







 本文为Hive初学者详解hive、数据库、hdfs、yarn之间的关系。介绍了Hive整体架构,它可看作MapReduce客户端,数据存于HDFS,元数据用Derby或MySQL存储;对比了Derby和MySQL,指出生产中多用MySQL;还通过建库建表流程介绍了Hive工作流程。
本文为Hive初学者详解hive、数据库、hdfs、yarn之间的关系。介绍了Hive整体架构,它可看作MapReduce客户端,数据存于HDFS,元数据用Derby或MySQL存储;对比了Derby和MySQL,指出生产中多用MySQL;还通过建库建表流程介绍了Hive工作流程。
对于Hive的初学者,是否对hive、数据库,hdfs,yarn之间的关系有点搞不懂?这里将详解分析其中的关系。
1.Hive整体架构介绍
Hive可以看做是MapReduce的客户端
因为Hive的底层运算是MapReduce计算框架,Hive只是将可读性强,容易编程的SQL语句通过Hive软件转换成MR程序在集群上执行。hive可以看做mapreduce客户端,能用mapreduce程序完成的任务基本都可以对应的替换成hql(Hive SQL)编写的hive任务。所以因为hadoop和hdfs的本身设计的特点,也限制了hive所能胜任的工作特性。Hive最大的限制特点就是不支持基于行记录的更新,删除,增加。但是用户可以通过查询生成新表,或者将查询结果导入文件中来“实现”hive基于行记录的操作。
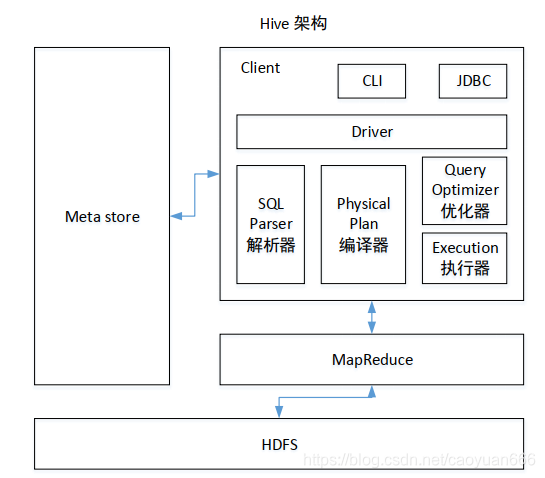
对于实际的数据,则存储在HDFS上。
那么左侧的meta store,则用于存储数据表的元数据信息(数据库,表格名,数据地址等等),这个需要一个数据表来实现,Derby或MySQL。
2.Derby&MySQL
Hive元数据默认保存在内嵌的 Derby 数据库中,但derby数据库只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,不可能只允许一个会话连接,需要支持多用户会话,通常部署的时候会将hive的元数据修改为保存在mysql中。
- Derby 只支持一个会话连接
- MySQL 支持多个会话连接,并且可以独立部署
3.Hive工作流程
这里通过建立数据库,建立表的流程例子,详细介绍了hive的工作流程。



















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











