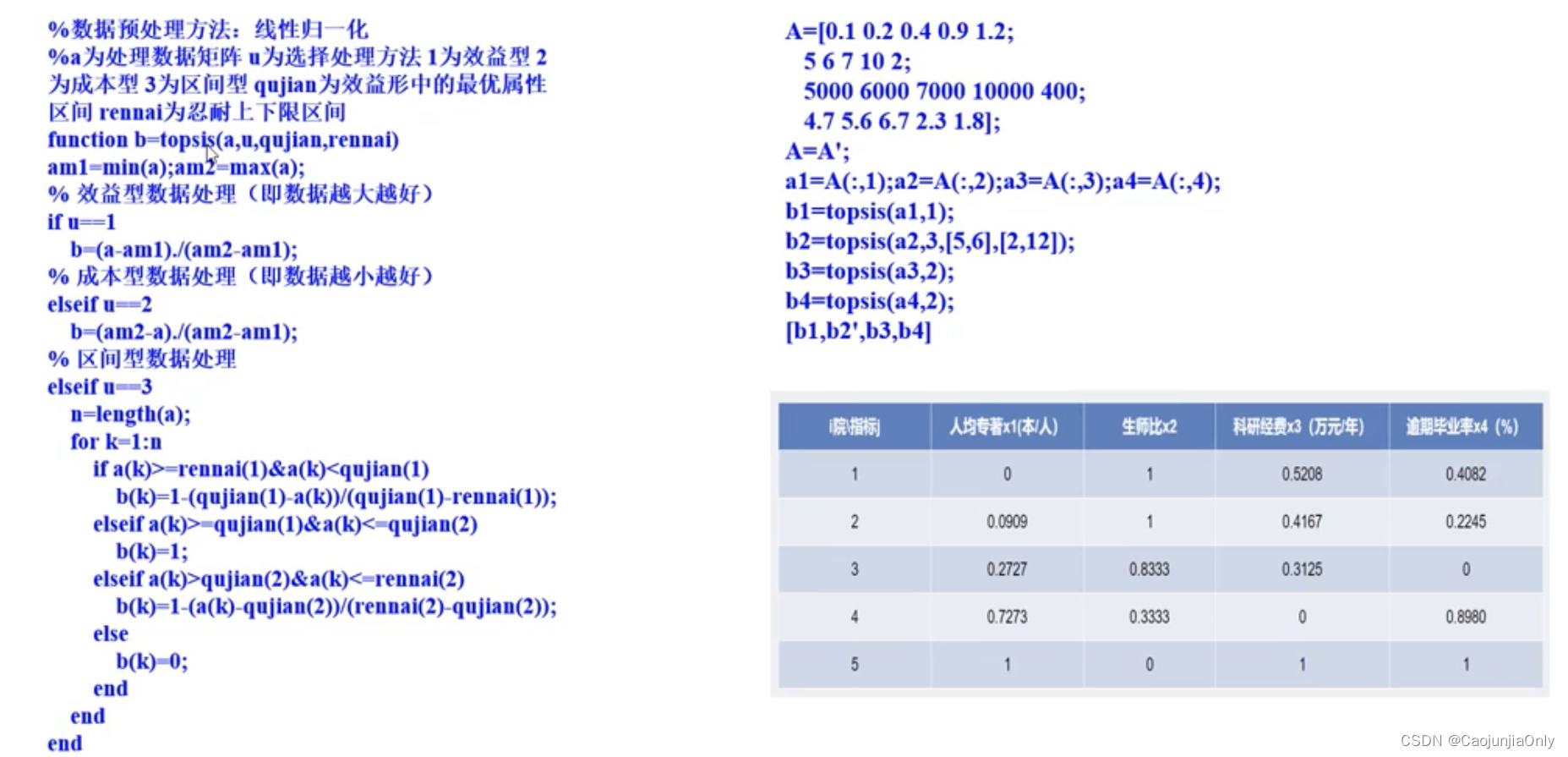
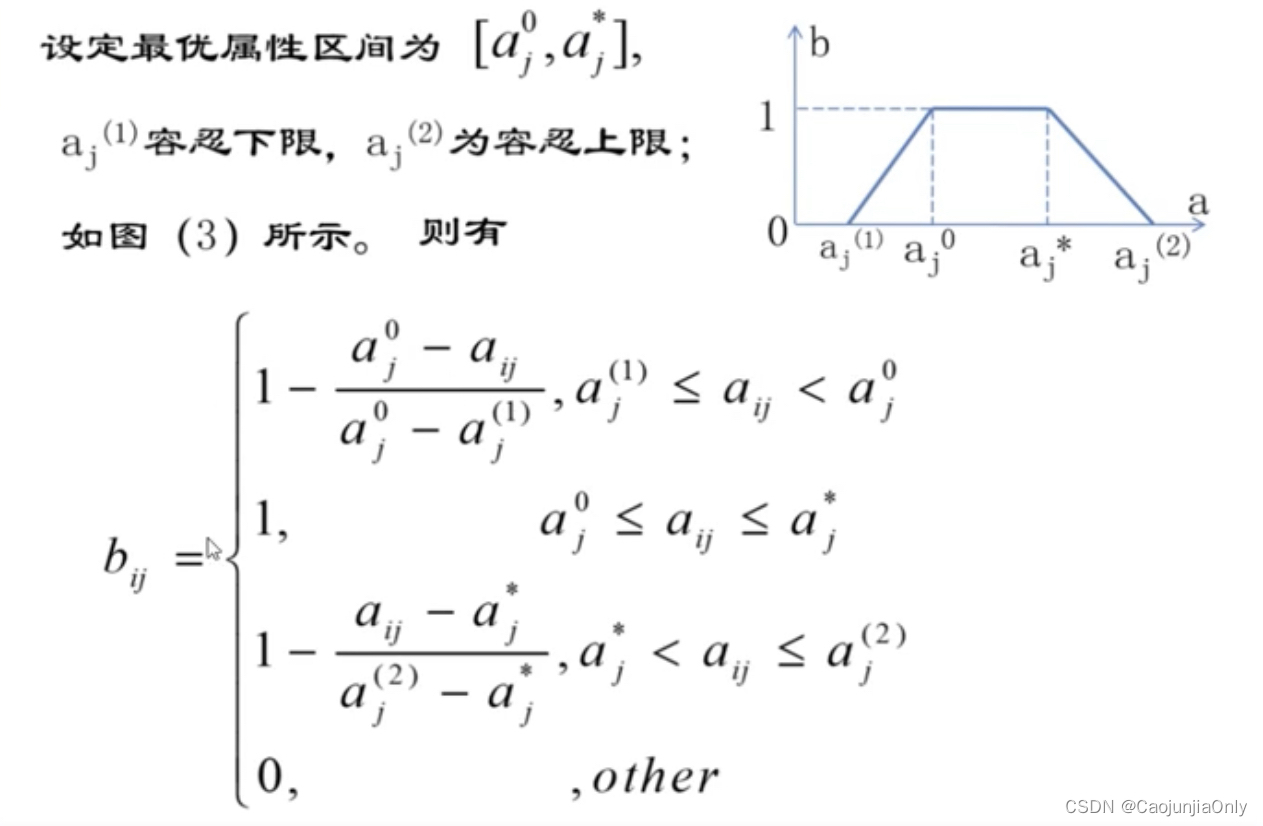
定性指标的量化处理方法


















 2089
2089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











